diff --git a/_partials/_aws-features.md b/_partials/_aws-features.md
new file mode 100644
index 0000000000..6b83b8229b
--- /dev/null
+++ b/_partials/_aws-features.md
@@ -0,0 +1,65 @@
+The available $PRICING_PLANs are:
+
+* **Free**: for small non-production projects.
+* **$PERFORMANCE**: for cost-focused, smaller projects. No credit card required to start.
+* **$SCALE**: for developers handling critical and demanding apps.
+* **$ENTERPRISE**: for enterprises with mission-critical apps.
+
+
+
+The features included in each [$PRICING_PLAN][pricing-plans] are:
+
+| Feature | Free | $PERFORMANCE | $SCALE | $ENTERPRISE |
+|---------------------------------------------------------------|-----------------------------------|----------------------------------------|------------------------------------------------|--------------------------------------------------|
+| **Compute and storage** | | | | |
+| Number of $SERVICE_SHORTs | Up to 2 free services | Up to 2 free and 4 standard services | Up to 2 free and and unlimited standard services | Up to 2 free and and unlimited standard services |
+| CPU limit per $SERVICE_SHORT | Shared | Up to 8 CPU | Up to 32 CPU | Up to 64 CPU |
+| Memory limit per $SERVICE_SHORT | Shared | Up to 32 GB | Up to 128 GB | Up to 256 GB |
+| Storage limit per $SERVICE_SHORT | 750 MB | Up to 16 TB | Up to 16 TB | Up to 64 TB |
+| Bottomless storage on S3 | | | Unlimited | Unlimited |
+| Independently scale compute and storage | | Standard services only | Standard services only | Standard services only |
+| **Data services and workloads** | | | |
+| Relational | ✓ | ✓ | ✓ | ✓ |
+| Time-series | ✓ | ✓ | ✓ | ✓ |
+| Vector search | ✓ | ✓ | ✓ | ✓ |
+| AI workflows (coming soon) | ✓ | ✓ | ✓ | ✓ |
+| Cloud SQL editor | 3 seats | 3 seats | 10 seats | 20 seats |
+| Charts | ✓ | ✓ | ✓ | ✓ |
+| Dashboards | | 2 | Unlimited | Unlimited |
+| **Storage and performance** | | | | |
+| IOPS | Shared | 3,000 - 5,000 | 5,000 - 8,000 | 5,000 - 8,000 |
+| Bandwidth (autoscales) | Shared | 125 - 250 Mbps | 250 - 500 Mbps | Up to 500 mbps |
+| I/O boost | | | Add-on:
Up to 16K IOPS, 1000 Mbps BW | Add-on:
Up to 32K IOPS, 4000 Mbps BW |
+| **Availability and monitoring** | | | | |
+| High-availability replicas
(Automated multi-AZ failover) | | ✓ | ✓ | ✓ |
+| Read replicas | | | ✓ | ✓ |
+| Cross-region backup | | | | ✓ |
+| Backup reports | | | 14 days | 14 days |
+| Point-in-time recovery and forking | 1 day | 3 days | 14 days | 14 days |
+| Performance insights | Limited | ✓ | ✓ | ✓ |
+| Metrics and log exporters | | | ✓ | ✓ |
+| **Security and compliance** | | | | |
+| Role-based access | ✓ | ✓ | ✓ | ✓ |
+| End-to-end encryption | ✓ | ✓ | ✓ | ✓ |
+| Private Networking (VPC) | | 1 multi-attach VPC | Unlimited multi-attach VPCs | Unlimited multi-attach VPCs |
+| AWS Transit Gateway | | | ✓ | ✓ |
+| [HIPAA compliance][hipaa-compliance] | | | | ✓ |
+| IP address allow list | 1 list with up to 10 IP addresses | 1 list with up to 10 IP addresses | Up to 10 lists with up to 10 IP addresses each | Up to 10 lists with up to 100 IP addresses each |
+| Multi-factor authentication | ✓ | ✓ | ✓ | ✓ |
+| Federated authentication (SAML) | | | | ✓ |
+| SOC 2 Type 2 report | | | ✓ | ✓ |
+| Penetration testing report | | | | ✓ |
+| Security questionnaire and review | | | | ✓ |
+| Pay by invoice | | Available at minimum spend | Available at minimum spend | ✓ |
+| [Uptime SLAs][commercial-sla] | | Standard | Standard | Enterprise |
+| **Support and technical services** | | | | |
+| Community support | ✓ | ✓ | ✓ | ✓ |
+| Email support | | ✓ | ✓ | ✓ |
+| Production support | | Add-on | Add-on | ✓ |
+| Named account manager | | | | ✓ |
+| JOIN services (Jumpstart Onboarding and INtegration) | | | Available at minimum spend | ✓ |
+
+For a personalized quote, [get in touch with $COMPANY][contact-company].
+
+[pricing-plans]: https://www.timescale.com/pricing
+[contact-company]: https://www.tigerdata.com/contact/
\ No newline at end of file
diff --git a/_partials/_azure-features.md b/_partials/_azure-features.md
new file mode 100644
index 0000000000..7a14f11fac
--- /dev/null
+++ b/_partials/_azure-features.md
@@ -0,0 +1,61 @@
+The available $PRICING_PLANs are:
+
+* **Free**: for small non-production projects.
+* **$PERFORMANCE**: for cost-focused, smaller projects. No credit card required to start.
+* **$SCALE**: for developers handling critical and demanding apps.
+* **$ENTERPRISE**: for enterprises with mission-critical apps.
+
+
+
+The features included in each [$PRICING_PLAN][pricing-plans] are:
+
+| Feature | Free | $PERFORMANCE | $SCALE | $ENTERPRISE |
+|---------------------------------------------------------------|-----------------------------------|----------------------------------------|------------------------------------------------|--------------------------------------------------|
+| **Compute and storage** | | | | |
+| Number of $SERVICE_SHORTs | Up to 2 free services | Up to 2 free and 4 standard services | Up to 2 free and and unlimited standard services | Up to 2 free and and unlimited standard services |
+| CPU limit per $SERVICE_SHORT | Shared | Up to 8 CPU | Up to 32 CPU | Up to 64 CPU |
+| Memory limit per $SERVICE_SHORT | Shared | Up to 32 GB | Up to 128 GB | Up to 256 GB |
+| Storage limit per $SERVICE_SHORT | 750 MB | Up to 16 TB | Up to 16 TB | Up to 64 TB |
+| Independently scale compute and storage | | Standard services only | Standard services only | Standard services only |
+| **Data services and workloads** | | | |
+| Relational | ✓ | ✓ | ✓ | ✓ |
+| Time-series | ✓ | ✓ | ✓ | ✓ |
+| Vector search | ✓ | ✓ | ✓ | ✓ |
+| AI workflows (coming soon) | ✓ | ✓ | ✓ | ✓ |
+| Cloud SQL editor | 3 seats | 3 seats | 10 seats | 20 seats |
+| Charts | ✓ | ✓ | ✓ | ✓ |
+| Dashboards | | 2 | Unlimited | Unlimited |
+| **Storage and performance** | | | | |
+| IOPS | Shared | 3,000 - 5,000 | 5,000 - 8,000 | 5,000 - 8,000 |
+| Bandwidth (autoscales) | Shared | 125 - 250 Mbps | 250 - 500 Mbps | Up to 500 mbps |
+| I/O boost | | | Add-on:
Up to 16K IOPS, 1000 Mbps BW | Add-on:
Up to 32K IOPS, 4000 Mbps BW |
+| **Availability and monitoring** | | | | |
+| High-availability replicas
(Automated multi-AZ failover) | | ✓ | ✓ | ✓ |
+| Read replicas | | | ✓ | ✓ |
+| Backup reports | | | 14 days | 14 days |
+| Point-in-time recovery and forking | 1 day | 3 days | 14 days | 14 days |
+| Performance insights | Limited | ✓ | ✓ | ✓ |
+| Metrics and log exporters | | | ✓ | ✓ |
+| **Security and compliance** | | | | |
+| Role-based access | ✓ | ✓ | ✓ | ✓ |
+| End-to-end encryption | ✓ | ✓ | ✓ | ✓ |
+| [HIPAA compliance][hipaa-compliance] | | | | ✓ |
+| IP address allow list | 1 list with up to 10 IP addresses | 1 list with up to 10 IP addresses | Up to 10 lists with up to 10 IP addresses each | Up to 10 lists with up to 100 IP addresses each |
+| Multi-factor authentication | ✓ | ✓ | ✓ | ✓ |
+| Federated authentication (SAML) | | | | ✓ |
+| SOC 2 Type 2 report | | | ✓ | ✓ |
+| Penetration testing report | | | | ✓ |
+| Security questionnaire and review | | | | ✓ |
+| Pay by invoice | | Available at minimum spend | Available at minimum spend | ✓ |
+| [Uptime SLAs][commercial-sla] | | Standard | Standard | Enterprise |
+| **Support and technical services** | | | | |
+| Community support | ✓ | ✓ | ✓ | ✓ |
+| Email support | | ✓ | ✓ | ✓ |
+| Production support | | Add-on | Add-on | ✓ |
+| Named account manager | | | | ✓ |
+| JOIN services (Jumpstart Onboarding and INtegration) | | | Available at minimum spend | ✓ |
+
+For a personalized quote, [get in touch with $COMPANY][contact-company].
+
+[pricing-plans]: https://www.timescale.com/pricing
+[contact-company]: https://www.tigerdata.com/contact/
\ No newline at end of file
diff --git a/_partials/_billing-example.md b/_partials/_billing-example.md
new file mode 100644
index 0000000000..3be33287ba
--- /dev/null
+++ b/_partials/_billing-example.md
@@ -0,0 +1,25 @@
+You are billed at the end of each month in arrears. Your monthly invoice
+includes an itemized cost accounting for each $SERVICE_LONG and any additional charges.
+
+$CLOUD_LONG charges are based on consumption and your pricing plan:
+
+- **Compute**: billed and metered on an hourly basis. This means that you are billed for a full hour even if the actual consumption is less. You can scale compute up and down at any time. If the compute config changes mid-hour, you are billed for the config used at the end of that hour.
+- **Storage**: billed and metered on a quarter of an hour basis. Storage grows and shrinks automatically with your data.
+
+For example, over the last month your $SERVICE_LONG has been running compute for 500 hours total:
+
+- 375 hours with 2 CPU
+- 125 hours 4 CPU
+
+and consumed high-performance storage for 720 hours total:
+
+- 200 hours with 100 GB
+- 520 hours with 150 GB
+
+**Compute cost** = (`375` x `hourly price for 2 CPU`) + (`125` x `hourly price for 4 CPU`)
+
+**High-performance storage cost** = (`200` x `100 GB` x `hourly price per GB`) + (`520` x `150 GB` x `hourly price per GB`)
+
+Some add-ons such as tiered storage, HA replicas, and connection pooling may incur
+additional charges. These charges are clearly marked in your billing snapshot in $CONSOLE.
+
\ No newline at end of file
diff --git a/_partials/_cloud-connect-service.md b/_partials/_cloud-connect-service.md
index b5be5d3032..853d08dbce 100644
--- a/_partials/_cloud-connect-service.md
+++ b/_partials/_cloud-connect-service.md
@@ -6,7 +6,7 @@ import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-fre
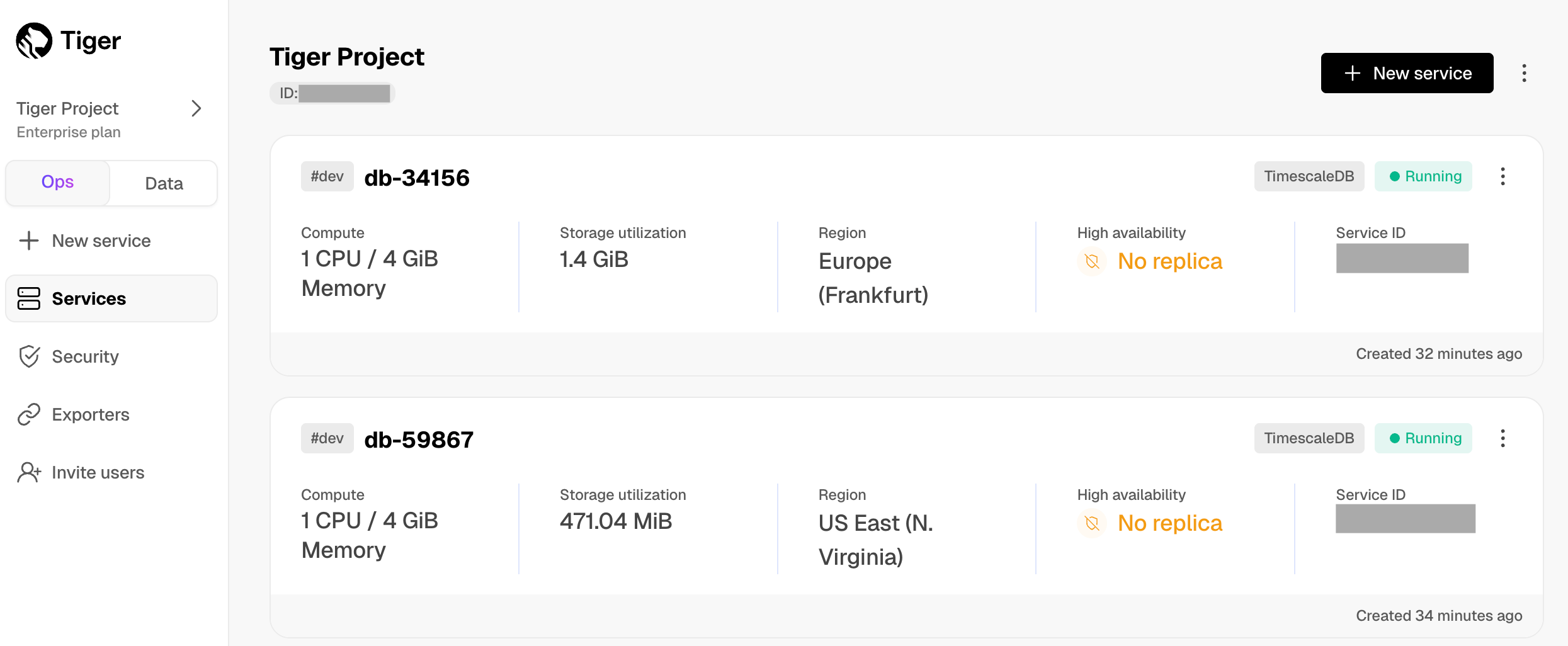
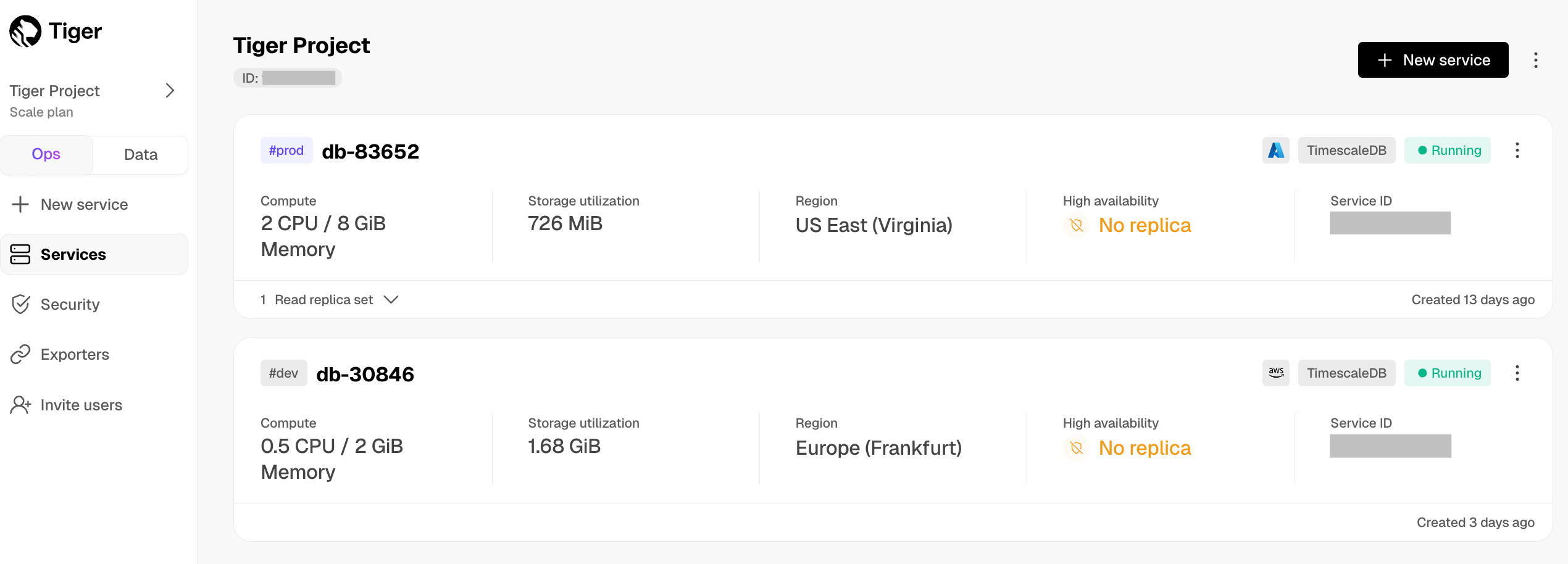
In [$CONSOLE][services-portal], check that your $SERVICE_SHORT is marked as `Running`.
