

This is a fork repo of the official repo of TransferQueue. The official repo (with recent new features) are temporarily invisible starting from 2025-11-11, as we’re going through some company checks.
No need to worry—we will be back!
If you wish to use TransferQueue in the meantime, feel free to visit the PyPI page. The newest version can be found there.
TransferQueue is a high-performance data storage and transfer module with panoramic data visibility and streaming scheduling capabilities, optimized for efficient dataflow in post-training workflows.
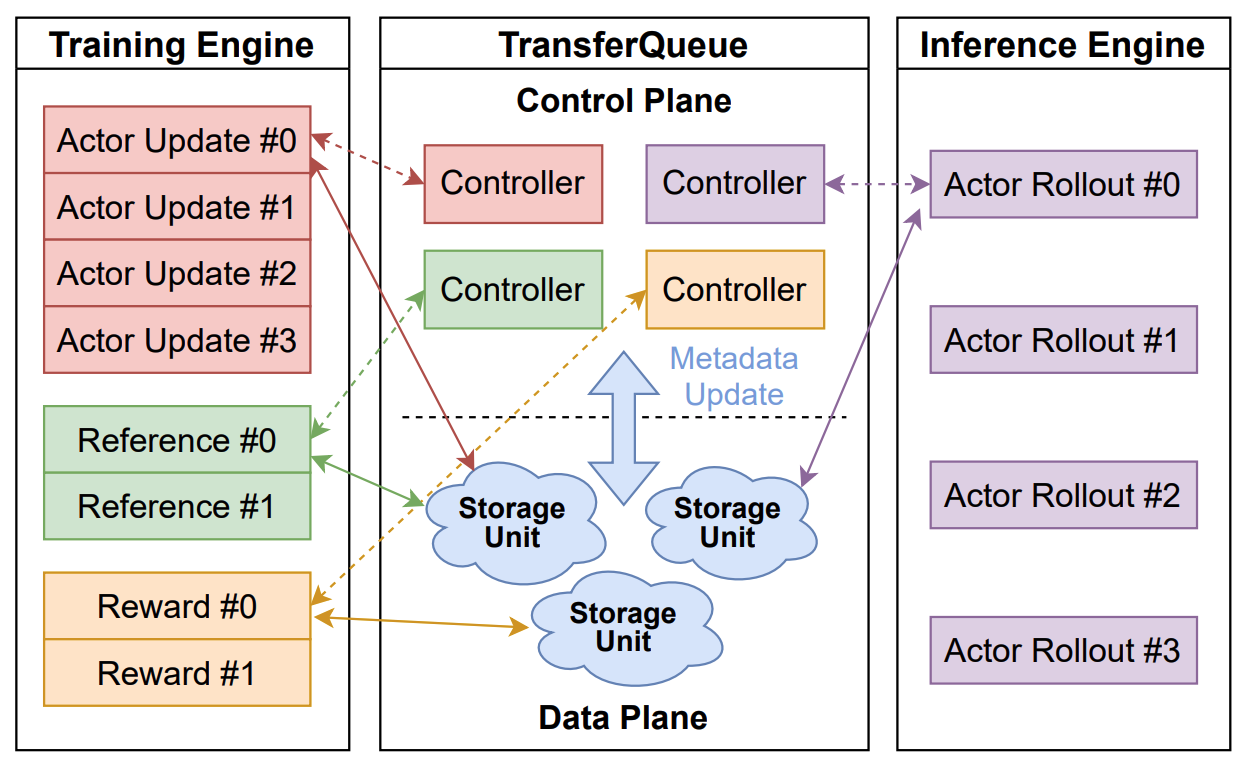
TransferQueue offers fine-grained, sample-level data management and load-balancing (on the way) capabilities, serving as a data gateway that decouples explicit data dependencies across computational tasks. This enables a divide-and-conquer approach, significantly simplifying the design of the algorithm controller.
- Oct 21, 2025: Official integration into verl is ready verl/pulls/3649. Following PRs will optimize the single controller architecture by fully decoupling data & control flows.
- July 22, 2025: We present a series of Chinese blogs on Zhihu 1, 2.
- July 21, 2025: We started an RFC on verl community verl/discussions/2662.
- July 2, 2025: We publish the paper AsyncFlow.