- 
+ 
1. **Connect to your $SERVICE_SHORT**
@@ -48,7 +48,7 @@ import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-fre
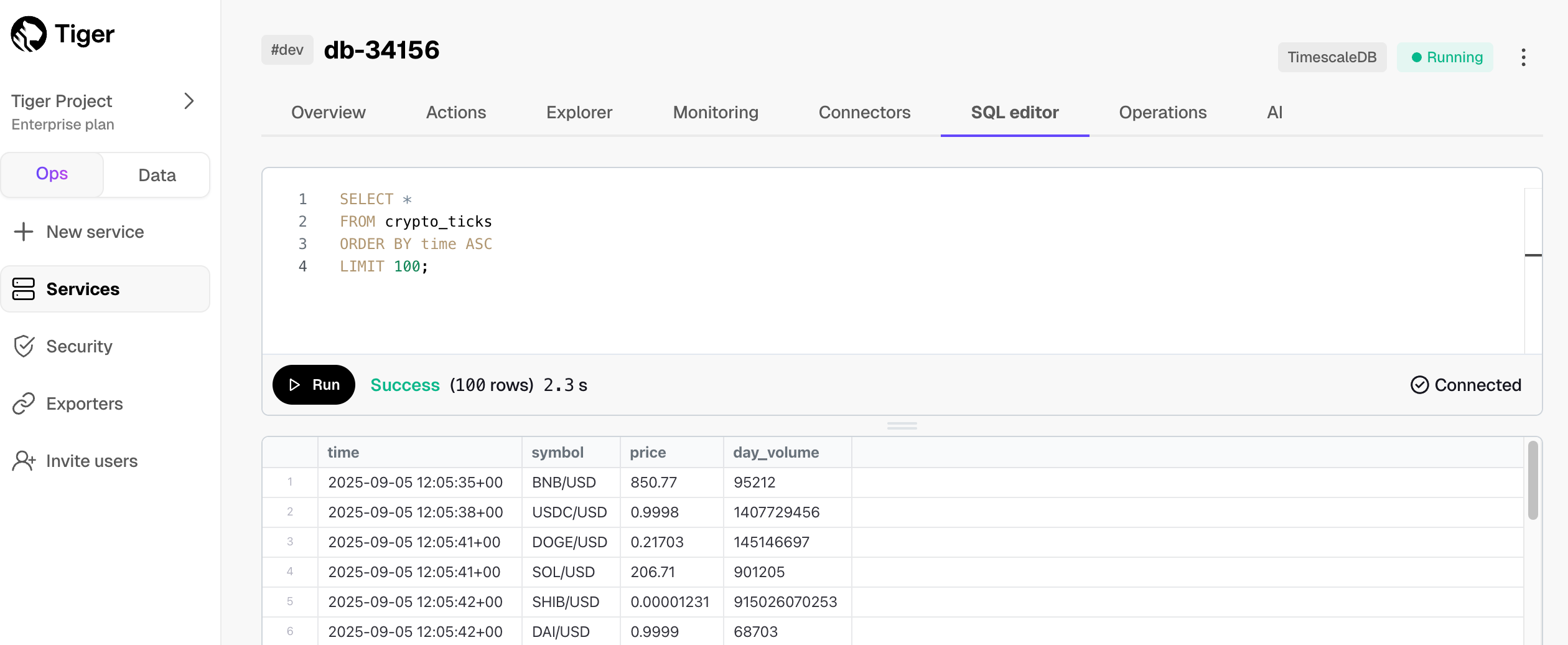
1. Click `SQL editor`.
- 
+ 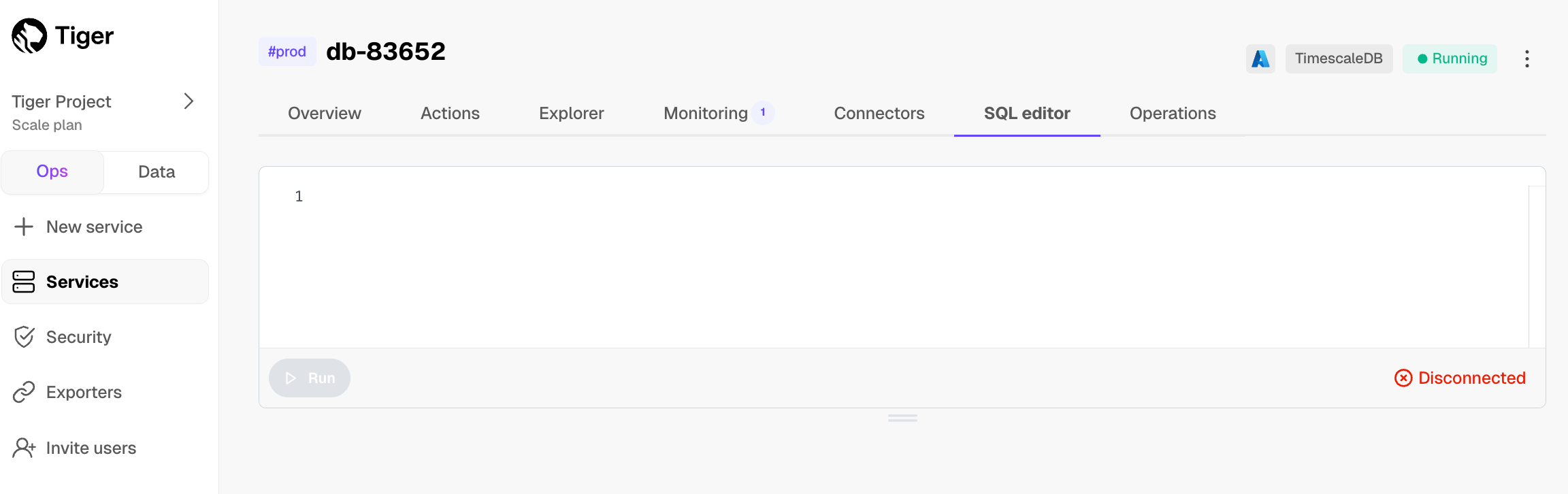
1. Run a test query:
diff --git a/_partials/_cloud-free-trial.md b/_partials/_cloud-free-trial.md
new file mode 100644
index 0000000000..571d9c24ef
--- /dev/null
+++ b/_partials/_cloud-free-trial.md
@@ -0,0 +1,14 @@
+import FreeBeta from "versionContent/_partials/_free-plan-beta.mdx";
+
+Are you just starting out with $CLOUD_LONG? On our Free pricing plan, you can create up to 2 zero-cost $SERVICE_SHORTs with [limited resources][plan-features]. When a free $SERVICE_SHORT reaches the resource limit, it converts to a read-only state.
+
+
+
+Ready to try a more feature-rich paid plan? Activate a 30-day free trial of our $PERFORMANCE (no credit card required) or $SCALE plan. After your trial ends, we may remove your data unless you’ve added a payment method.
+
+After you have completed your 30-day trial period, choose the
+[$PRICING_PLAN][plan-features] that suits your business and engineering needs. And even when you upgrade from the Free pricing plan, you can still have up to 2 zero-cost $SERVICE_SHORTs—or convert the ones you already have into standard ones, to have more resources.
+
+If you want to try out features in a higher $PRICING_PLAN before upgrading, contact us.
+
+[plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-plan
\ No newline at end of file
diff --git a/_partials/_cloud-installation-azure.md b/_partials/_cloud-installation-azure.md
new file mode 100644
index 0000000000..97735ee952
--- /dev/null
+++ b/_partials/_cloud-installation-azure.md
@@ -0,0 +1,12 @@
+import CreateAccountConsole from "versionContent/_partials/_create-account-console.mdx";
+
+You create a $ACCOUNT_LONG to manage your $SERVICE_SHORTs and data in a centralized and efficient manner in $CONSOLE. From there, you can create and delete $SERVICE_SHORTs, run queries, manage access and billing, integrate other services, contact support, and more.
+
+
+
+[tsc-portal]: https://console.cloud.timescale.com/
+[timescale-website]: https://www.timescale.com/
+[aws-marketplace]: https://aws.amazon.com/marketplace
+[aws-paygo]: https://aws.amazon.com/marketplace/pp/prodview-iestawpo5ihca?applicationId=AWSMPContessa&ref_=beagle&sr=0-1
+[aws-annual-commit]: https://aws.amazon.com/marketplace/pp/prodview-ezxwlmjyr6x4u?applicationId=AWSMPContessa&ref_=beagle&sr=0-2
+[timescale-signup]: https://console.cloud.timescale.com/signup
diff --git a/_partials/_cloud-installation.md b/_partials/_cloud-installation.md
index 544a1046ee..53501ef3b3 100644
--- a/_partials/_cloud-installation.md
+++ b/_partials/_cloud-installation.md
@@ -1,4 +1,4 @@
-## Create a $ACCOUNT_LONG
+import CreateAccountConsole from "versionContent/_partials/_create-account-console.mdx";
You create a $ACCOUNT_LONG to manage your $SERVICE_SHORTs and data in a centralized and efficient manner in $CONSOLE. From there, you can create and delete $SERVICE_SHORTs, run queries, manage access and billing, integrate other services, contact support, and more.
@@ -8,23 +8,7 @@ You create a $ACCOUNT_LONG to manage your $SERVICE_SHORTs and data in a centrali
You create a standalone account to manage $CLOUD_LONG as a separate unit in your infrastructure, which includes separate billing and invoicing.
-
-
-To set up $CLOUD_LONG:
-
-1. **Sign up for a 30-day free trial**
-
- Open [Sign up for $CLOUD_LONG][timescale-signup] and add your details, then click `Start your free trial`. You receive a confirmation email in your inbox.
-
-1. **Confirm your email address**
-
- In the confirmation email, click the link supplied.
-
-1. **Select the [pricing plan][pricing-plans]**
-
- You are now logged into $CONSOLE_LONG. You can change the pricing plan to better accommodate your growing needs on the [`Billing` page][console-billing].
-
-
+
diff --git a/_partials/_cloud-intro-azure.md b/_partials/_cloud-intro-azure.md
new file mode 100644
index 0000000000..8ce330bd9f
--- /dev/null
+++ b/_partials/_cloud-intro-azure.md
@@ -0,0 +1,37 @@
+$CLOUD_LONG is the modern $PG data platform for all your applications. It enhances $PG to handle time series, events,
+real-time analytics, and vector search—all in a single database alongside transactional workloads.
+
+You get one system that handles live data ingestion, late and out-of-order updates, and low latency queries, with the performance, reliability, and scalability your app needs. Ideal for IoT, crypto, finance, SaaS, and a myriad other domains, $CLOUD_LONG allows you to build data-heavy, mission-critical apps while retaining the familiarity and reliability of $PG.
+
+A $SERVICE_LONG is a single optimised $PG instance extended with innovations in the database engine and cloud
+infrastructure to deliver speed without compromise. A $SERVICE_LONG instance is 10-1000x faster at scale! A $SERVICE_SHORT
+is ideal for applications requiring strong data consistency, complex relationships, and advanced querying capabilities.
+Get ACID compliance, extensive SQL support, JSON handling, and extensibility through custom functions, data types, and
+extensions. To the $PG you know and love, $CLOUD_LONG adds the following capabilities:
+
+- **Real-time analytics**: store and query [time-series data][what-is-time-series] at scale for
+ real-time analytics and other use cases. Get faster time-based queries with $HYPERTABLEs, $CAGGs, and columnar storage. Save money by compressing data into the $COLUMNSTORE and deleting old data with automated policies.
+- **AI-focused**: build AI applications from start to scale. Get fast and accurate similarity search
+ with the pgvector and pgvectorscale extensions. Create vector embeddings and perform LLM reasoning on your data with
+ the pgai extension.
+- **Hybrid applications**: get a full set of tools to develop applications that combine time-based data and AI.
+
+All $SERVICE_LONGs include the tooling you expect for production and developer environments: [live migration][live-migration],
+[automatic backups and PITR][automatic-backups], [high availability][high-availability], [$READ_REPLICAs][readreplica], [data forking][operations-forking], [connection pooling][connection-pooling],
+[usage-based storage][how-plans-work], secure in-$CONSOLE [SQL editing][in-console-editors], $SERVICE_SHORT [metrics][metrics]
+and [insights][insights], [streamlined maintenance][maintain-upgrade], and much more. $CLOUD_LONG continuously monitors your $SERVICE_SHORTs and prevents common $PG out-of-memory crashes.
+
+[what-is-time-series]: https://www.timescale.com/blog/time-series-database-an-explainer#what-is-a-time-series-database
+[create-service]: /getting-started/:currentVersion:/services/
+[live-migration]: /migrate/:currentVersion:/live-migration/
+[automatic-backups]: /use-timescale/:currentVersion:/backup-restore/
+[high-availability]: /use-timescale/:currentVersion:/ha-replicas/high-availability/
+[readreplica]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/
+[operations-forking]: /use-timescale/:currentVersion:/services/service-management/#fork-a-service
+[connection-pooling]: /use-timescale/:currentVersion:/services/connection-pooling
+[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
+[how-plans-work]: /about/:currentVersion:/pricing-and-account-management/#how-plans-work
+[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
+[metrics]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#metrics
+[insights]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#insights
+[maintain-upgrade]: /use-timescale/:currentVersion:/upgrades/
\ No newline at end of file
diff --git a/_partials/_cloud-mst-comparison.md b/_partials/_cloud-mst-comparison.md
index 8b9cd9cab3..cb8a053c6f 100644
--- a/_partials/_cloud-mst-comparison.md
+++ b/_partials/_cloud-mst-comparison.md
@@ -1,13 +1,10 @@
-$CLOUD_LONG is a high-performance developer focused cloud that provides $PG services enhanced
-with our blazing fast vector search. You can securely integrate $CLOUD_LONG with your AWS, GCS or Azure
-infrastructure. [Create a $SERVICE_LONG][timescale-service] and try for free.
-
-If you need to run $TIMESCALE_DB on GCP or Azure, you're in the right place — keep reading.
+$CLOUD_LONG is a high-performance, developer-focused cloud that provides $PG services enhanced
+with our blazing fast vector search, data tiering, monitoring suite, and other features. [Create a $SERVICE_LONG][timescale-service] and try for free.
diff --git a/_partials/_create-account-console.md b/_partials/_create-account-console.md
new file mode 100644
index 0000000000..dba9a9af19
--- /dev/null
+++ b/_partials/_create-account-console.md
@@ -0,0 +1,21 @@
+
+
+To set up $CLOUD_LONG:
+
+1. **Sign up for a 30-day free trial**
+
+ Open [Sign up for $CLOUD_LONG][timescale-signup] and add your details, then click `Start your free trial`. You receive a confirmation email in your inbox.
+
+1. **Confirm your email address**
+
+ In the confirmation email, click the link supplied.
+
+1. **Select the [pricing plan][pricing-plans]**
+
+ You are now logged into $CONSOLE_LONG. You can change the pricing plan to better accommodate your growing needs on the [`Billing` page][console-billing].
+
+
+
+[timescale-signup]: https://console.cloud.timescale.com/signup
+[console-billing]: https://console.cloud.timescale.com/dashboard/billing/plans
+[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
\ No newline at end of file
diff --git a/_partials/_create-service.md b/_partials/_create-service.md
new file mode 100644
index 0000000000..8300da8278
--- /dev/null
+++ b/_partials/_create-service.md
@@ -0,0 +1,19 @@
+
+
+3. In the [$SERVICE_SHORT creation page][create-service], click `+ New service`.
+
+ Follow the wizard to configure your $SERVICE_SHORT depending on its type.
+
+1. Click `Create service`.
+
+ Your $SERVICE_SHORT is constructed and ready to use in a few seconds.
+
+1. Click `Download the config` and store the configuration information you need to connect to this $SERVICE_SHORT in a secure location.
+
+ This file contains the passwords and configuration information you need to connect to your $SERVICE_SHORT using the
+ $CONSOLE $DATA_MODE, from the command line, or using third-party database administration tools.
+
+
+
+[create-service]: https://console.cloud.timescale.com/dashboard/create_services
+[connect-to-your-service]: /getting-started/:currentVersion:/services/#connect-to-your-service
\ No newline at end of file
diff --git a/_partials/_devops-cli-get-started.md b/_partials/_devops-cli-get-started.md
index 6b517072a6..8ca88cc89c 100644
--- a/_partials/_devops-cli-get-started.md
+++ b/_partials/_devops-cli-get-started.md
@@ -1,6 +1,7 @@
import RESTPrereqs from "versionContent/_partials/_prereqs-cloud-account-only.mdx";
import CLIINSTALL from "versionContent/_partials/_devops-cli-install.mdx";
import CLIREF from "versionContent/_partials/_devops-cli-reference.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
$CLI_LONG is a command-line interface that you use to manage $CLOUD_LONG resources
including VPCs, services, read replicas, and related infrastructure. $CLI_LONG calls $REST_LONG to communicate with
@@ -13,6 +14,8 @@ service.
+
+
## Install and configure $CLI_LONG
diff --git a/_partials/_disaggregated-compute-storage-azure.md b/_partials/_disaggregated-compute-storage-azure.md
new file mode 100644
index 0000000000..1666d479a3
--- /dev/null
+++ b/_partials/_disaggregated-compute-storage-azure.md
@@ -0,0 +1,18 @@
+With $CLOUD_LONG, you are not limited to pre-set compute and storage. Get as much as you need when
+provisioning your $SERVICE_SHORTs or later, as your needs grow.
+
+* **Compute**: pay only for the compute resources you run. Compute is metered on an hourly
+ basis, and you can [scale it up to 32,000 IOPS][change-compute] at any time. You can also [scale out using replicas][read-replication]
+ as your application grows. We also provide services to help you lower your compute needs
+ while improving query performance. $CLOUD_LONG is very efficient and generally needs less compute than other databases to deliver
+ the same performance. The best way to size your needs is to sign up for a free trial and test
+ with a realistic workload.
+
+* **Storage**: pay only for the storage you consume. The high-performance storage offers you up to 64 TB of compressed
+ (typically 80-100 TB uncompressed) data and is metered on your average GB consumption per hour. We can help you compress your data by up to 98% so you pay even less.
+
+For easy upgrades, each $SERVICE_SHORT stores the $TIMESCALE_DB binaries. This contributes up to 900 MB to overall storage, which amounts to less than $.80/month in additional storage costs.
+
+[change-compute]: /use-timescale/:currentVersion:/services/change-resources/
+[read-replication]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/
+[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
\ No newline at end of file
diff --git a/_partials/_disaggregated-compute-storage.md b/_partials/_disaggregated-compute-storage.md
new file mode 100644
index 0000000000..c6774d05e7
--- /dev/null
+++ b/_partials/_disaggregated-compute-storage.md
@@ -0,0 +1,20 @@
+import TieredStorageBilling from "versionContent/_partials/_tiered-storage-billing.mdx";
+
+With $CLOUD_LONG, you are not limited to pre-set compute and storage. Get as much as you need when
+provisioning your $SERVICE_SHORTs or later, as your needs grow.
+
+* **Compute**: pay only for the compute resources you run. Compute is metered on an hourly
+ basis, and you can [scale it up to 64,000 IOPS][change-compute] at any time. You can also [scale out using replicas][read-replication]
+ as your application grows. We also provide services to help you lower your compute needs
+ while improving query performance. $CLOUD_LONG is very efficient and generally needs less compute than other databases to deliver
+ the same performance. The best way to size your needs is to sign up for a free trial and test
+ with a realistic workload.
+
+* **Storage**: pay only for the storage you consume. You have high-performance storage for more-accessed data, and
+ [low-cost bottomless storage in S3][data-tiering] for other data. The high-performance storage offers you up to 64 TB of compressed
+ (typically 80-100 TB uncompressed) data and is metered on your average GB consumption per hour. We can help you compress your data by up to 98% so you pay even less.
+ For easy upgrades, each $SERVICE_SHORT stores the $TIMESCALE_DB binaries. This contributes up to 900 MB to overall storage, which amounts to less than $.80/month in additional storage costs.
+
+[change-compute]: /use-timescale/:currentVersion:/services/change-resources/
+[read-replication]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/
+[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
\ No newline at end of file
diff --git a/_partials/_high-availability-setup.md b/_partials/_high-availability-setup.md
index a2dfe7166c..09afb7598e 100644
--- a/_partials/_high-availability-setup.md
+++ b/_partials/_high-availability-setup.md
@@ -4,7 +4,7 @@
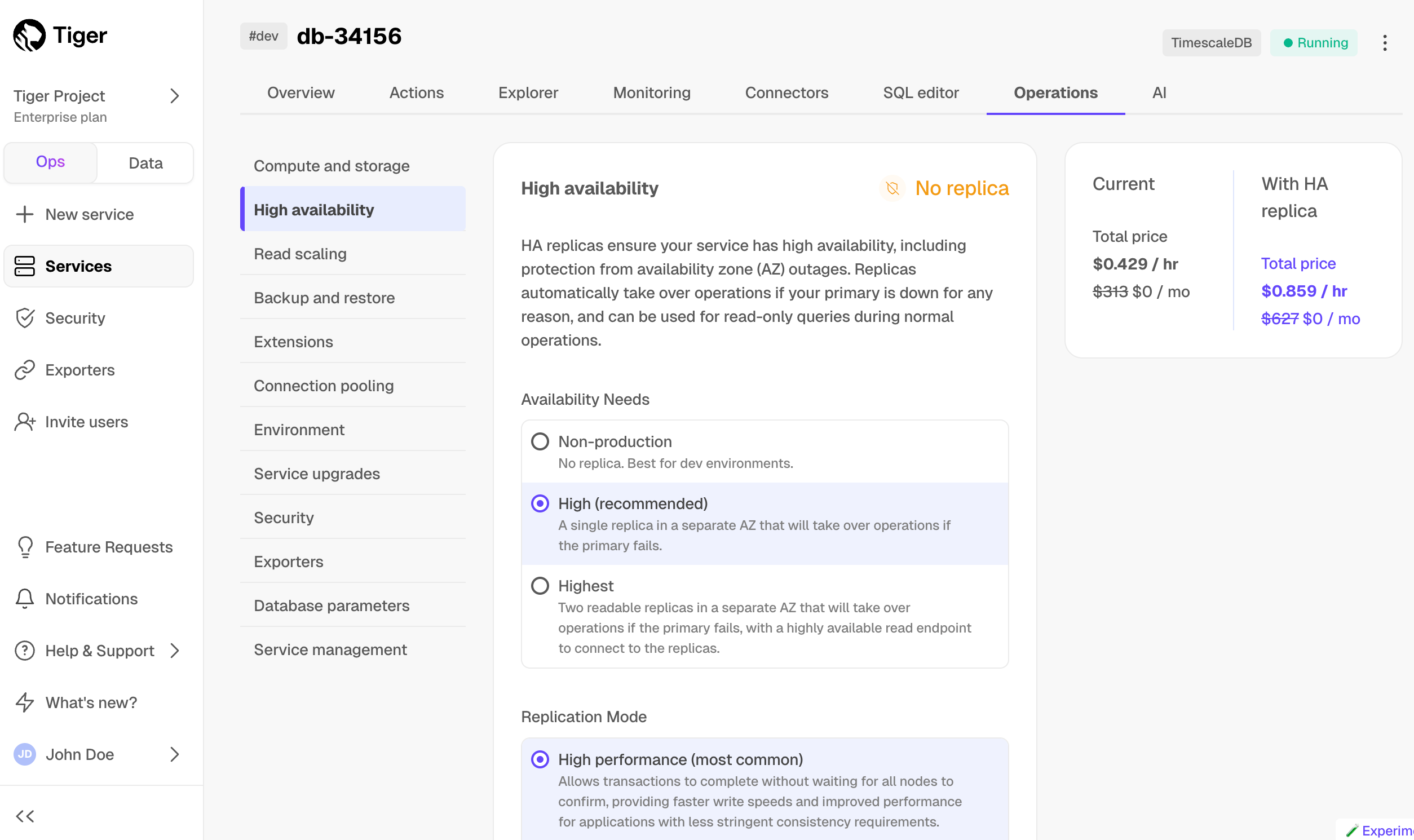
1. Click `Operations`, then select `High availability`.
1. Choose your replication strategy, then click `Change configuration`.
- 
+ 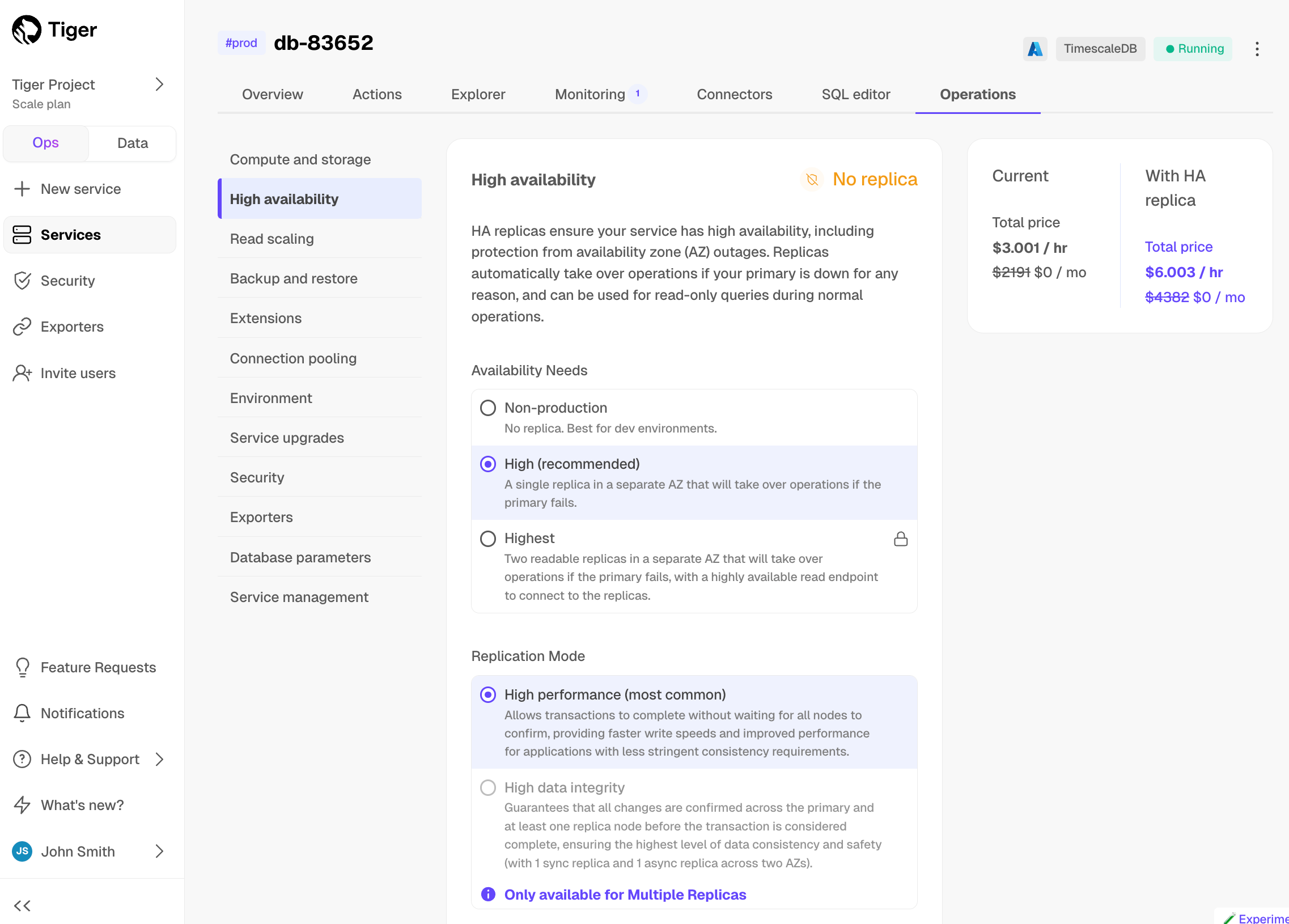
1. In `Change high availability configuration`, click `Change config`.
diff --git a/_partials/_livesync-console.md b/_partials/_livesync-console.md
index c09fe7c865..ed58b04dff 100644
--- a/_partials/_livesync-console.md
+++ b/_partials/_livesync-console.md
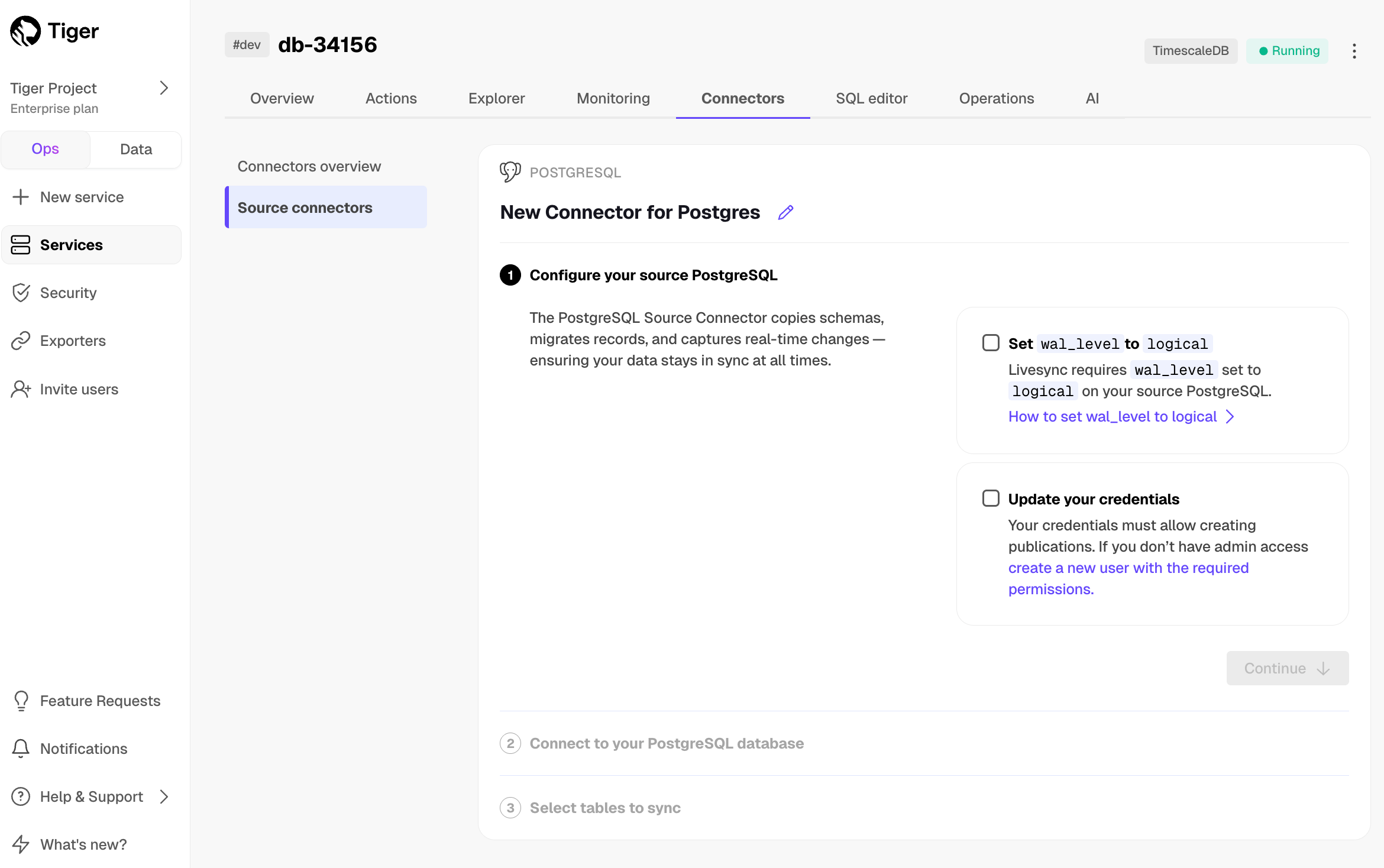
@@ -78,7 +78,7 @@ To sync data from your $PG database to your $SERVICE_LONG using $CONSOLE:
1. **Connect the source database and the target $SERVICE_SHORT**
- 
+ 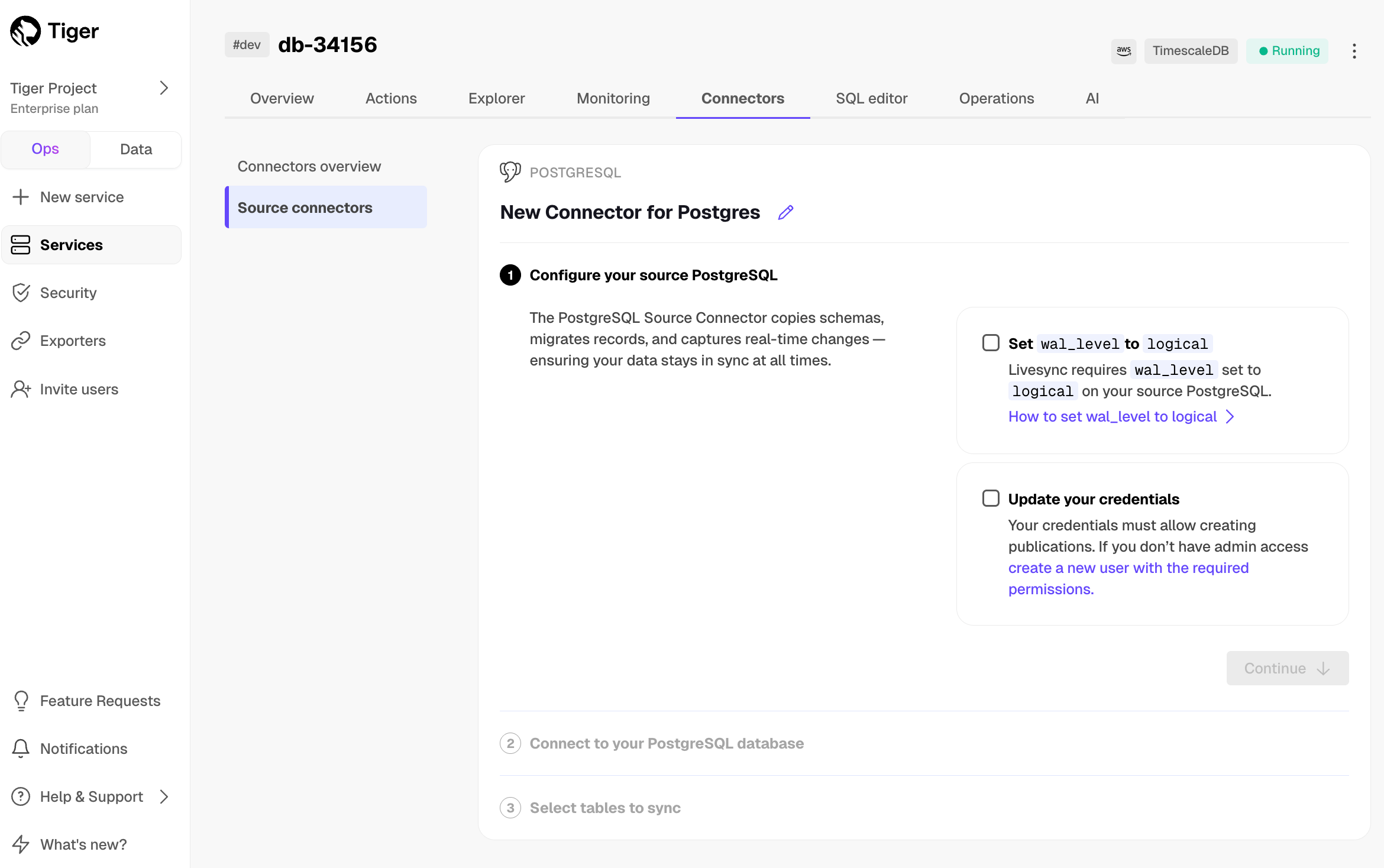
1. Click `Connectors` > `PostgreSQL`.
1. Set the name for the new connector by clicking the pencil icon.
@@ -88,7 +88,7 @@ To sync data from your $PG database to your $SERVICE_LONG using $CONSOLE:
1. **Optimize the data to synchronize in $HYPERTABLEs**
- 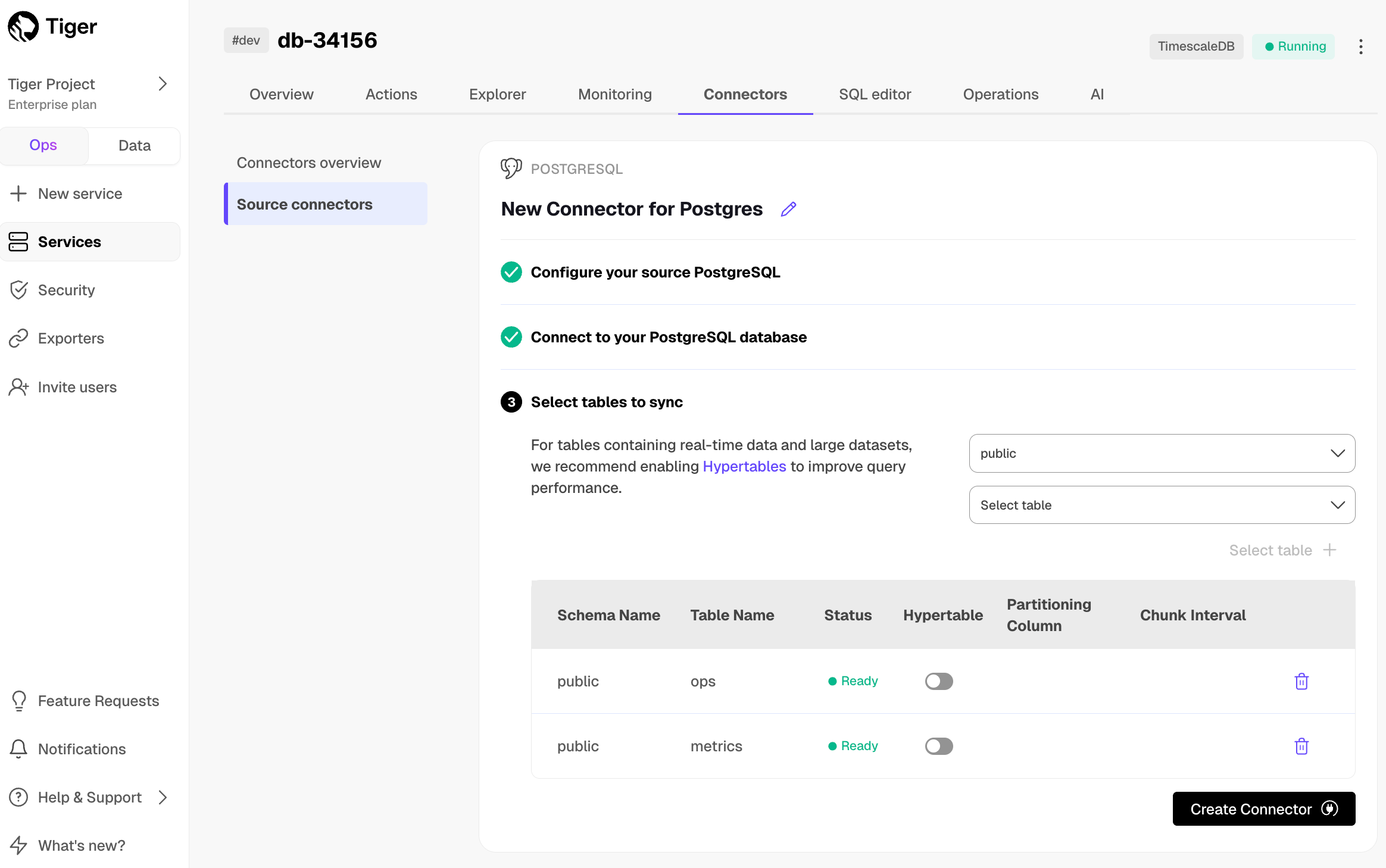
+ 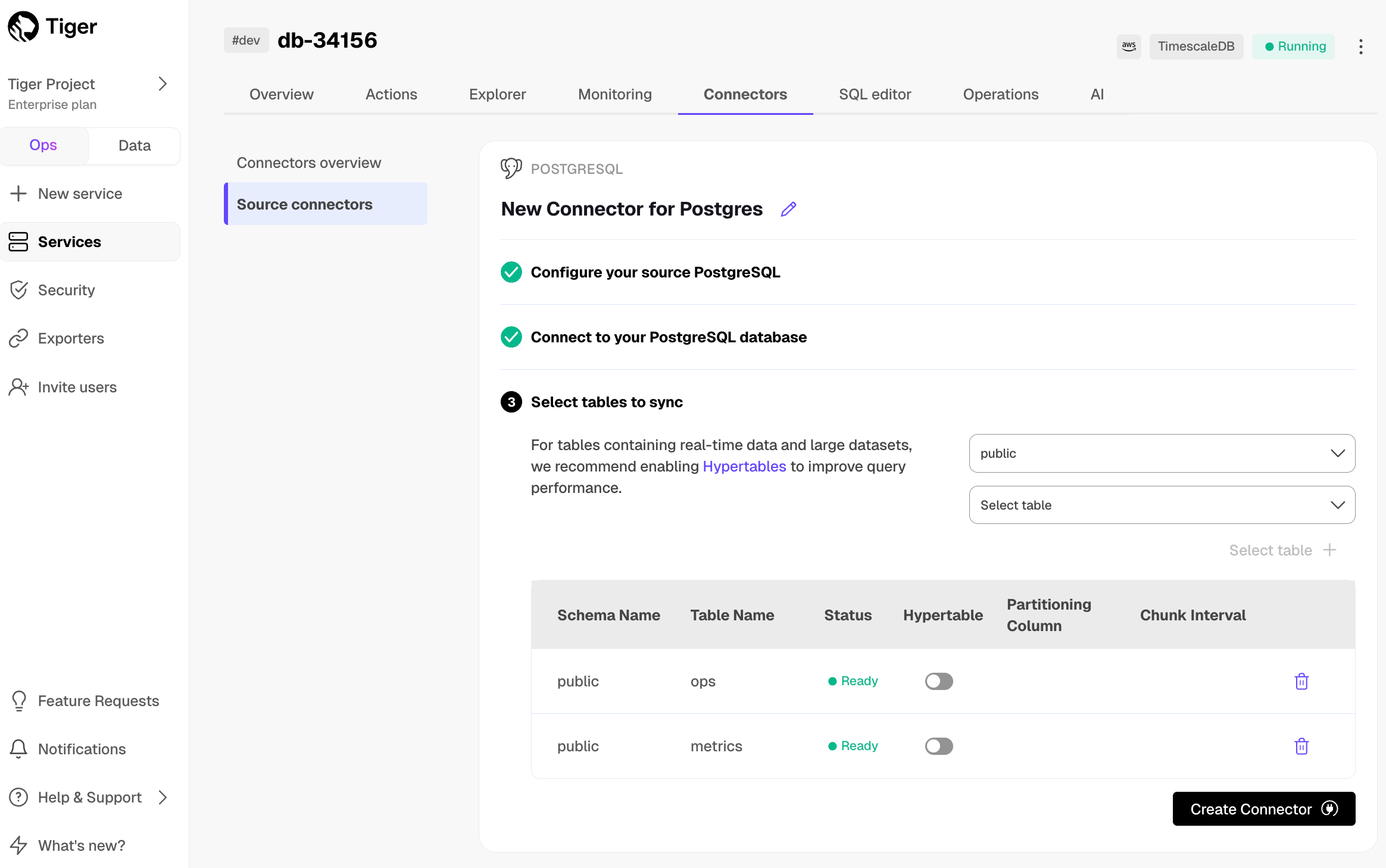
1. In the `Select table` dropdown, select the tables to sync.
1. Click `Select tables +` .
@@ -100,7 +100,7 @@ To sync data from your $PG database to your $SERVICE_LONG using $CONSOLE:
1. **Monitor synchronization**
- 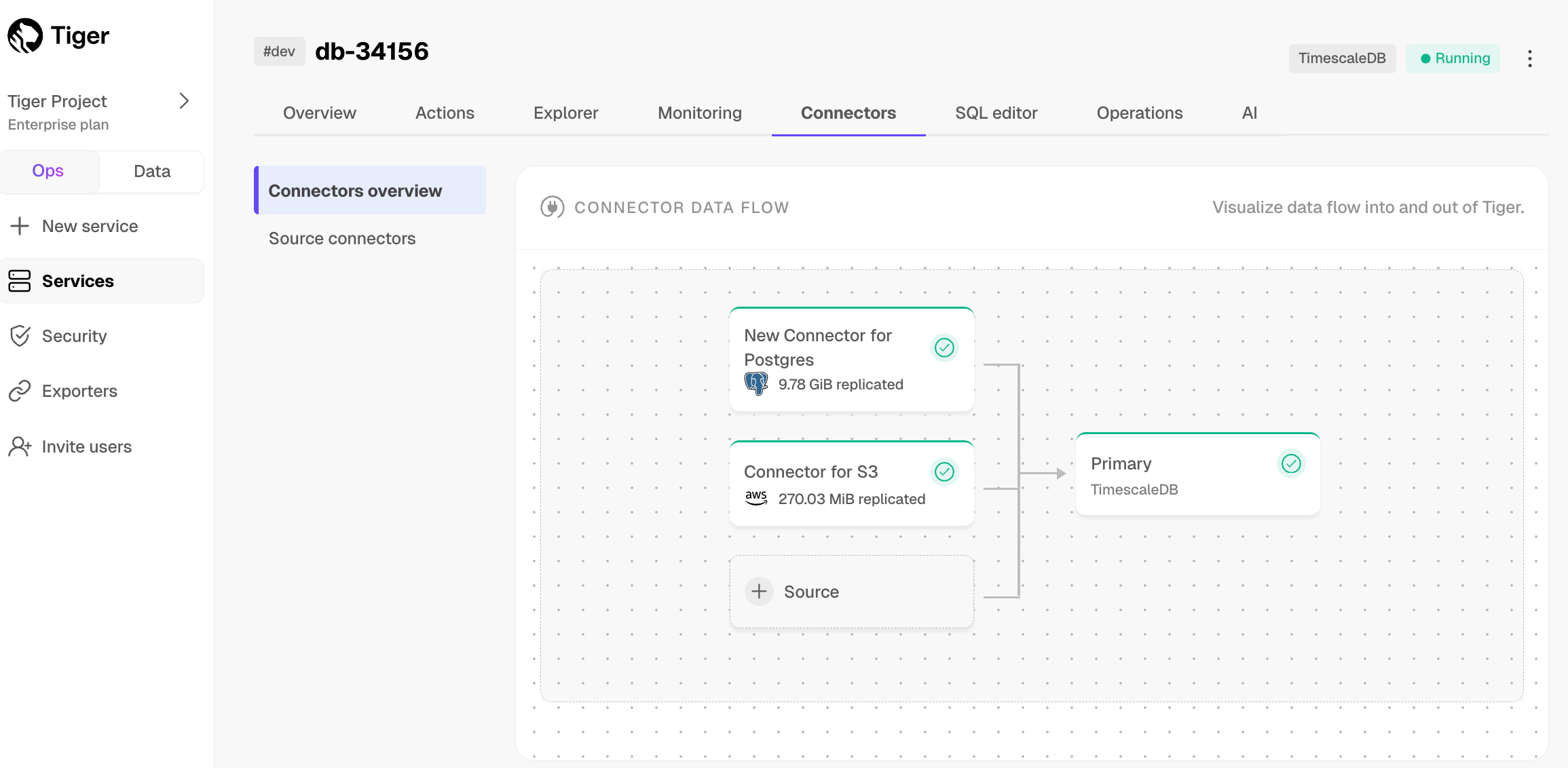
+ 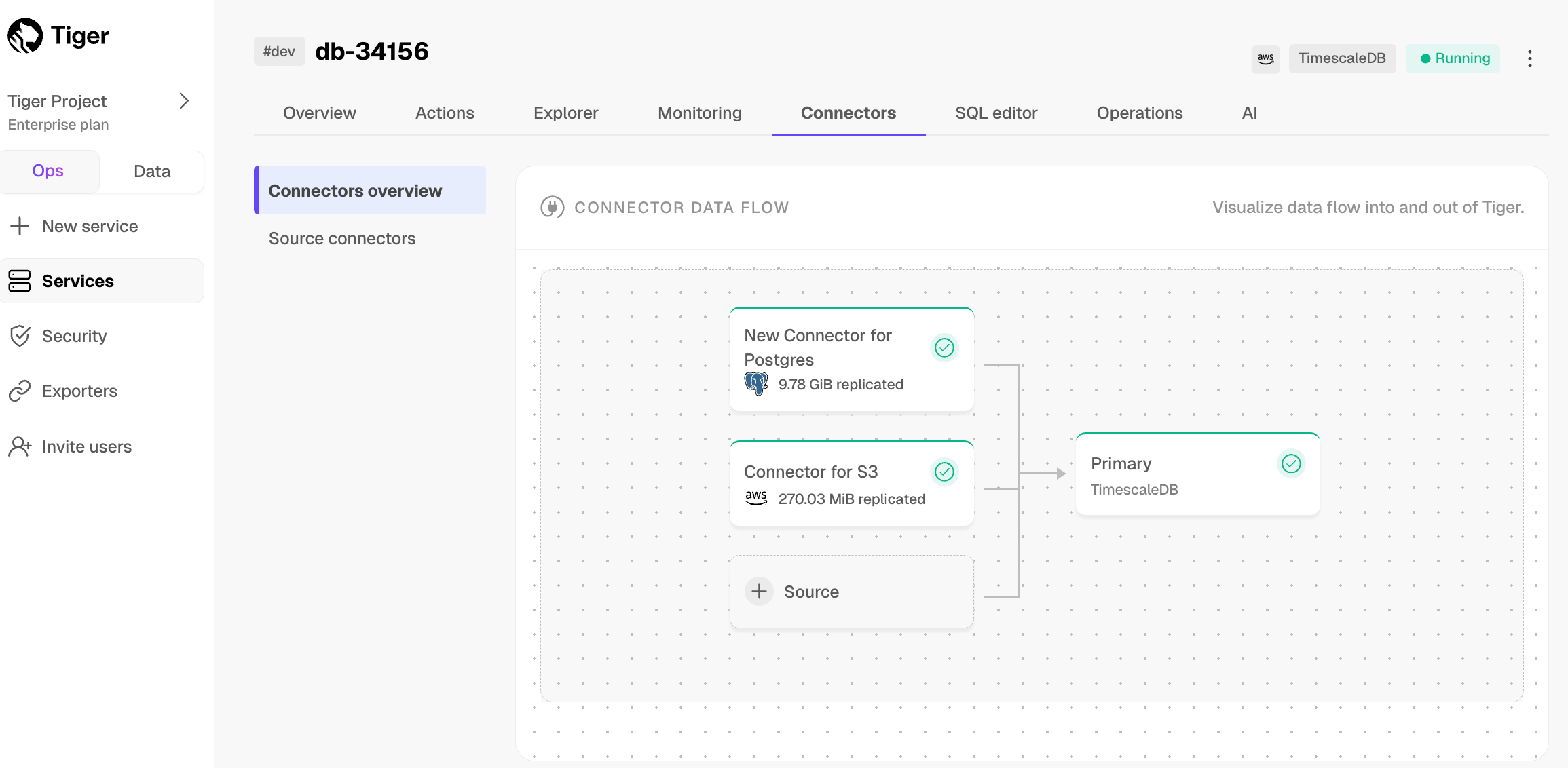
1. To view the amount of data replicated, click `Connectors`. The diagram in `Connector data flow` gives you an overview of the connectors you have created, their status, and how much data has been replicated.
@@ -108,7 +108,7 @@ To sync data from your $PG database to your $SERVICE_LONG using $CONSOLE:
1. **Manage the connector**
- 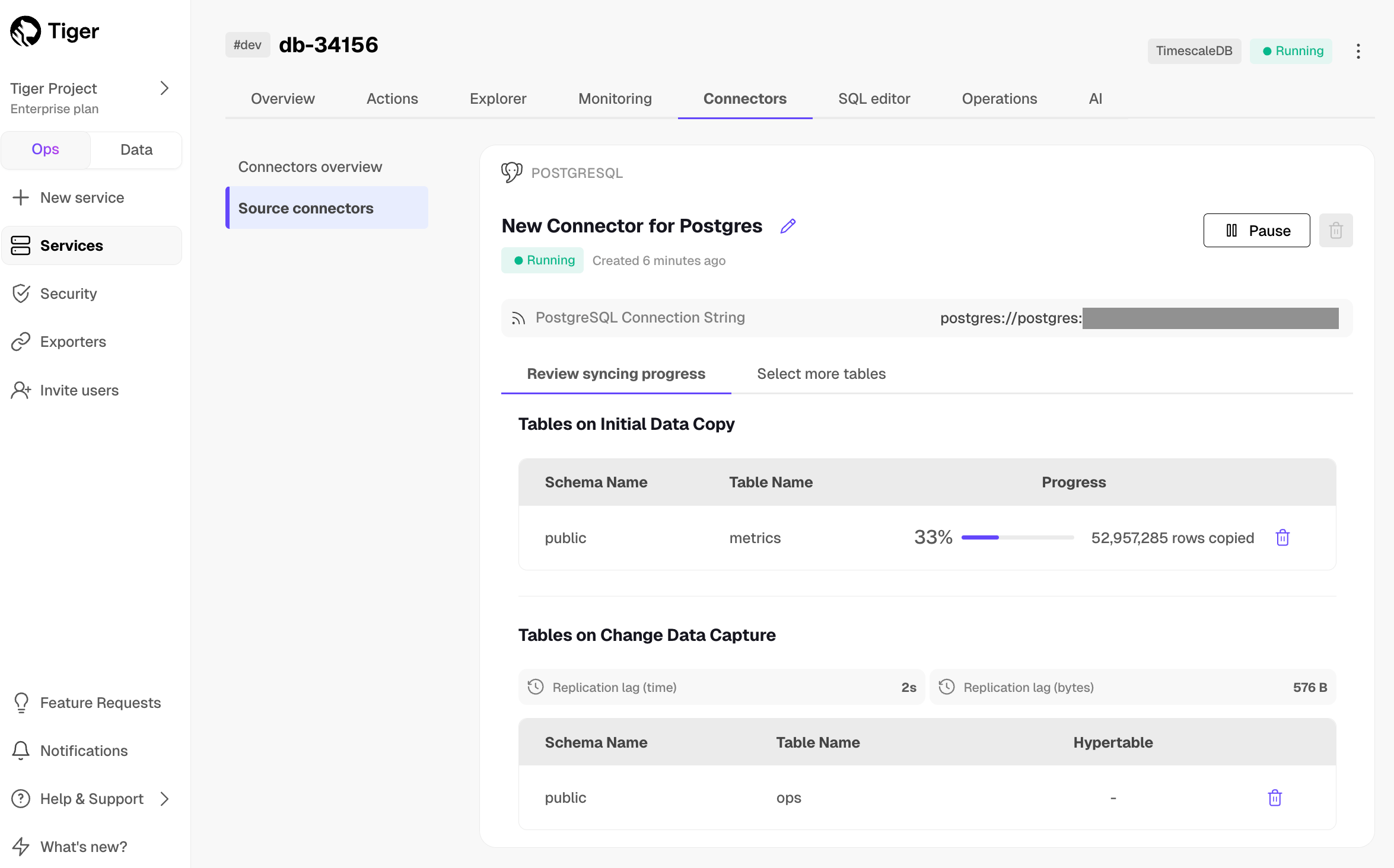
+ 
1. To edit the connector, click `Connectors` > `Source connectors`, then select the name of your connector in the table. You can rename the connector, delete or add new tables for syncing.
diff --git a/_partials/_manage-pricing-plan.md b/_partials/_manage-pricing-plan.md
new file mode 100644
index 0000000000..f18d9a5331
--- /dev/null
+++ b/_partials/_manage-pricing-plan.md
@@ -0,0 +1,25 @@
+You handle all details about your $CLOUD_LONG project including updates to your $PRICING_PLAN,
+payment methods, and add-ons in the [billing section in $CONSOLE][cloud-billing]:
+
+![]() +
+- **Details**: an overview of your $PRICING_PLAN, usage, and payment details. You can add up
+ to three credit cards to your `Wallet`. If you prefer to pay by invoice,
+ [contact $COMPANY][contact-company] and ask to change to corporate billing.
+
+- **Emails**: the addresses $COMPANY uses to communicate with you. Payment
+ confirmations and alerts are sent to the email address you signed up with.
+ Add another address to send details to other departments in your organization.
+
+- **History**: the list of your downloadable $CLOUD_LONG invoices.
+
+- **Plans**: choose the $PRICING_PLAN supplying the [features][plan-features] that suit your business and
+ engineering needs.
+
+- **Add-ons**: add `Production support` and improved database performance for mission-critical workloads.
+
+[cloud-billing]: https://console.cloud.timescale.com/dashboard/billing/details
+[contact-company]: https://www.tigerdata.com/contact/
+[plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-plan
\ No newline at end of file
diff --git a/_partials/_mst-intro.md b/_partials/_mst-intro.md
index 3f2d2f898b..0036b7cc78 100644
--- a/_partials/_mst-intro.md
+++ b/_partials/_mst-intro.md
@@ -1,2 +1 @@
-$MST_LONG ($MST_SHORT) is [$TIMESCALE_DB ](https://github.com/timescale/timescaledb) hosted on Azure and GCP.
-MST is offered in partnership with Aiven.