In the control plane, TransferQueueController tracks the production status and consumption status of each training sample as metadata. When all the required data fields are ready (i.e., written to the TransferQueueStorage), we know that this data sample can be consumed by downstream tasks.
For consumption status, we record the consumption records for each computational task (e.g., generate_sequences, compute_log_prob, etc.). Therefore, even when different computation tasks require the same data field, they can consume the data independently without interfering with each other.
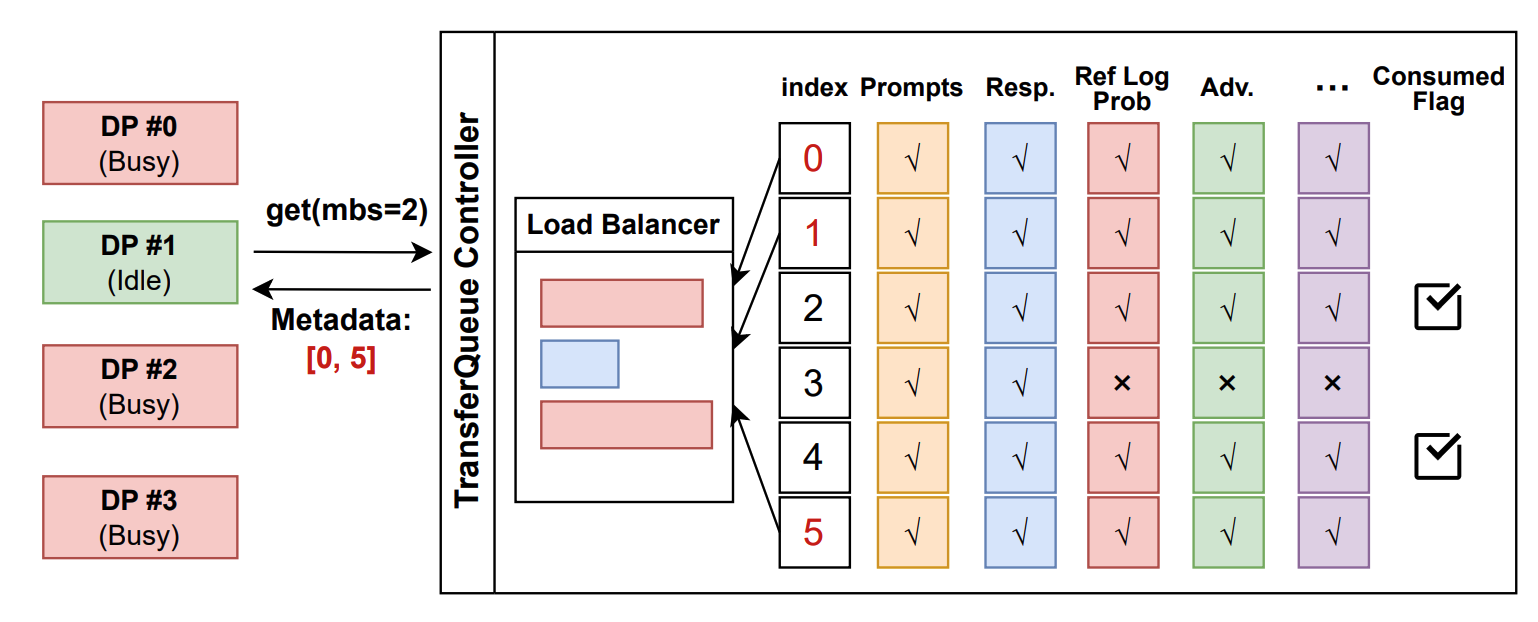
In the future, we plan to support load-balancing and dynamic batching capabilities in the control plane. Additionally, we will support data management for disaggregated frameworks where each rank manages the data retrieval by itself, rather than coordinated by a single controller.