+[$MST_LONG ($MST_SHORT)](https://www.tigerdata.com/mst-signup) is hosted [$TIMESCALE_DB](https://github.com/timescale/timescaledb) offered in partnership with Aiven.
diff --git a/_partials/_not-supported-for-azure.md b/_partials/_not-supported-for-azure.md
new file mode 100644
index 0000000000..cc108fd357
--- /dev/null
+++ b/_partials/_not-supported-for-azure.md
@@ -0,0 +1,5 @@
+
+
+This feature is on our roadmap for $CLOUD_LONG on Microsoft Azure. Stay tuned!
+
+
\ No newline at end of file
diff --git a/_partials/_not-supported-for-azure.mdx b/_partials/_not-supported-for-azure.mdx
new file mode 100644
index 0000000000..cc108fd357
--- /dev/null
+++ b/_partials/_not-supported-for-azure.mdx
@@ -0,0 +1,5 @@
+
+
+This feature is on our roadmap for $CLOUD_LONG on Microsoft Azure. Stay tuned!
+
+
\ No newline at end of file
diff --git a/_partials/_pitr-intro.md b/_partials/_pitr-intro.md
new file mode 100644
index 0000000000..243832f8d8
--- /dev/null
+++ b/_partials/_pitr-intro.md
@@ -0,0 +1,12 @@
+To recover your $SERVICE_SHORT from a destructive or unwanted action, create a point-in-time recovery fork. You can recover a $SERVICE_SHORT to any point within the period [defined by your pricing plan][pricing-and-account-management]. The original $SERVICE_SHORT stays untouched to avoid losing data created since the time of recovery.
+
+Since the point-in-time recovery is done in a fork, to migrate your
+application to the point of recovery, change the connection
+strings in your application to use the fork. The provision time for the
+recovery fork is typically less than twenty minutes, but can take longer
+depending on the amount of WAL to be replayed.
+
+To avoid paying for compute for the recovery fork and the original $SERVICE_SHORT, pause the original to only pay storage costs.
+
+
+[pricing-and-account-management]: /about/:currentVersion:/pricing-and-account-management/
\ No newline at end of file
diff --git a/_partials/_pricing-plans-intro.md b/_partials/_pricing-plans-intro.md
new file mode 100644
index 0000000000..44a2619dad
--- /dev/null
+++ b/_partials/_pricing-plans-intro.md
@@ -0,0 +1,30 @@
+As we enhance our offerings and align them with your evolving needs,
+$PRICING_PLANs provide more value, flexibility, and efficiency for your business.
+Whether you're a growing startup or a well-established enterprise, our plans
+are structured to support your journey towards greater success.
+
+
+
+This page explains pricing plans for $CLOUD_LONG, and how to easily manage your $ACCOUNT_LONG.
+
+$PRICING_PLAN_CAPs give you:
+
+* **Enhanced performance**: with increased CPU and storage capacities, your apps run smoother and more
+ efficiently, even under heavy loads.
+* **Improved scalability**: as your business grows, so do your demands. $PRICING_PLAN_CAPs scale with
+ you, they provide the resources and support you need at each stage of your growth. Scale up or down
+ based on your current needs, ensuring that you only pay for what you use.
+* **Better support**: access to enhanced support options, including production support and dedicated
+ account management, ensures you have the help you need when you need it.
+* **Greater flexibility**: we know that one size doesn't fit all. $PRICING_PLAN_CAPs give you the
+ flexibility to choose the features and support levels that best match your business
+ and engineering requirements. The ability to add features like $IO_BOOST and customize your $PRICING_PLAN means you can tailor $SERVICE_LONGs to fit your specific needs.
+* **Cost efficiency**: by aligning our pricing with the value delivered, we ensure that you get the most
+ out of every dollar spent. Our goal is to help you achieve more with less.
+
+It’s that simple! You don't pay for automated backups or networking costs, such as data ingest or egress.
+There are no per-query fees, nor additional costs to read or write data. It's all completely transparent, easily understood, and up to you.
+
+Using $SELF_LONG and our open-source products is still free.
+
+[aws-pricing]: /about/:currentVersion:/pricing-and-account-management/#aws-marketplace-pricing
\ No newline at end of file
diff --git a/_partials/_prometheus-integrate.md b/_partials/_prometheus-integrate.md
index 06f1519296..9a18db415d 100644
--- a/_partials/_prometheus-integrate.md
+++ b/_partials/_prometheus-integrate.md
@@ -1,4 +1,5 @@
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
[Prometheus][prometheus] is an open-source monitoring system with a dimensional data model, flexible query language, and a modern alerting approach.
@@ -20,6 +21,8 @@ To follow the steps on this page:
- [Install Postgres Exporter][install-exporter].
To reduce latency and potential data transfer costs, install Prometheus and Postgres Exporter on a machine in the same AWS region as your $SERVICE_LONG.
+
+
## Export $SERVICE_LONG telemetry to Prometheus
To export your data, do the following:
@@ -52,11 +55,11 @@ To export metrics from a $SERVICE_LONG, you create a dedicated Prometheus export
1. Select the exporter in the drop-down, then click `Attach exporter`.
- 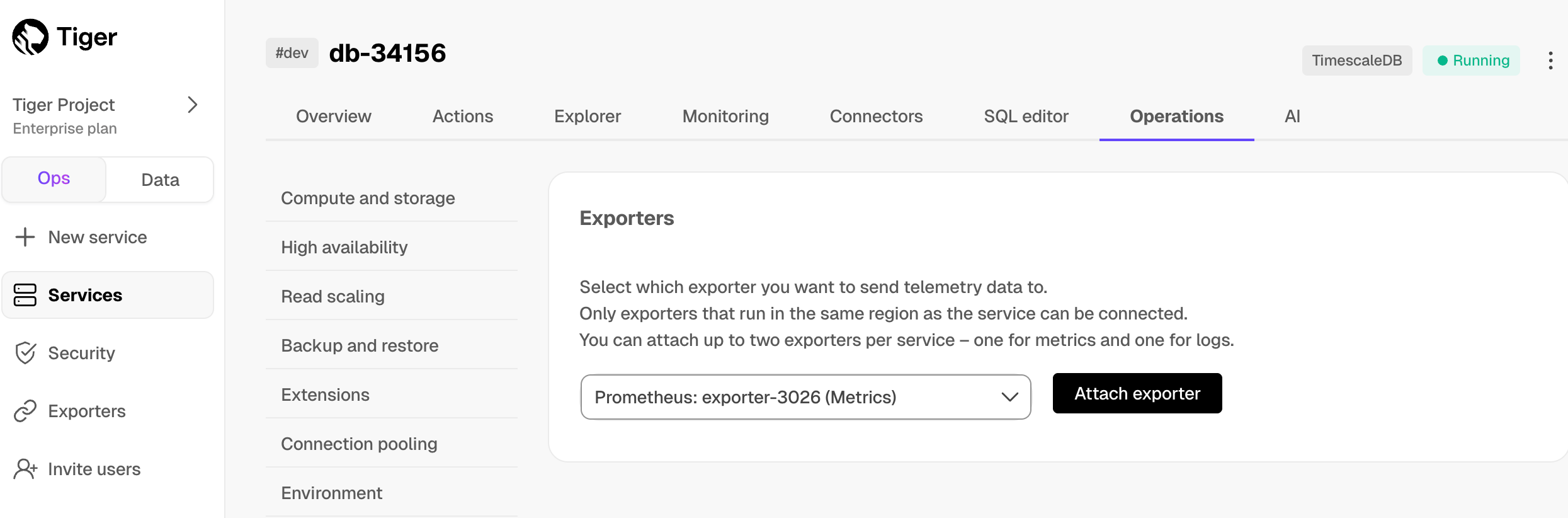
+ 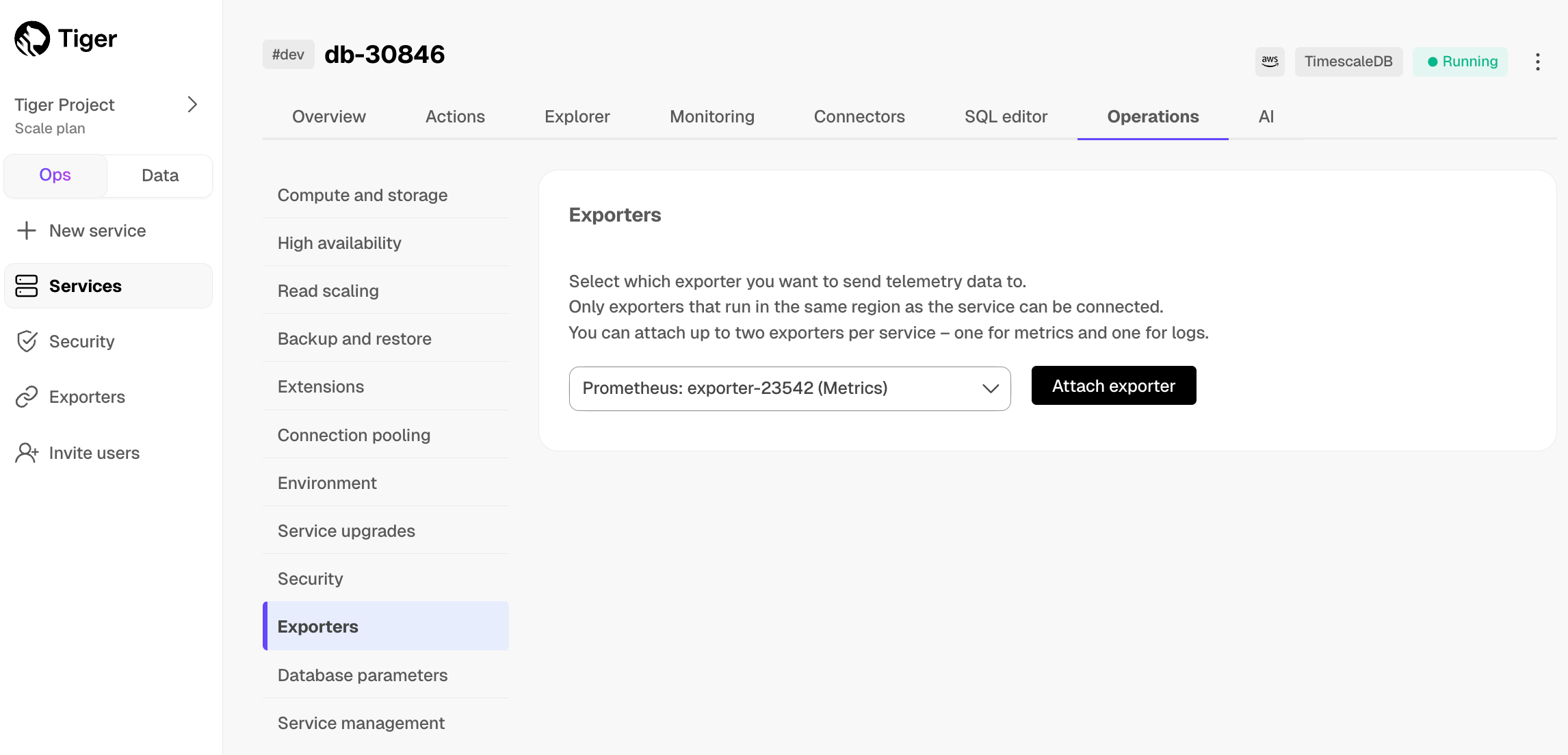
The exporter is now attached to your $SERVICE_SHORT. To unattach it, click the trash icon in the exporter list.
- 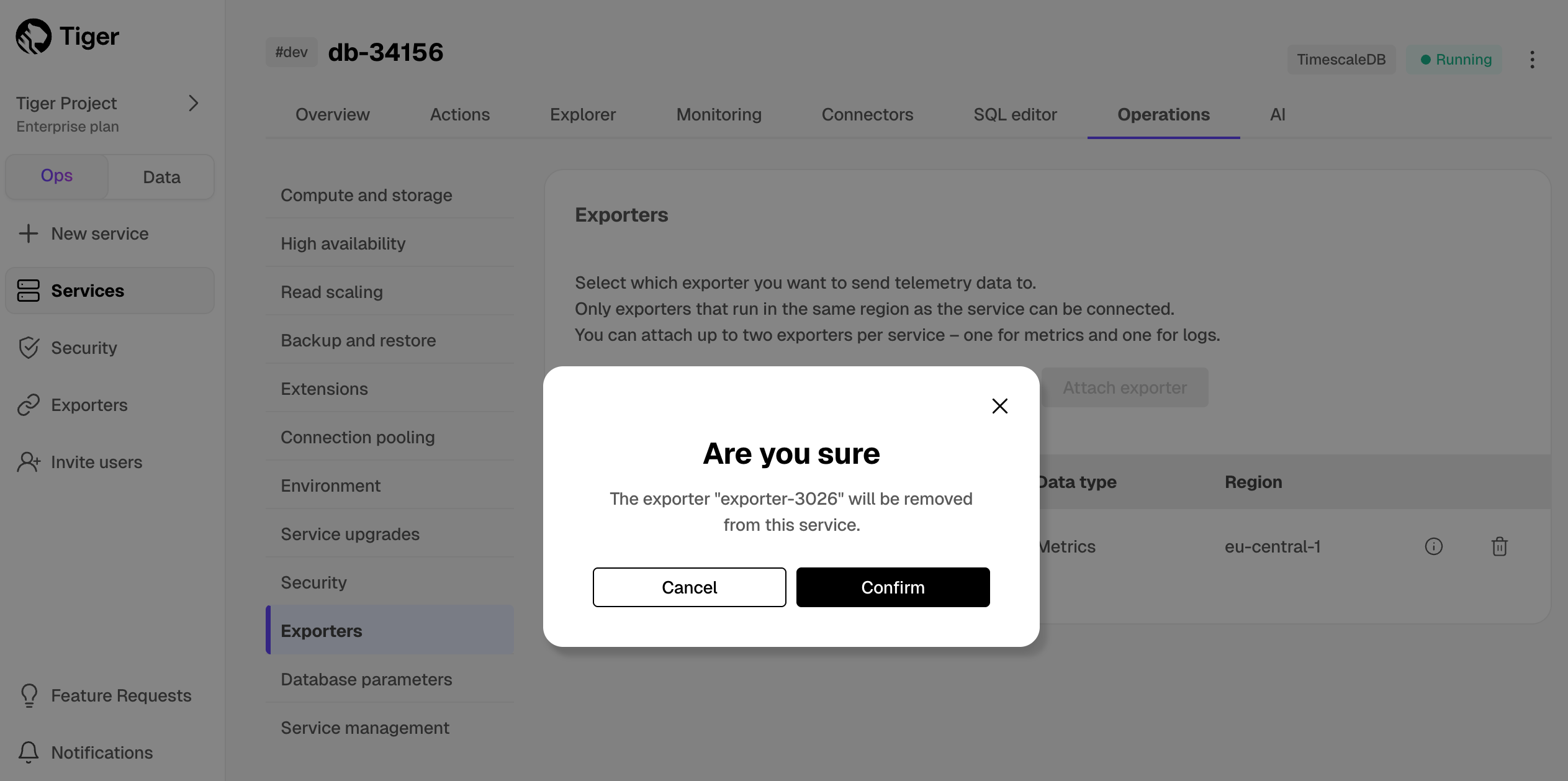
+ 
1. **Configure the Prometheus scrape target**
diff --git a/_partials/_service-overview-azure.md b/_partials/_service-overview-azure.md
new file mode 100644
index 0000000000..1035dc4ef8
--- /dev/null
+++ b/_partials/_service-overview-azure.md
@@ -0,0 +1,11 @@
+import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
+
+You manage your $SERVICE_LONGs and interact with your data in $CONSOLE using the following modes:
+
+| **$OPS_MODE_CAP** | **$DATA_MODE_CAP** |
+|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| ![$CONSOLE $OPS_MODE][ops-mode] | ![$CONSOLE $DATA_MODE][data-mode] |
+| **You use the $OPS_MODE to:**
+
+- **Details**: an overview of your $PRICING_PLAN, usage, and payment details. You can add up
+ to three credit cards to your `Wallet`. If you prefer to pay by invoice,
+ [contact $COMPANY][contact-company] and ask to change to corporate billing.
+
+- **Emails**: the addresses $COMPANY uses to communicate with you. Payment
+ confirmations and alerts are sent to the email address you signed up with.
+ Add another address to send details to other departments in your organization.
+
+- **History**: the list of your downloadable $CLOUD_LONG invoices.
+
+- **Plans**: choose the $PRICING_PLAN supplying the [features][plan-features] that suit your business and
+ engineering needs.
+
+- **Add-ons**: add `Production support` and improved database performance for mission-critical workloads.
+
+[cloud-billing]: https://console.cloud.timescale.com/dashboard/billing/details
+[contact-company]: https://www.tigerdata.com/contact/
+[plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-plan
\ No newline at end of file
diff --git a/_partials/_mst-intro.md b/_partials/_mst-intro.md
index 3f2d2f898b..0036b7cc78 100644
--- a/_partials/_mst-intro.md
+++ b/_partials/_mst-intro.md
@@ -1,2 +1 @@
-$MST_LONG ($MST_SHORT) is [$TIMESCALE_DB ](https://github.com/timescale/timescaledb) hosted on Azure and GCP.
-MST is offered in partnership with Aiven.
+[$MST_LONG ($MST_SHORT)](https://www.tigerdata.com/mst-signup) is hosted [$TIMESCALE_DB](https://github.com/timescale/timescaledb) offered in partnership with Aiven.
diff --git a/_partials/_not-supported-for-azure.md b/_partials/_not-supported-for-azure.md
new file mode 100644
index 0000000000..cc108fd357
--- /dev/null
+++ b/_partials/_not-supported-for-azure.md
@@ -0,0 +1,5 @@
+
+
+This feature is on our roadmap for $CLOUD_LONG on Microsoft Azure. Stay tuned!
+
+
\ No newline at end of file
diff --git a/_partials/_not-supported-for-azure.mdx b/_partials/_not-supported-for-azure.mdx
new file mode 100644
index 0000000000..cc108fd357
--- /dev/null
+++ b/_partials/_not-supported-for-azure.mdx
@@ -0,0 +1,5 @@
+
+
+This feature is on our roadmap for $CLOUD_LONG on Microsoft Azure. Stay tuned!
+
+
\ No newline at end of file
diff --git a/_partials/_pitr-intro.md b/_partials/_pitr-intro.md
new file mode 100644
index 0000000000..243832f8d8
--- /dev/null
+++ b/_partials/_pitr-intro.md
@@ -0,0 +1,12 @@
+To recover your $SERVICE_SHORT from a destructive or unwanted action, create a point-in-time recovery fork. You can recover a $SERVICE_SHORT to any point within the period [defined by your pricing plan][pricing-and-account-management]. The original $SERVICE_SHORT stays untouched to avoid losing data created since the time of recovery.
+
+Since the point-in-time recovery is done in a fork, to migrate your
+application to the point of recovery, change the connection
+strings in your application to use the fork. The provision time for the
+recovery fork is typically less than twenty minutes, but can take longer
+depending on the amount of WAL to be replayed.