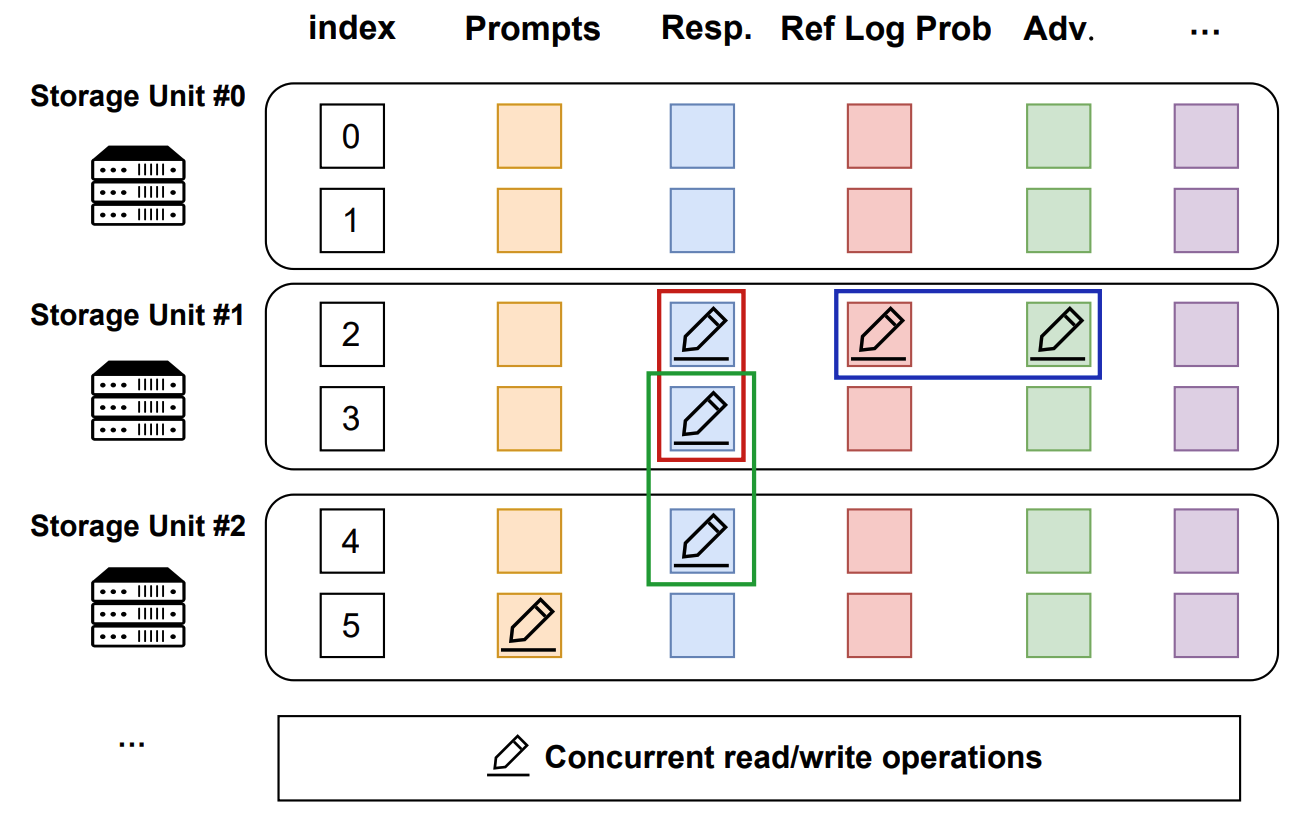
In the data plane, TransferQueueStorageSimpleUnit serves as a naive storage unit based on CPU memory, responsible for the actual storage and retrieval of data. Each storage unit can be deployed on a separate node, allowing for distributed data management.
TransferQueueStorageSimpleUnit employs a 2D data structure as follows:
- Each row corresponds to a training sample, assigned a unique index within the corresponding global batch.
- Each column represents the input/output data fields for computational tasks.