+
+To avoid paying for compute for the recovery fork and the original $SERVICE_SHORT, pause the original to only pay storage costs.
+
+
+[pricing-and-account-management]: /about/:currentVersion:/pricing-and-account-management/
\ No newline at end of file
diff --git a/_partials/_pricing-plans-intro.md b/_partials/_pricing-plans-intro.md
new file mode 100644
index 0000000000..44a2619dad
--- /dev/null
+++ b/_partials/_pricing-plans-intro.md
@@ -0,0 +1,30 @@
+As we enhance our offerings and align them with your evolving needs,
+$PRICING_PLANs provide more value, flexibility, and efficiency for your business.
+Whether you're a growing startup or a well-established enterprise, our plans
+are structured to support your journey towards greater success.
+
+
+
+This page explains pricing plans for $CLOUD_LONG, and how to easily manage your $ACCOUNT_LONG.
+
+$PRICING_PLAN_CAPs give you:
+
+* **Enhanced performance**: with increased CPU and storage capacities, your apps run smoother and more
+ efficiently, even under heavy loads.
+* **Improved scalability**: as your business grows, so do your demands. $PRICING_PLAN_CAPs scale with
+ you, they provide the resources and support you need at each stage of your growth. Scale up or down
+ based on your current needs, ensuring that you only pay for what you use.
+* **Better support**: access to enhanced support options, including production support and dedicated
+ account management, ensures you have the help you need when you need it.
+* **Greater flexibility**: we know that one size doesn't fit all. $PRICING_PLAN_CAPs give you the
+ flexibility to choose the features and support levels that best match your business
+ and engineering requirements. The ability to add features like $IO_BOOST and customize your $PRICING_PLAN means you can tailor $SERVICE_LONGs to fit your specific needs.
+* **Cost efficiency**: by aligning our pricing with the value delivered, we ensure that you get the most
+ out of every dollar spent. Our goal is to help you achieve more with less.
+
+It’s that simple! You don't pay for automated backups or networking costs, such as data ingest or egress.
+There are no per-query fees, nor additional costs to read or write data. It's all completely transparent, easily understood, and up to you.
+
+Using $SELF_LONG and our open-source products is still free.
+
+[aws-pricing]: /about/:currentVersion:/pricing-and-account-management/#aws-marketplace-pricing
\ No newline at end of file
diff --git a/_partials/_prometheus-integrate.md b/_partials/_prometheus-integrate.md
index 06f1519296..9a18db415d 100644
--- a/_partials/_prometheus-integrate.md
+++ b/_partials/_prometheus-integrate.md
@@ -1,4 +1,5 @@
import IntegrationPrereqs from "versionContent/_partials/_integration-prereqs.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
[Prometheus][prometheus] is an open-source monitoring system with a dimensional data model, flexible query language, and a modern alerting approach.
@@ -20,6 +21,8 @@ To follow the steps on this page:
- [Install Postgres Exporter][install-exporter].
To reduce latency and potential data transfer costs, install Prometheus and Postgres Exporter on a machine in the same AWS region as your $SERVICE_LONG.
+
+
## Export $SERVICE_LONG telemetry to Prometheus
To export your data, do the following:
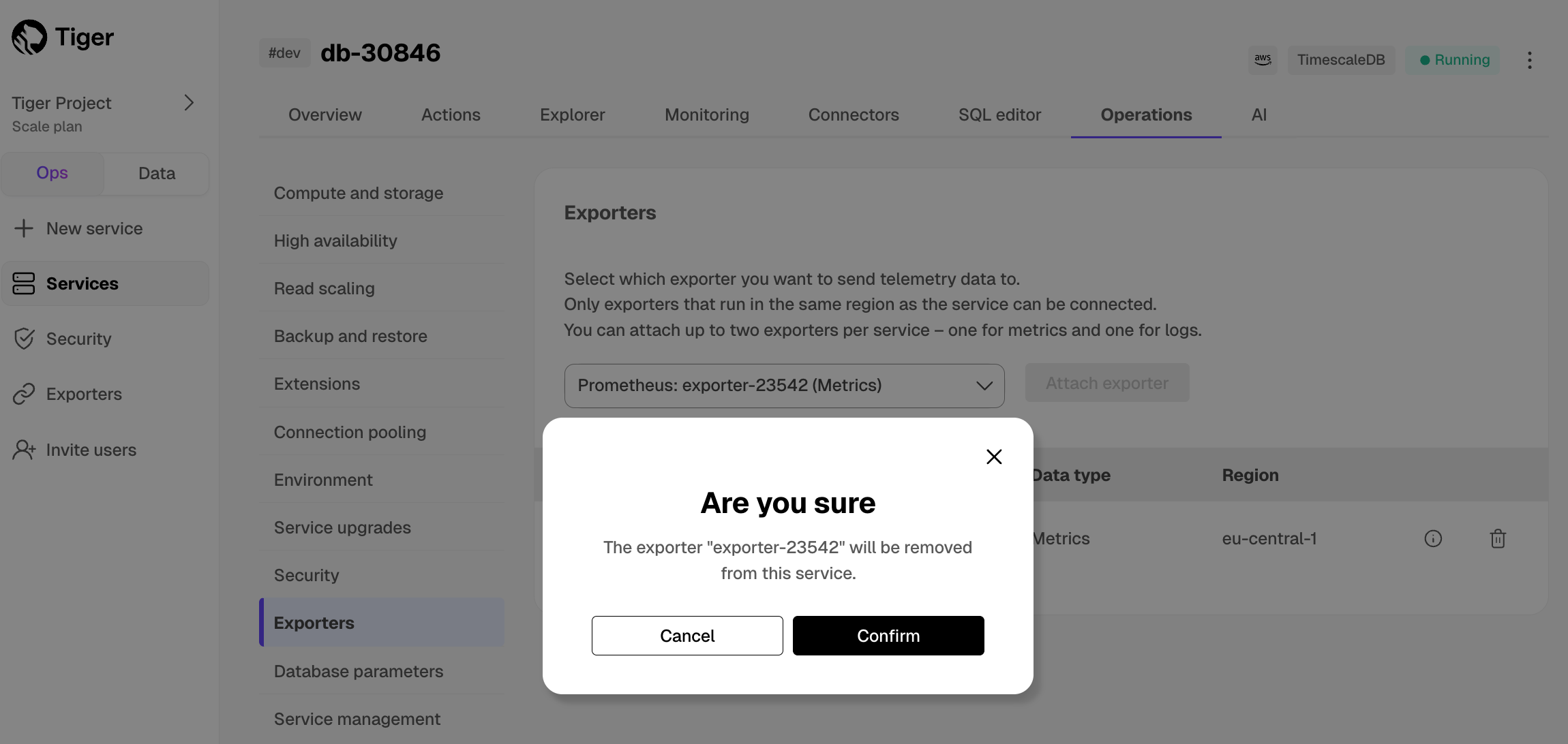
@@ -52,11 +55,11 @@ To export metrics from a $SERVICE_LONG, you create a dedicated Prometheus export
1. Select the exporter in the drop-down, then click `Attach exporter`.
- 
+ 
The exporter is now attached to your $SERVICE_SHORT. To unattach it, click the trash icon in the exporter list.
- 
+ 
1. **Configure the Prometheus scrape target**
diff --git a/_partials/_service-overview-azure.md b/_partials/_service-overview-azure.md
new file mode 100644
index 0000000000..1035dc4ef8
--- /dev/null
+++ b/_partials/_service-overview-azure.md
@@ -0,0 +1,11 @@
+import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
+
+You manage your $SERVICE_LONGs and interact with your data in $CONSOLE using the following modes:
+
+| **$OPS_MODE_CAP** | **$DATA_MODE_CAP** |
+|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| ![$CONSOLE $OPS_MODE][ops-mode] | ![$CONSOLE $DATA_MODE][data-mode] |
+| **You use the $OPS_MODE to:** - Ensure data security with high availability and $READ_REPLICAs
- Save money with columnstore compression
- Enable $PG extensions to add extra functionality
- Perform day-to-day administration
| **Powered by $POPSQL, you use the $DATA_MODE to:** - Write queries with autocomplete
- Visualize data with charts and dashboards
- Schedule queries and dashboards for alerts or recurring reports
- Share queries and dashboards
- Interact with your data on auto-pilot with SQL assistant
|
+
+[ops-mode]: https://assets.timescale.com/docs/images/tiger-on-azure/ops-mode-overview-tiger-cloud-console.png
+[data-mode]: https://assets.timescale.com/docs/images/tiger-cloud-console/tiger-console-data-mode.png
\ No newline at end of file
diff --git a/_partials/_service-overview.md b/_partials/_service-overview.md
index f1dcd41f04..f21c353256 100644
--- a/_partials/_service-overview.md
+++ b/_partials/_service-overview.md
@@ -7,5 +7,5 @@ You manage your $SERVICE_LONGs and interact with your data in $CONSOLE using the
| ![$CONSOLE $OPS_MODE][ops-mode] | ![$CONSOLE $DATA_MODE][data-mode] |
| **You use the $OPS_MODE to:** - Ensure data security with high availability and $READ_REPLICAs
- Save money with columnstore compression and tiered storage
- Enable $PG extensions to add extra functionality
- Increase security using $VPCs
- Perform day-to-day administration
| **Powered by $POPSQL, you use the $DATA_MODE to:** - Write queries with autocomplete
- Visualize data with charts and dashboards
- Schedule queries and dashboards for alerts or recurring reports
- Share queries and dashboards
- Interact with your data on auto-pilot with SQL assistant
|
-[ops-mode]: https://assets.timescale.com/docs/images/tiger-cloud-console/ops-mode-overview-tiger-console.png
+[ops-mode]: https://assets.timescale.com/docs/images/tiger-on-azure/ops-mode-overview-tiger-console.png
[data-mode]: https://assets.timescale.com/docs/images/tiger-cloud-console/tiger-console-data-mode.png
\ No newline at end of file
diff --git a/_partials/_service-users.md b/_partials/_service-users.md
new file mode 100644
index 0000000000..4cd1a274c0
--- /dev/null
+++ b/_partials/_service-users.md
@@ -0,0 +1,18 @@
+By default, when you create a new $SERVICE_SHORT, a new `tsdbadmin` user is created.
+This is the user that you use to connect to your new $SERVICE_SHORT.
+
+
+
+The `tsdbadmin` user is the owner of the database, but is not a superuser. You
+cannot access the `postgres` user. There is no superuser access to $CLOUD_LONG databases.
+
+
+
+In your $SERVICE_SHORT, the `tsdbadmin` user can create another user
+with any other role. For a complete list of roles available, see the
+[$PG role attributes documentation][pg-roles-doc].
+
+You cannot create multiple databases in a single $SERVICE_SHORT. If you need data isolation, use schemas or create additional $SERVICE_SHORTs.
+
+
+[pg-roles-doc]: https://www.postgresql.org/docs/current/role-attributes.html
\ No newline at end of file
diff --git a/_partials/_services-intro-azure.mdx b/_partials/_services-intro-azure.mdx
new file mode 100644
index 0000000000..8dff84aaff
--- /dev/null
+++ b/_partials/_services-intro-azure.mdx
@@ -0,0 +1,53 @@
+import FreeBeta from "versionContent/_partials/_free-plan-beta.mdx";
+
+A $SERVICE_LONG is a single optimized $PG instance extended with innovations in the database engine and cloud
+infrastructure to deliver speed without sacrifice. A $SERVICE_LONG is 10-1000x faster at scale! It
+is ideal for applications requiring strong data consistency, complex relationships, and advanced querying capabilities.
+Get ACID compliance, extensive SQL support, JSON handling, and extensibility through custom functions, data types, and
+extensions.
+
+Each $SERVICE_SHORT is associated with a project in $CLOUD_LONG. Each project can have multiple $SERVICE_SHORTs. Each user is a [member of one or more projects][rbac].
+
+You create free and standard $SERVICE_SHORTs in $CONSOLE_LONG, depending on your [$PRICING_PLAN][pricing-plans]. A free $SERVICE_SHORT comes at zero cost and gives you limited resources to get to know $CLOUD_LONG. Once you are ready to try out more advanced features, you can switch to a paid plan and convert your free $SERVICE_SHORT to a standard one.
+
+
+
+
+
+To the $PG you know and love, $CLOUD_LONG adds the following capabilities:
+
+- **Standard $SERVICE_SHORTs**:
+
+ - _Real-time analytics_: store and query [time-series data][what-is-time-series] at scale for
+ real-time analytics and other use cases. Get faster time-based queries with $HYPERTABLEs, $CAGGs, and columnar storage. Save money by compressing data into the $COLUMNSTORE and deleting old data with automated policies.
+ - _AI-focused_: build AI applications from start to scale. Get fast and accurate similarity search
+ with the pgvector and pgvectorscale extensions.
+ - _Hybrid applications_: get a full set of tools to develop applications that combine time-based data and AI.
+
+ All standard $SERVICE_LONGs include the tooling you expect for production and developer environments: [live migration][live-migration],
+ [automatic backups and PITR][automatic-backups], [high availability][high-availability], [$READ_REPLICAs][readreplica], [data forking][operations-forking], [connection pooling][connection-pooling],
+ [usage-based storage][how-plans-work], secure in-$CONSOLE [SQL editing][in-console-editors], $SERVICE_SHORT [metrics][metrics]
+ and [insights][insights], [streamlined maintenance][maintain-upgrade], and much more. $CLOUD_LONG continuously monitors your $SERVICE_SHORTs and prevents common $PG out-of-memory crashes.
+
+- **Free $SERVICE_SHORTs**:
+
+ _$PG with $TIMESCALE_DB and vector extensions_
+
+ Free $SERVICE_SHORTs offer limited resources and a basic feature scope, perfect to get to know $CLOUD_LONG in a development environment.
+
+[what-is-time-series]: https://www.timescale.com/blog/time-series-database-an-explainer#what-is-a-time-series-database
+[create-service]: /getting-started/:currentVersion:/services/
+[live-migration]: /migrate/:currentVersion:/live-migration/
+[automatic-backups]: /use-timescale/:currentVersion:/backup-restore/
+[high-availability]: /use-timescale/:currentVersion:/ha-replicas/high-availability/
+[readreplica]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/
+[operations-forking]: /use-timescale/:currentVersion:/services/service-management/#fork-a-service
+[connection-pooling]: /use-timescale/:currentVersion:/services/connection-pooling
+[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
+[how-plans-work]: /about/:currentVersion:/pricing-and-account-management/#how-plans-work
+[in-console-editors]: /getting-started/:currentVersion:/run-queries-from-console/
+[metrics]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#metrics
+[insights]: /use-timescale/:currentVersion:/metrics-logging/monitoring/#insights
+[maintain-upgrade]: /use-timescale/:currentVersion:/upgrades/
+[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
+[rbac]: /use-timescale/:currentVersion:/security/members/
\ No newline at end of file
diff --git a/_partials/_services-intro.md b/_partials/_services-intro.md
index bd5bf1f292..f7e5fbd5a4 100644
--- a/_partials/_services-intro.md
+++ b/_partials/_services-intro.md
@@ -1,6 +1,6 @@
import FreeBeta from "versionContent/_partials/_free-plan-beta.mdx";
-A $SERVICE_LONG is a single optimised $PG instance extended with innovations in the database engine and cloud
+A $SERVICE_LONG is a single optimized $PG instance extended with innovations in the database engine and cloud
infrastructure to deliver speed without sacrifice. A $SERVICE_LONG is 10-1000x faster at scale! It
is ideal for applications requiring strong data consistency, complex relationships, and advanced querying capabilities.
Get ACID compliance, extensive SQL support, JSON handling, and extensibility through custom functions, data types, and
diff --git a/_partials/_start-using-cloud-azure.md b/_partials/_start-using-cloud-azure.md
new file mode 100644
index 0000000000..3355d7f343
--- /dev/null
+++ b/_partials/_start-using-cloud-azure.md
@@ -0,0 +1,11 @@
+To start using $CLOUD_LONG for your data:
+
+1. [Create a $ACCOUNT_LONG][create-an-account]: register to get access to $CONSOLE as a centralized point to administer and interact with your data.
+1. [Create a $SERVICE_LONG][create-a-service]: that is, a $PG database instance, powered by [$TIMESCALE_DB][timescaledb], built for production, and extended with cloud features like high-availability replicas.
+1. [Connect to your $SERVICE_LONG][connect-to-your-service]: to run queries, add and migrate your data from other sources.
+
+
+[timescaledb]: https://docs.tigerdata.com/#TimescaleDB
+[connect-to-your-service]: /getting-started/:currentVersion:/services/#connect-to-your-service
+[create-an-account]: /getting-started/:currentVersion:/services/#create-a-tiger-cloud-account
+[create-a-service]: /getting-started/:currentVersion:/services/#create-a-tiger-cloud-service
\ No newline at end of file
diff --git a/_partials/_start-using-cloud.md b/_partials/_start-using-cloud.md
new file mode 100644
index 0000000000..e68247be51
--- /dev/null
+++ b/_partials/_start-using-cloud.md
@@ -0,0 +1,11 @@
+To start using $CLOUD_LONG for your data:
+
+1. [Create a $ACCOUNT_LONG][create-an-account]: register to get access to $CONSOLE as a centralized point to administer and interact with your data.
+1. [Create a $SERVICE_LONG][create-a-service]: that is, a $PG database instance, powered by [$TIMESCALE_DB][timescaledb], built for production, and extended with cloud features like transparent data tiering to object storage.
+1. [Connect to your $SERVICE_LONG][connect-to-your-service]: to run queries, add and migrate your data from other sources.
+
+
+[timescaledb]: https://docs.tigerdata.com/#TimescaleDB
+[connect-to-your-service]: /getting-started/:currentVersion:/services/#connect-to-your-service
+[create-an-account]: /getting-started/:currentVersion:/services/#create-a-tiger-cloud-account
+[create-a-service]: /getting-started/:currentVersion:/services/#create-a-tiger-cloud-service
\ No newline at end of file
diff --git a/_partials/_support-plans.md b/_partials/_support-plans.md
new file mode 100644
index 0000000000..61cbcd1c9c
--- /dev/null
+++ b/_partials/_support-plans.md
@@ -0,0 +1,8 @@
+$COMPANY runs a global support organization with Customer Satisfaction (CSAT) scores above 99%.
+Support covers all timezones, and is fully staffed at weekend hours.
+
+All paid $PRICING_PLANs have free Developer Support through email with a target response time of 1 business
+day; we are often faster. If you need 24x7 responsiveness, talk to us about
+[Production Support][production-support].
+
+[production-support]: https://www.timescale.com/support
\ No newline at end of file
diff --git a/_partials/_timescale-cloud-regions-azure.md b/_partials/_timescale-cloud-regions-azure.md
new file mode 100644
index 0000000000..f15f777a72
--- /dev/null
+++ b/_partials/_timescale-cloud-regions-azure.md
@@ -0,0 +1,6 @@
+$SERVICE_LONGs run in the following Microsoft Azure regions:
+
+| Region | Location |
+|--------|----------|
+| `eastus` | Virginia |
+| `westeurope` | Amsterdam |
diff --git a/_partials/_upgrade-plan-monitor-usage.md b/_partials/_upgrade-plan-monitor-usage.md
new file mode 100644
index 0000000000..0edc6b86b2
--- /dev/null
+++ b/_partials/_upgrade-plan-monitor-usage.md
@@ -0,0 +1,24 @@
+import BillingForInactiveServices from "versionContent/_partials/_billing-for-inactive-services.mdx";
+
+You can upgrade or downgrade between the Free, $PERFORMANCE, and $SCALE plans
+whenever you want using [$CONSOLE][cloud-login]. To downgrade to the Free plan, you must only have free services running in your project.
+
+If you switch your $PRICING_PLAN mid-month,
+your prices are prorated to when you switch. Your $SERVICE_SHORTs are not interrupted when you switch, so
+you can keep working without any hassle. To move to $ENTERPRISE, [get in touch with $COMPANY][contact-company].
+
+## Monitor usage and costs
+
+You keep track of your monthly usage in [$CONSOLE][cloud-billing]. $CONSOLE_SHORT shows your
+resource usage and dashboards with performance insights. This allows you to closely monitor your
+$SERVICE_SHORTs’ performance, and any need to scale your $SERVICE_SHORTs or upgrade your $PRICING_PLAN.
+
+$CONSOLE_SHORT also shows your month-to-date accrued charges, as well as a forecast of your expected
+month-end bill. Your previous invoices are also available as PDFs for download.
+
+
+
+
+[cloud-login]: https://console.cloud.timescale.com/
+[contact-company]: https://www.tigerdata.com/contact/
+[cloud-billing]: https://console.cloud.timescale.com/dashboard/billing/details
\ No newline at end of file
diff --git a/about/feature-comparison.md b/about/feature-comparison.md
new file mode 100644
index 0000000000..17daade53f
--- /dev/null
+++ b/about/feature-comparison.md
@@ -0,0 +1,96 @@
+---
+title: Compare the features in TigerData products
+excerpt: Get an overview of features available in Tiger Cloud vs self-hosted TimescaleDB
+products: [cloud, self_hosted]
+keywords: [TimescaleDB, Tiger Cloud]
+---
+
+# Compare the features in $COMPANY products
+
+The following table compares the features available in $CLOUD_LONG and self-hosted $TDB_COMMUNITY.
+
+| Feature | $CLOUD_LONG on AWS | $CLOUD_LONG on Azure | $TIMESCALE_DB |
+|---------------------------------------------------------------------------------------------------------------------|-------------------------------------------|-------------------------------------|------------------------------|
+| **Best-in-сlass $PG performance** | | | |
+| Automatic partitioning via hypertables for efficient indexes and faster ingest | ✓ | ✓ | ✓ |
+| Continuous aggregates | ✓ | ✓ | ✓ |
+| Time/partition-oriented constraint exclusion for faster queries | ✓ | ✓ | ✓ |
+| Skip scans, ordered appends, custom optimizations for faster `LIMIT` and `DISTINCT` queries | ✓ | ✓ | ✓ |
+| Columnar storage for accelerated scans | ✓ | ✓ | ✓ |
+| Vectorized query execution (SIMD) | ✓ | ✓ | ✓ |
+| Specialized vector indexes for AI applications | ✓ | ✓ | ✓ |
+| $PG_CONNECTOR_CAP | ✓ | ✓ | Manual |
+| $S3_CONNECTOR_CAP | ✓ | ✗ | ✗ |
+| Source Apache Kafka connector | ✓ | ✗ | ✗ |
+| $LAKE_LONG destination connector from $CLOUD_LONG to Iceberg-backed S3 Tables | ✓ | ✗ | ✗ |
+| In-Console CSV, Parquet, and text file imports | ✓ | ✗ | ✗ |
+| **Flexible analysis with full SQL** | | | |
+| Complete $PG ecosystem including all $PG features, connectors, and third-party drivers | ✓ | ✓ | ✓ |
+| Cross-table JOINs for time-series and events tables with relational tables | ✓ | ✓ | ✓ |
+| Rich timestamp and timezone support | ✓ | ✓ | ✓ |
+| Flexible time-bucketing for time-oriented analysis | ✓ | ✓ | ✓ |
+| Advanced hyperfunctions including interpolation, approximation, and visualization functions | ✓ | ✓ | ✓ |
+| Geospatial and vector data types | ✓ | ✓ | ✓ |
+| **Automated data management** | | | |
+| Native compression (up to 98% storage savings) | ✓ | ✓ | ✓ |
+| Columnar storage format with fast scans | ✓ | ✓ | ✓ |
+| Data retention policies | ✓ | ✓ | ✓ |
+| Data tiering with automated policies | ✓ | ✗ | ✗ |
+| Data reordering for efficient disk scans | ✓ | ✓ | ✓ |
+| Data downsampling for efficient historical analysis | ✓ | ✓ | ✓ |
+| Background job scheduler and user-defined jobs | ✓ | ✓ | ✓ |
+| **Enterprise scalability** | | | |
+| Disaggregated compute and storage | ✓ | ✓ | Manual |
+| Dynamic compute resizing | ✓ | ✓ | ✗ |
+| Dynamic disk storage with usage-based pricing | ✓ | ✓ | ✗ |
+| Dynamic I/O provisioning for high-read/ high-write performance | ✓ | ✓ | Manual |
+| Low-cost storage with infinite capacity on S3 | ✓ | ✗ | ✗ |
+| Transparent queries across high-performance and low-cost tiers | ✓ | ✗ | ✗ |
+| Read replicas with load balancing for seamless read scaling | ✓ | ✓ | Manual |
+| Connection pooling for connection scaling | ✓ | ✓ | Manual |
+| Automated resource-aware parameter tuning | ✓ | ✓ | ✗ |
+| Terraform for infrastructure-as-code control | ✓ | ✓ | ✗ |
+| **High availability and reliability** | | | |
+| Multi-AZ deployments for high availability | ✓ | ✓ | Manual |
+| Continuous incremental backup and automated restore | ✓ | ✓ | Manual |
+| Cross-region backup | ✓ | 🔜 | ✗ |
+| Point-in-time recovery and branching | ✓ | ✓ | Manual |
+| Regular database and disk snapshots to enable fast restore | ✓ | ✓ | ✗ |
+| Rapid recovery for all services by fast database restart and remote disk remount | ✓ | ✓ | ✗ |
+| Memory guard protections to avoid database out-of-memory crashes | ✓ | ✓ | ✗ |
+| Decoupled control/data planes for greater resilience | ✓ | ✓ | ✗ |
+| Commercial SLAs | ✓ | ✓ | ✗ |
+| **Automated upgrades and software patching** | | | |
+| Automated upgrades during maintenance windows | ✓ | ✓ | ✗ |
+| Phased, zero-downtime $TIMESCALE_DB and $PG minor upgrades | ✓ | ✓ | ✗ |
+| $PG major version upgrades with forking workflow and disk snapshots to minimize downtime | ✓ | ✓ | ✗ |
+| HA-replica-aware coordinated upgrades | ✓ | ✓ | ✗ |
+| Fleet-wide version and stability monitoring with staged roll-out/roll-back upgrades | ✓ | ✓ | ✗ |
+| **Security and compliance** | | | |
+| SOC 2 Type 2, GDPR, HIPAA certified compliance | ✓ | ✓ | ✗ |
+| Data encryption at rest (both disk and backup) | ✓ | ✓ | Manual |
+| Data encryption in transit | ✓ | ✓ | Manual |
+| Database SSL with fully verifiable certificate chains | ✓ | ✓ | ✗ |
+| Control plane role-based access control | ✓ | ✓ | ✗ |
+| Database role-based access control | ✓ | ✓ | ✓ |
+| Multi-factor authentication | ✓ | ✓ | ✗ |
+| Corporate SSO and SAML | ✓ | ✓ | ✗ |
+| VPC peering | ✓ | ✗ | ✗ |
+| AWS Transit Gateway | ✓ | ✗ | ✗ |
+| Layered database "privilege escalation" protections | ✓ | ✓ | ✗ |
+| Secure SDLC practices and vulnerability scanning, third-party pen testing | ✓ | ✓ | ✗ |
+| **Deep observability** | | | |
+| Operational database visibility to understand performance, uncover regressions, optimize performance | ✓ | ✓ | ✗ |
+| Automated query analysis and statistics | ✓ | ✓ | ✗ |
+| Per-query drill-downs into execution times, row results, plans, memory buffer management, cache performance | ✓ | ✓ | ✗ |
+| In-Console metric visualization and system logs | ✓ | ✓ | ✗ |
+| Exporters to AWS CloudWatch, Prometheus, Datadog | ✓ | ✗ | ✗ |
+| Connection monitoring | ✓ | ✓ | Manual |
+| Connection management | ✓ | ✓ | Manual |
+| **Production-grade support and operations** | | | |
+| 24/7 follow-the-sun support with global support team across APAC, EMEA, and Americas | ✓ | ✓ | [Contact sales](mailto:sales@tigerdata.com) |
+| Production support (severity 1) | ✓ | ✓ | [Contact sales](mailto:sales@tigerdata.com) |
+| Architectural reviews, data modeling, and query optimization and assistance, feature testing, and migration support | ✓ | ✓ | [Contact sales](mailto:sales@tigerdata.com) |
+| 24/7 operational monitoring and control | ✓ | ✓ | [Contact sales](mailto:sales@tigerdata.com) |
+| 98%+ customer satisfaction (CSAT scores) | ✓ | ✓ | [Contact sales](mailto:sales@tigerdata.com) |
+
diff --git a/about/page-index/page-index.js b/about/page-index/page-index.js
index e01ace18cf..eb0cecd59d 100644
--- a/about/page-index/page-index.js
+++ b/about/page-index/page-index.js
@@ -6,7 +6,7 @@ module.exports = [
filePath: "index.md",
pageComponents: ["featured-cards"],
excerpt:
- "Additional information about Tiger Data, including how to contribute, and release notes",
+ "Additional information about Tiger Data products, their features, and supported platforms",
children: [
{
title: "Tiger Data architecture for real-time analytics",
@@ -19,10 +19,15 @@ module.exports = [
href: "pricing-and-account-management",
excerpt: "Pricing plans for Tiger Cloud services",
},
+ {
+ title: "Feature comparison",
+ href: "feature-comparison",
+ excerpt: "Feature comparison for Tiger Cloud and self-hosted TimescaleDB.",
+ },
{
title: "Changelog",
href: "changelog",
- excerpt: "A summary of the latest changes to all Tiger Data products.",
+ excerpt: "A summary of the latest changes to Tiger Cloud",
},
{
title: "TimescaleDB editions",
diff --git a/about/pricing-and-account-management.md b/about/pricing-and-account-management.md
index b2ea4b62a2..75757e0303 100644
--- a/about/pricing-and-account-management.md
+++ b/about/pricing-and-account-management.md
@@ -11,234 +11,123 @@ cloud_ui:
import TieredStorageBilling from "versionContent/_partials/_tiered-storage-billing.mdx";
import EarlyAccessGeneral from "versionContent/_partials/_early_access.mdx";
+import PricingPlansIntro from "versionContent/_partials/_pricing-plans-intro.mdx";
+import CloudFreeTrial from "versionContent/_partials/_cloud-free-trial.mdx";
+import UpgradeMonitor from "versionContent/_partials/_upgrade-plan-monitor-usage.mdx";
+import SupportPlans from "versionContent/_partials/_support-plans.mdx";
+import BillingExample from "versionContent/_partials/_billing-example.mdx";
+import ManagePricing from "versionContent/_partials/_manage-pricing-plan.mdx";
import BillingForInactiveServices from "versionContent/_partials/_billing-for-inactive-services.mdx";
import FreeBeta from "versionContent/_partials/_free-plan-beta.mdx";
+import DisaggregatedComputeStorage from "versionContent/_partials/_disaggregated-compute-storage.mdx";
+import DisaggregatedComputeStorageAzure from "versionContent/_partials/_disaggregated-compute-storage-azure.mdx";
+import AwsFeatures from "versionContent/_partials/_aws-features.mdx";
+import AzureFeatures from "versionContent/_partials/_azure-features.mdx";
# Pricing plans and account management
-As we enhance our offerings and align them with your evolving needs,
-$PRICING_PLANs provide more value, flexibility, and efficiency for your business.
-Whether you're a growing startup or a well-established enterprise, our plans
-are structured to support your journey towards greater success.
+
-
+
-This page explains pricing plans for $CLOUD_LONG, and how to easily manage your $ACCOUNT_LONG.
+
-$PRICING_PLAN_CAPs give you:
+If you create a $ACCOUNT_LONG from AWS Marketplace, the pricing options are pay-as-you-go and annual commit. See [AWS pricing][aws-pricing] for details.
-* **Enhanced performance**: with increased CPU and storage capacities, your apps run smoother and more
- efficiently, even under heavy loads.
-* **Improved scalability**: as your business grows, so do your demands. $PRICING_PLAN_CAPs scale with
- you, they provide the resources and support you need at each stage of your growth. Scale up or down
- based on your current needs, ensuring that you only pay for what you use.
-* **Better support**: access to enhanced support options, including production support and dedicated
- account management, ensures you have the help you need when you need it.
-* **Greater flexibility**: we know that one size doesn't fit all. $PRICING_PLAN_CAPs give you the
- flexibility to choose the features and support levels that best match your business
- and engineering requirements. The ability to add features like $IO_BOOST and customize your $PRICING_PLAN means you can tailor $SERVICE_LONGs to fit your specific needs.
-* **Cost efficiency**: by aligning our pricing with the value delivered, we ensure that you get the most
- out of every dollar spent. Our goal is to help you achieve more with less.
+## Disaggregated, consumption-based compute and storage
-It’s that simple! You don't pay for automated backups or networking costs, such as data ingest or egress.
-There are no per-query fees, nor additional costs to read or write data. It's all completely transparent, easily understood, and up to you.
+
-Using $SELF_LONG and our open-source products is still free.
+## How your bill is calculated
-If you create a $ACCOUNT_LONG from AWS Marketplace, the pricing options are pay-as-you-go and annual commit. See [AWS pricing][aws-pricing] for details.
+
-## Disaggregated, consumption-based compute and storage
+## Use $CLOUD_LONG for free
-With $CLOUD_LONG, you are not limited to pre-set compute and storage. Get as much as you need when
-provisioning your $SERVICE_SHORTs or later, as your needs grow.
+
-* **Compute**: pay only for the compute resources you run. Compute is metered on an hourly
- basis, and you can [scale it up to 64,000 IOPS][change-compute] at any time. You can also [scale out using replicas][read-replication]
- as your application grows. We also provide services to help you lower your compute needs
- while improving query performance. $CLOUD_LONG is very efficient and generally needs less compute than other databases to deliver
- the same performance. The best way to size your needs is to sign up for a free trial and test
- with a realistic workload.
+## Upgrade or downgrade your pricing plans at any time
-* **Storage**: pay only for the storage you consume. You have high-performance storage for more-accessed data, and
-[low-cost bottomless storage in S3][data-tiering] for other data. The high-performance storage offers you up to 64 TB of compressed
-(typically 80-100 TB uncompressed) data and is metered on your average GB consumption per hour. We can help you compress your data by up to 98% so you pay even less.
-For easy upgrades, each $SERVICE_SHORT stores the $TIMESCALE_DB binaries. This contributes up to 900 MB to overall storage, which amounts to less than $.80/month in additional storage costs.
+
-## How your bill is calculated
+## $COMPANY support
-You are billed at the end of each month in arrears. Your monthly invoice
-includes an itemized cost accounting for each $SERVICE_LONG and any additional charges.
+
-$CLOUD_LONG charges are based on consumption and your pricing plan:
+## Charging for HA and read replicas
-- **Compute**: billed and metered on an hourly basis. This means that you are billed for a full hour even if the actual consumption is less. You can scale compute up and down at any time. If the compute config changes mid-hour, you are billed for the config used at the end of that hour.
-- **Storage**: billed and metered on a quarter of an hour basis. Storage grows and shrinks automatically with your data.
+HA and $READ_REPLICAs are both charged at the same rate as your primary $SERVICE_SHORTs, based on the
+compute and primary storage consumed by your replicas. Data tiered to our bottomless storage
+tier is shared by all database replicas; replicas accessing tiered storage do not add to your
+bill.
-For example, over the last month your $SERVICE_LONG has been running compute for 500 hours total:
+## Charging over regions
-- 375 hours with 2 CPU
-- 125 hours 4 CPU
+Storage is priced the same across all regions. However, compute prices vary depending on the
+region. This is because our cloud provider (AWS) prices infrastructure differently based on region.
-and consumed high-performance storage for 720 hours total:
+## Features included in each pricing plan
-- 200 hours with 100 GB
-- 520 hours with 150 GB
+
-**Compute cost** = (`375` x `hourly price for 2 CPU`) + (`125` x `hourly price for 4 CPU`)
+## Manage your $CLOUD_LONG $PRICING_PLAN
-**High-performance storage cost** = (`200` x `100 GB` x `hourly price per GB`) + (`520` x `150 GB` x `hourly price per GB`)
+
-Some add-ons such as tiered storage, HA replicas, and connection pooling may incur
-additional charges. These charges are clearly marked in your billing snapshot in $CONSOLE.
-
-## Use $CLOUD_LONG for free
+## AWS Marketplace pricing
-Are you just starting out with $CLOUD_LONG? On our Free pricing plan, you can create up to 2 zero-cost $SERVICE_SHORTs with [limited resources][plan-features]. When a free $SERVICE_SHORT reaches the resource limit, it converts to a read-only state.
+When you get $CLOUD_LONG at AWS Marketplace, the following pricing options are available:
-
+- **Pay-as-you-go**: your consumption is calculated at the end of the month and included in your AWS invoice. No upfront costs, standard $CLOUD_LONG rates apply.
+- **Annual commit**: your consumption is calculated at the end of the month ensuring predictable pricing and seamless billing through your AWS account. We confirm the contract terms with you before finalizing the commitment.
-Ready to try a more feature-rich paid plan? Activate a 30-day free trial of our $PERFORMANCE (no credit card required) or $SCALE plan. After your trial ends, we may remove your data unless you’ve added a payment method.
+
-After you have completed your 30-day trial period, choose the
-[$PRICING_PLAN][plan-features] that suits your business and engineering needs. And even when you upgrade from the Free pricing plan, you can still have up to 2 zero-cost $SERVICE_SHORTs—or convert the ones you already have into standard ones, to have more resources.
+
-If you want to try out features in a higher $PRICING_PLAN before upgrading, contact us.