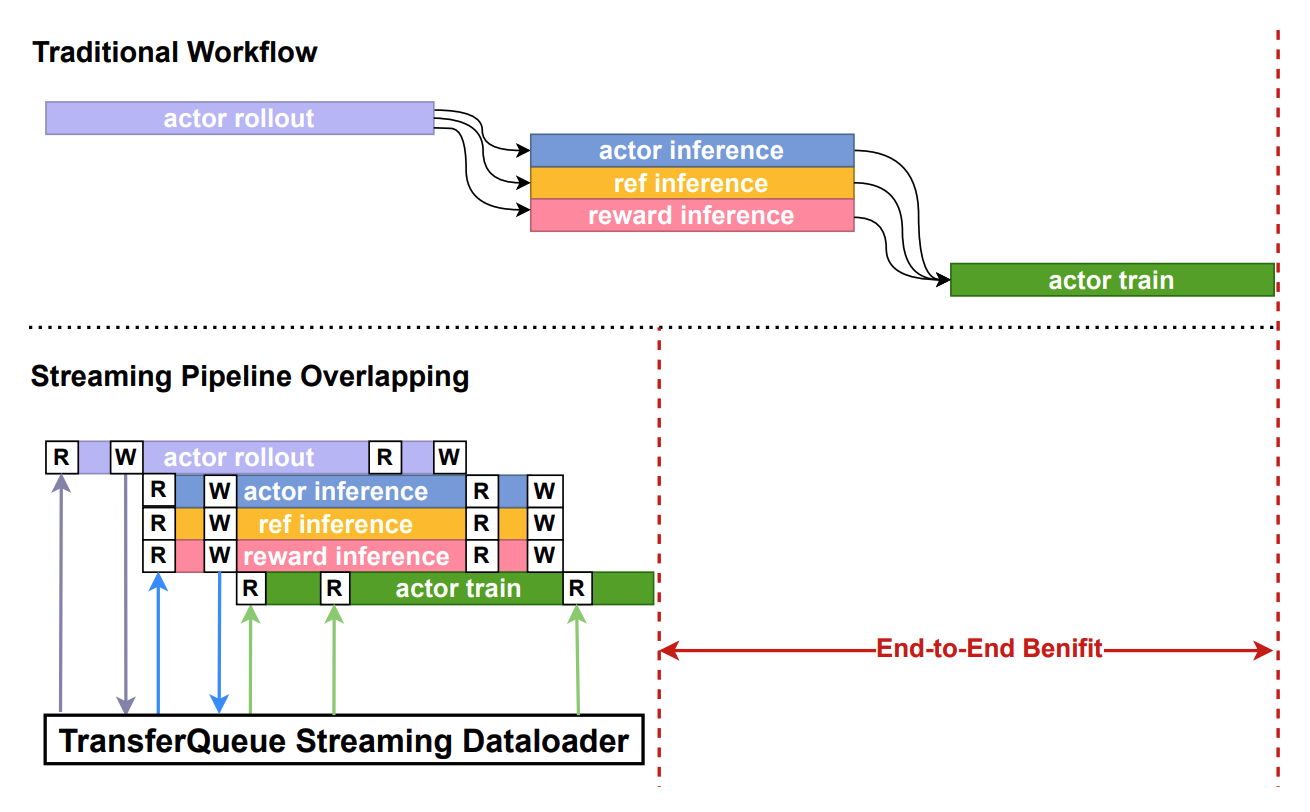
This data structure design is motivated by the computational characteristics of the post-training process, where each training sample is generated in a relayed manner across task pipelines. It provides an accurate addressing capability, which allows fine-grained, concurrent data read/write operations in a streaming manner.
In the future, we plan to implement a general storage abstraction layer to support various storage backends. Through this abstraction, we hope to integrate high-performance storage solutions such as MoonCakeStore to support device-to-device data transfer through RDMA, further enhancing data transfer efficiency for large-scale data.
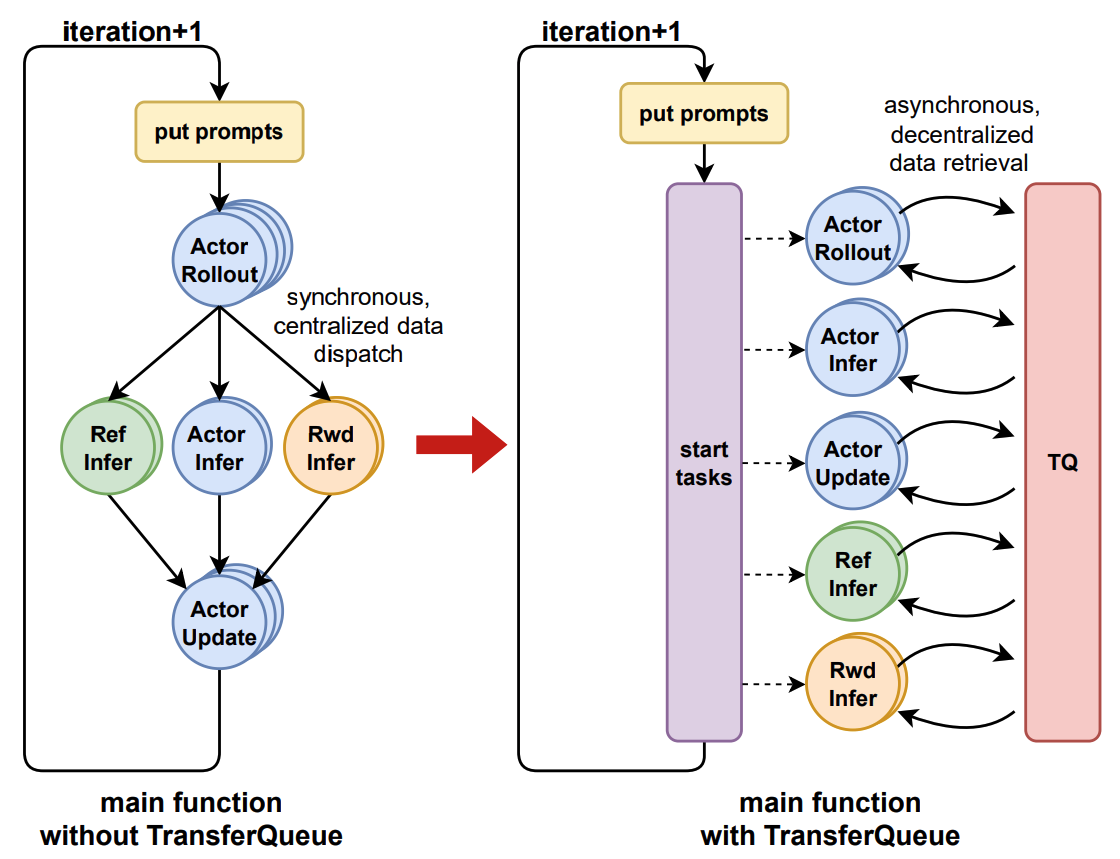
The interaction workflow of TransferQueue system is as follows:
- A process sends a read request to the
TransferQueueController. TransferQueueControllerscans the production and consumption metadata for each sample (row), and dynamically assembles a micro-batch metadata according to the load-balancing policy. This mechanism enables sample-level data scheduling.- The process retrieves the actual data from distributed storage units using the metadata provided by the controller.
To simplify the usage of TransferQueue, we have encapsulated this process into AsyncTransferQueueClient and TransferQueueClient. These clients provide both asynchronous and synchronous interfaces for data transfer, allowing users to easily integrate TransferQueue into their framework.
In the future, we will provide a
StreamingDataLoaderinterface for disaggregated frameworks as discussed in RFC#2662. Leveraging this abstraction, each rank can automatically get its own data likeDataLoaderin PyTorch. The TransferQueue system will handle the underlying data scheduling and transfer logic caused by different parallelism strategies, significantly simplifying the design of disaggregated frameworks.
The primary interaction points are AsyncTransferQueueClient and TransferQueueClient, serving as the communication interface with the TransferQueue system.
Core interfaces:
- (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta
- (async_)get_data(metadata:BatchMeta) -> TensorDict
- (async_)put(data:TensorDict, metadata:BatchMeta, global_step)
- (async_)clear(global_step: int)
We will soon release a detailed tutorial and API documentation.
The primary motivation for integrating TransferQueue to verl now is to alleviate the data transfer bottleneck of the single controller RayPPOTrainer. Currently, all DataProto objects must be routed through RayPPOTrainer, resulting in a single point bottleneck of the whole post-training system.
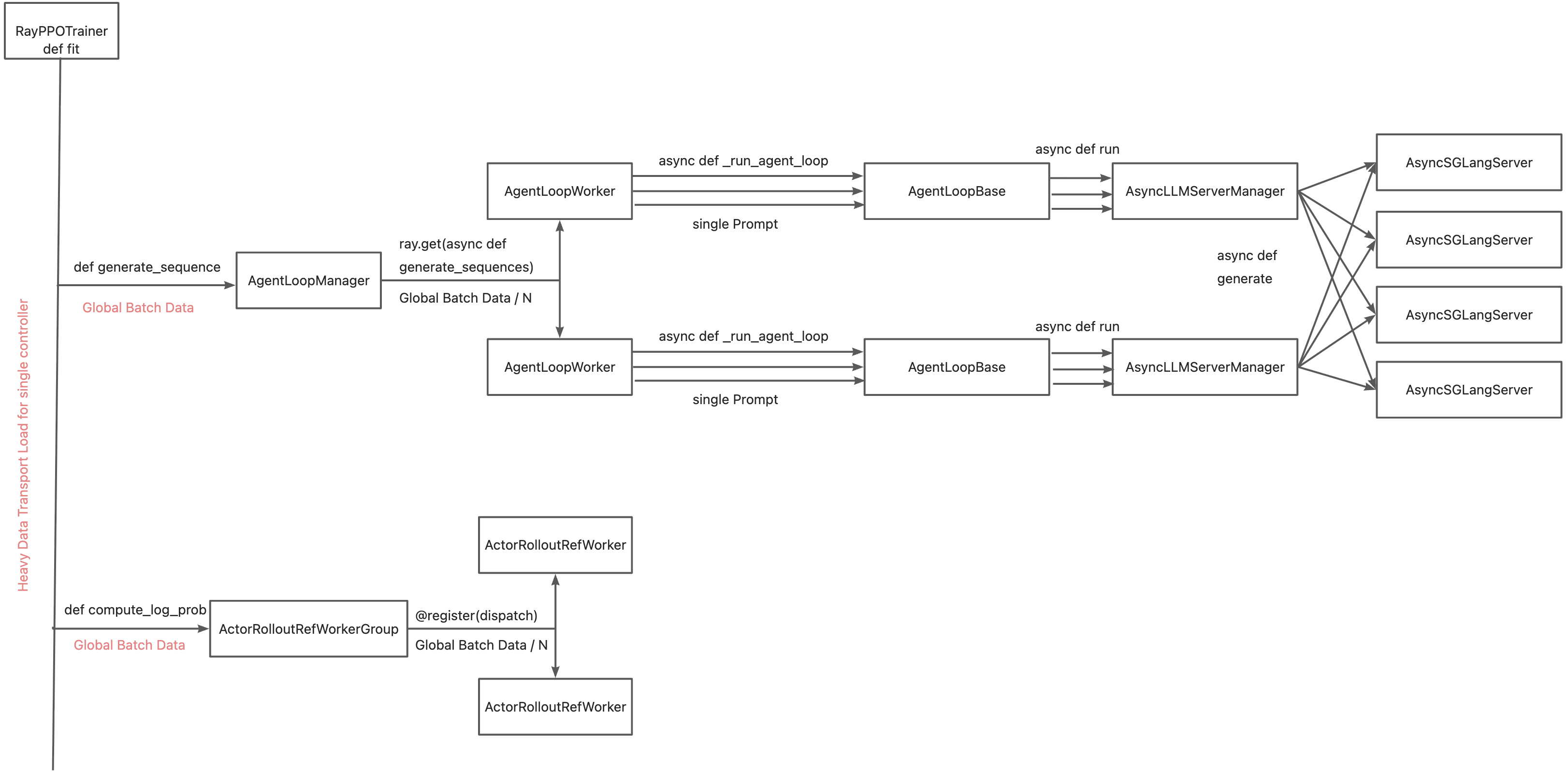
Leveraging TransferQueue, we separate experience data transfer from metadata dispatch by
- Replacing
DataProtowithBatchMeta(metadata) andTensorDict(actual data) structures - Preserving verl's original Dispatch/Collect logic via BatchMeta (maintaining single-controller debuggability)
- Accelerating data transfer by TransferQueue's distributed storage units
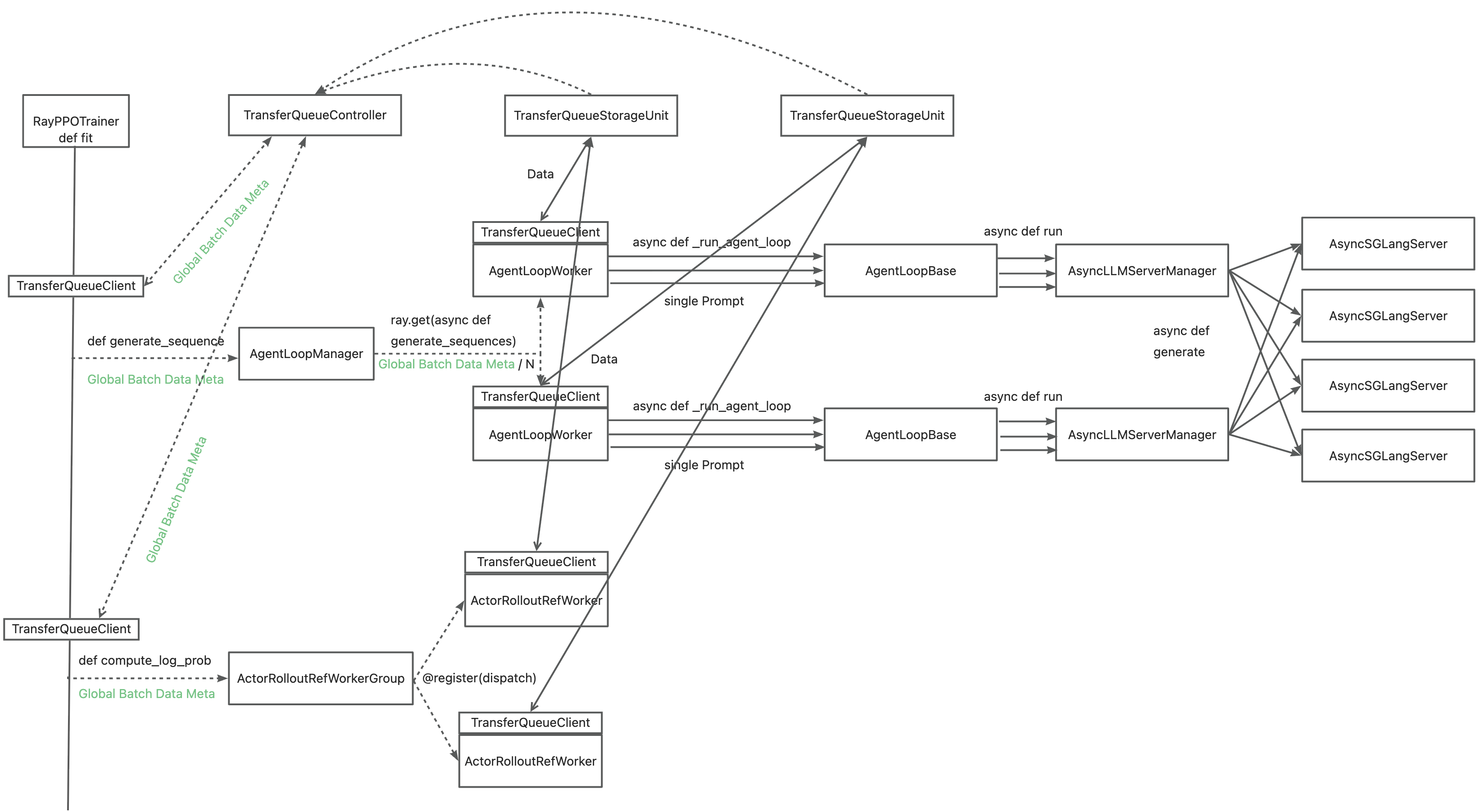
You may refer to the recipe, where we mimic the verl usage in both async & sync scenarios. Official integration to verl is on the way.
Work in progress :)
We will soon release the Python package on PyPI.
Follow these steps to build and install:
-
Retrieve source code from GitHub repo
git clone https://github.com/TransferQueue/TransferQueue/ cd TransferQueue -
Install dependencies
pip install -r requirements.txt
-
Build and install
python -m build --wheel pip install dist/*.whl
- Support data rewrite for partial rollout & agentic post-training
- Provide a general storage abstraction layer
TransferQueueStorageManagerto manage distributed storage units, which simplifiesClientdesign and makes it possible to introduce different storage backends (PR66) - Provide a
KVStorageManagerto cover all the KV based storage backends - Support topic-based data partitioning to maintain train/val/test data simultaneously
- Release the first stable version through PyPI
- Support disaggregated framework (each rank retrieves its own data without going through a centralized node)
- Provide a
StreamingDataLoaderinterface for disaggregated framework - Support load-balancing and dynamic batching
- Support high-performance storage backends for RDMA transmission (e.g., MoonCakeStore, Ray Direct Transport...)
- High-performance serialization and deserialization
- More documentation, examples and tutorials
@article{han2025asyncflow,
title={AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training},
author={Han, Zhenyu and You, Ansheng and Wang, Haibo and Luo, Kui and Yang, Guang and Shi, Wenqi and Chen, Menglong and Zhang, Sicheng and Lan, Zeshun and Deng, Chunshi and others},
journal={arXiv preprint arXiv:2507.01663},
year={2025}
}