+
-## Upgrade or downgrade your pricing plans at any time
+## Disaggregated, consumption-based compute and storage
-You can upgrade or downgrade between the Free, $PERFORMANCE, and $SCALE plans
-whenever you want using [$CONSOLE][cloud-login]. To downgrade to the Free plan, you must only have free services running in your project.
+
-If you switch your $PRICING_PLAN mid-month,
-your prices are prorated to when you switch. Your $SERVICE_SHORTs are not interrupted when you switch, so
-you can keep working without any hassle. To move to $ENTERPRISE, [get in touch with $COMPANY][contact-company].
+## How your bill is calculated
-## Monitor usage and costs
+
-You keep track of your monthly usage in [$CONSOLE][cloud-billing]. $CONSOLE_SHORT shows your
-resource usage and dashboards with performance insights. This allows you to closely monitor your
-$SERVICE_SHORTs’ performance, and any need to scale your $SERVICE_SHORTs or upgrade your $PRICING_PLAN.
+## Use $CLOUD_LONG for free
-$CONSOLE_SHORT also shows your month-to-date accrued charges, as well as a forecast of your expected
-month-end bill. Your previous invoices are also available as PDFs for download.
+
-
+## Upgrade or downgrade your pricing plans at any time
-## $COMPANY support
+
-$COMPANY runs a global support organization with Customer Satisfaction (CSAT) scores above 99%.
-Support covers all timezones, and is fully staffed at weekend hours.
+## $COMPANY support
-All paid $PRICING_PLANs have free Developer Support through email with a target response time of 1 business
-day; we are often faster. If you need 24x7 responsiveness, talk to us about
-[Production Support][production-support].
+
## Charging for HA and read replicas
-HA and $READ_REPLICAs are both charged at the same rate as your primary $SERVICE_SHORTs, based on the
-compute and primary storage consumed by your replicas. Data tiered to our bottomless storage
-tier is shared by all database replicas; replicas accessing tiered storage do not add to your
-bill.
+HA and $READ_REPLICAs are both charged at the same rate as your primary $SERVICE_SHORTs, based on the
+compute and primary storage consumed by your replicas.
## Charging over regions
-Storage is priced the same across all regions. However, compute prices vary depending on the
-region. This is because our cloud provider (AWS) prices infrastructure differently based on region.
+Storage is priced the same across all regions. However, compute prices vary depending on the
+region. This is because our cloud provider prices infrastructure differently based on region.
## Features included in each pricing plan
-The available $PRICING_PLANs are:
-
-* **Free**: for small non-production projects.
-* **$PERFORMANCE**: for cost-focused, smaller projects. No credit card required to start.
-* **$SCALE**: for developers handling critical and demanding apps.
-* **$ENTERPRISE**: for enterprises with mission-critical apps.
-
-
-
-The features included in each [$PRICING_PLAN][pricing-plans] are:
-
-| Feature | Free | $PERFORMANCE | $SCALE | $ENTERPRISE |
-|---------------------------------------------------------------|-----------------------------------|----------------------------------------|------------------------------------------------|--------------------------------------------------|
-| **Compute and storage** | | | | |
-| Number of $SERVICE_SHORTs | Up to 2 free services | Up to 2 free and 4 standard services | Up to 2 free and and unlimited standard services | Up to 2 free and and unlimited standard services |
-| CPU limit per $SERVICE_SHORT | Shared | Up to 8 CPU | Up to 32 CPU | Up to 64 CPU |
-| Memory limit per $SERVICE_SHORT | Shared | Up to 32 GB | Up to 128 GB | Up to 256 GB |
-| Storage limit per $SERVICE_SHORT | 750 MB | Up to 16 TB | Up to 16 TB | Up to 64 TB |
-| Bottomless storage on S3 | | | Unlimited | Unlimited |
-| Independently scale compute and storage | | Standard services only | Standard services only | Standard services only |
-| **Data services and workloads** | | | |
-| Relational | ✓ | ✓ | ✓ | ✓ |
-| Time-series | ✓ | ✓ | ✓ | ✓ |
-| Vector search | ✓ | ✓ | ✓ | ✓ |
-| AI workflows (coming soon) | ✓ | ✓ | ✓ | ✓ |
-| Cloud SQL editor | 3 seats | 3 seats | 10 seats | 20 seats |
-| Charts | ✓ | ✓ | ✓ | ✓ |
-| Dashboards | | 2 | Unlimited | Unlimited |
-| **Storage and performance** | | | | |
-| IOPS | Shared | 3,000 - 5,000 | 5,000 - 8,000 | 5,000 - 8,000 |
-| Bandwidth (autoscales) | Shared | 125 - 250 Mbps | 250 - 500 Mbps | Up to 500 mbps |
-| I/O boost | | | Add-on:
Up to 16K IOPS, 1000 Mbps BW | Add-on:
Up to 32K IOPS, 4000 Mbps BW |
-| **Availability and monitoring** | | | | |
-| High-availability replicas
(Automated multi-AZ failover) | | ✓ | ✓ | ✓ |
-| Read replicas | | | ✓ | ✓ |
-| Cross-region backup | | | | ✓ |
-| Backup reports | | | 14 days | 14 days |
-| Point-in-time recovery and forking | 1 day | 3 days | 14 days | 14 days |
-| Performance insights | Limited | ✓ | ✓ | ✓ |
-| Metrics and log exporters | | | ✓ | ✓ |
-| **Security and compliance** | | | | |
-| Role-based access | ✓ | ✓ | ✓ | ✓ |
-| End-to-end encryption | ✓ | ✓ | ✓ | ✓ |
-| Private Networking (VPC) | | 1 multi-attach VPC | Unlimited multi-attach VPCs | Unlimited multi-attach VPCs |
-| AWS Transit Gateway | | | ✓ | ✓ |
-| [HIPAA compliance][hipaa-compliance] | | | | ✓ |
-| IP address allow list | 1 list with up to 10 IP addresses | 1 list with up to 10 IP addresses | Up to 10 lists with up to 10 IP addresses each | Up to 10 lists with up to 100 IP addresses each |
-| Multi-factor authentication | ✓ | ✓ | ✓ | ✓ |
-| Federated authentication (SAML) | | | | ✓ |
-| SOC 2 Type 2 report | | | ✓ | ✓ |
-| Penetration testing report | | | | ✓ |
-| Security questionnaire and review | | | | ✓ |
-| Pay by invoice | | Available at minimum spend | Available at minimum spend | ✓ |
-| [Uptime SLAs][commercial-sla] | | Standard | Standard | Enterprise |
-| **Support and technical services** | | | | |
-| Community support | ✓ | ✓ | ✓ | ✓ |
-| Email support | | ✓ | ✓ | ✓ |
-| Production support | | Add-on | Add-on | ✓ |
-| Named account manager | | | | ✓ |
-| JOIN services (Jumpstart Onboarding and INtegration) | | | Available at minimum spend | ✓ |
-
-For a personalized quote, [get in touch with $COMPANY][contact-company].
+
## Manage your $CLOUD_LONG $PRICING_PLAN
-You handle all details about your $CLOUD_LONG project including updates to your $PRICING_PLAN,
-payment methods, and add-ons in the [billing section in $CONSOLE][cloud-billing]:
-
-![]() -
-- **Details**: an overview of your $PRICING_PLAN, usage, and payment details. You can add up
- to three credit cards to your `Wallet`. If you prefer to pay by invoice,
- [contact $COMPANY][contact-company] and ask to change to corporate billing.
+
-- **History**: the list of your downloadable $CLOUD_LONG invoices.
-- **Emails**: the addresses $COMPANY uses to communicate with you. Payment
- confirmations and alerts are sent to the email address you signed up with.
- Add another address to send details to other departments in your organization.
+
-- **$PRICING_PLAN_CAP**: choose the $PRICING_PLAN supplying the [features][plan-features] that suit your business and
- engineering needs.
-
-- **Add-ons**: add `Production support` and improved database performance for mission-critical workloads.
-
-## AWS Marketplace pricing
-
-When you get $CLOUD_LONG at AWS Marketplace, the following pricing options are available:
-
-- **Pay-as-you-go**: your consumption is calculated at the end of the month and included in your AWS invoice. No upfront costs, standard $CLOUD_LONG rates apply.
-- **Annual commit**: your consumption is calculated at the end of the month ensuring predictable pricing and seamless billing through your AWS account. We confirm the contract terms with you before finalizing the commitment.
+
[cloud-login]: https://console.cloud.timescale.com/
[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
diff --git a/about/supported-platforms.md b/about/supported-platforms.md
index 59ebde05d0..e1bbb9b10a 100644
--- a/about/supported-platforms.md
+++ b/about/supported-platforms.md
@@ -8,6 +8,7 @@ tags: [platforms, os, versions]
import ServiceTypes from "versionContent/_partials/_timescale-cloud-services.mdx";
import Regions from "versionContent/_partials/_timescale-cloud-regions.mdx";
+import RegionsAzure from "versionContent/_partials/_timescale-cloud-regions-azure.mdx";
import Platforms from "versionContent/_partials/_timescale-cloud-platforms.mdx";
# Supported platforms and regions
@@ -32,16 +33,26 @@ See the available [service capabilities][service-types] and [regions][regions].
### Available service capabilities
-
-
### Available regions
-
+
+
+
+
+
+
+
+
+
+
+
+
+
## Self-hosted products
diff --git a/getting-started/get-started-devops-as-code.md b/getting-started/get-started-devops-as-code.md
index 27bac9b31a..fc2a56d2fe 100644
--- a/getting-started/get-started-devops-as-code.md
+++ b/getting-started/get-started-devops-as-code.md
@@ -11,6 +11,7 @@ tags:
- security
- services
- authentication
+products: [cloud]
---
import RESTGS from "versionContent/_partials/_devops-rest-api-get-started.mdx";
diff --git a/getting-started/run-queries-from-console.md b/getting-started/run-queries-from-console.md
index d7623814d3..bdbee2e8c2 100644
--- a/getting-started/run-queries-from-console.md
+++ b/getting-started/run-queries-from-console.md
@@ -57,7 +57,7 @@ To connect to a $SERVICE_SHORT:
In [$CONSOLE][services-portal], check that your $SERVICE_SHORT is marked as `Running`:
- 
+ 
1. **Connect to your $SERVICE_SHORT**
@@ -213,7 +213,7 @@ $SQL_ASSISTANT_SHORT settings are:
$SQL_EDITOR is an integrated secure UI that you use to run queries and see the results
for a $SERVICE_LONG.
-
+
To enable or disable $SQL_EDITOR in your $SERVICE_SHORT, click `Operations` > `Service management`, then
update the setting for $SQL_EDITOR.
@@ -226,13 +226,13 @@ To use $SQL_EDITOR:
In the [$OPS_MODE][portal-ops-mode] in $CONSOLE, select a $SERVICE_SHORT, then click `SQL editor`.
- 
+ 
1. **Run a test query**
Type `SELECT CURRENT_DATE;` in the UI and click `Run`. The results appear in the lower window:
- 
+ 
diff --git a/getting-started/services.md b/getting-started/services.md
index c3e93a5f57..1f1c8ce2ae 100644
--- a/getting-started/services.md
+++ b/getting-started/services.md
@@ -5,15 +5,26 @@ products: [cloud]
content_group: Getting started
---
-import Install from "versionContent/_partials/_cloud-installation.mdx";
-import Connect from "versionContent/_partials/_cloud-connect-service.mdx";
+import CloudIntro from "versionContent/_partials/_cloud-intro.mdx";
import ServiceIntro from "versionContent/_partials/_services-intro.mdx";
import ServiceOverview from "versionContent/_partials/_service-overview.mdx";
-import CloudIntro from "versionContent/_partials/_cloud-intro.mdx";
+import StartUsingCloud from "versionContent/_partials/_start-using-cloud.mdx";
+import Install from "versionContent/_partials/_cloud-installation.mdx";
+import CreateService from "versionContent/_partials/_create-service.mdx";
+import Connect from "versionContent/_partials/_cloud-connect-service.mdx";
import WhereNext from "versionContent/_partials/_where-to-next.mdx";
+import InstallAzure from "versionContent/_partials/_cloud-installation-azure.mdx";
+import ServiceIntroAzure from "versionContent/_partials/_services-intro-azure.mdx";
+import ServiceOverviewAzure from "versionContent/_partials/_service-overview-azure.mdx";
+import StartUsingCloudAzure from "versionContent/_partials/_start-using-cloud-azure.mdx";
+
# Create a $SERVICE_LONG
+
+
+
+
## What is a $SERVICE_LONG?
@@ -22,39 +33,49 @@ import WhereNext from "versionContent/_partials/_where-to-next.mdx";
-To start using $CLOUD_LONG for your data:
+
-1. [Create a $ACCOUNT_LONG][create-an-account]: register to get access to $CONSOLE as a centralized point to administer and interact with your data.
-1. [Create a $SERVICE_LONG][create-a-service]: that is, a $PG database instance, powered by [$TIMESCALE_DB][timescaledb], built for production, and extended with cloud features like transparent data tiering to object storage.
-1. [Connect to your $SERVICE_LONG][connect-to-your-service]: to run queries, add and migrate your data from other sources.
+## Create a $ACCOUNT_LONG
-## Create a $SERVICE_LONG
+## Create a $SERVICE_SHORT
Now that you have an active $ACCOUNT_LONG, you create and manage your $SERVICE_SHORTs in $CONSOLE. When you create a $SERVICE_SHORT, you effectively create a blank $PG database with additional $CLOUD_LONG features available under your $PRICING_PLAN. You then add or migrate your data into this database.
-To create a free or standard $SERVICE_SHORT:
+
+
+## Connect to your $SERVICE_SHORT
+
+To run queries and perform other operations, connect to your $SERVICE_SHORT:
+
+
+
+
+
+
-
+
-1. In the [$SERVICE_SHORT creation page][create-service], click `+ New service`.
+
+
+## What is a $SERVICE_LONG?
- Follow the wizard to configure your $SERVICE_SHORT depending on its type.
-
-1. Click `Create service`.
+
- Your $SERVICE_SHORT is constructed and ready to use in a few seconds.
+
-1. Click `Download the config` and store the configuration information you need to connect to this $SERVICE_SHORT in a secure location.
+
- This file contains the passwords and configuration information you need to connect to your $SERVICE_SHORT using the
- $CONSOLE $DATA_MODE, from the command line, or using third-party database administration tools.
+## Create a $ACCOUNT_LONG
-If you choose to go directly to the $SERVICE_SHORT overview, [Connect to your $SERVICE_SHORT][connect-to-your-service]
-shows you how to connect.
+
-
+## Create a $SERVICE_SHORT
+
+Now that you have an active $ACCOUNT_LONG, you create and manage your $SERVICE_SHORTs in $CONSOLE. When you create a $SERVICE_SHORT, you effectively create a blank $PG database with additional $CLOUD_LONG features available under your $PRICING_PLAN. You then add or migrate your data into this database.
+
+
## Connect to your $SERVICE_SHORT
@@ -64,6 +85,9 @@ To run queries and perform other operations, connect to your $SERVICE_SHORT:
+
+
+
[tsc-portal]: https://console.cloud.timescale.com/
[services-how-to]: /use-timescale/:currentVersion:/services/
diff --git a/getting-started/try-key-features-timescale-products.md b/getting-started/try-key-features-timescale-products.md
index 09acb528a0..13151c0b03 100644
--- a/getting-started/try-key-features-timescale-products.md
+++ b/getting-started/try-key-features-timescale-products.md
@@ -211,7 +211,7 @@ For example, yesterday's market data.
90%. This helps you save on storage costs and keeps your queries operating at lightning speed. To see the amount of space
saved, click `Explorer` > `public` > `crypto_ticks`.
- 
+ 
@@ -360,7 +360,7 @@ To set up data tiering:
1. In `Explorer`, click `Storage configuration` > `Tiering storage`, then click `Enable tiered storage`.
- 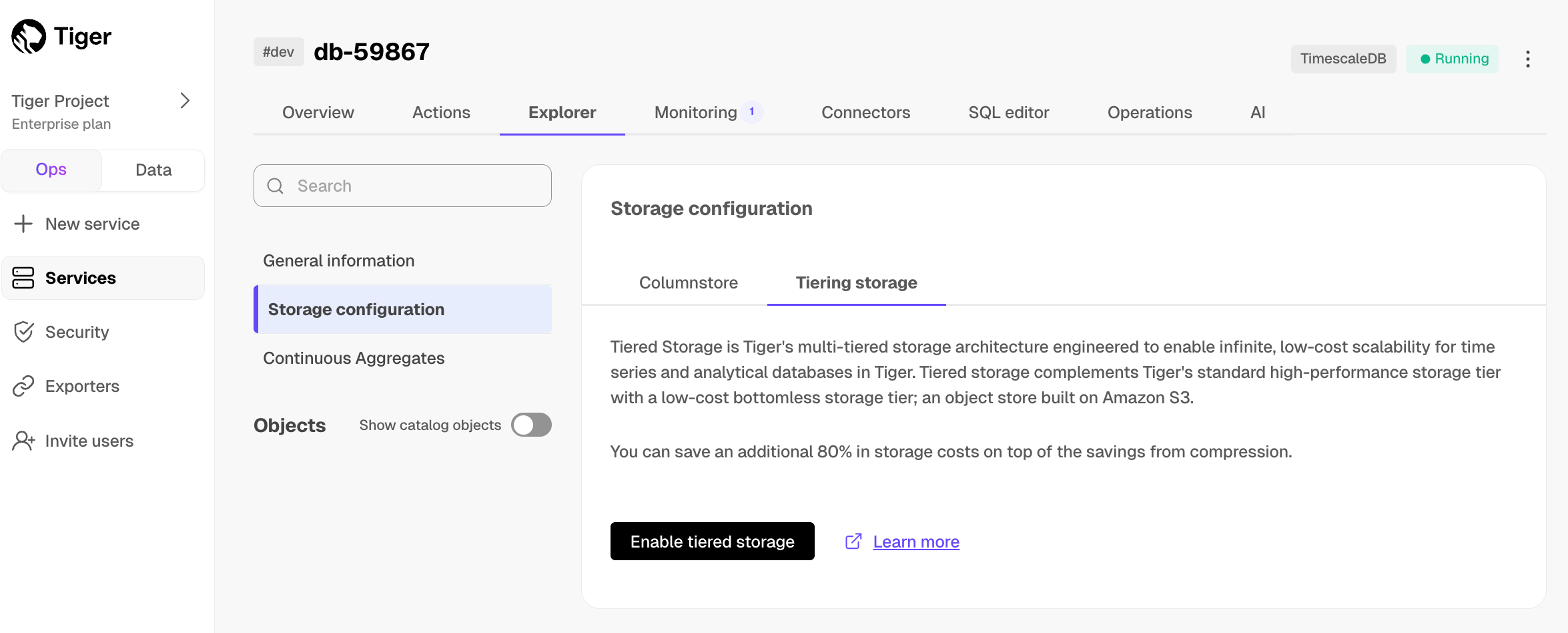
+ 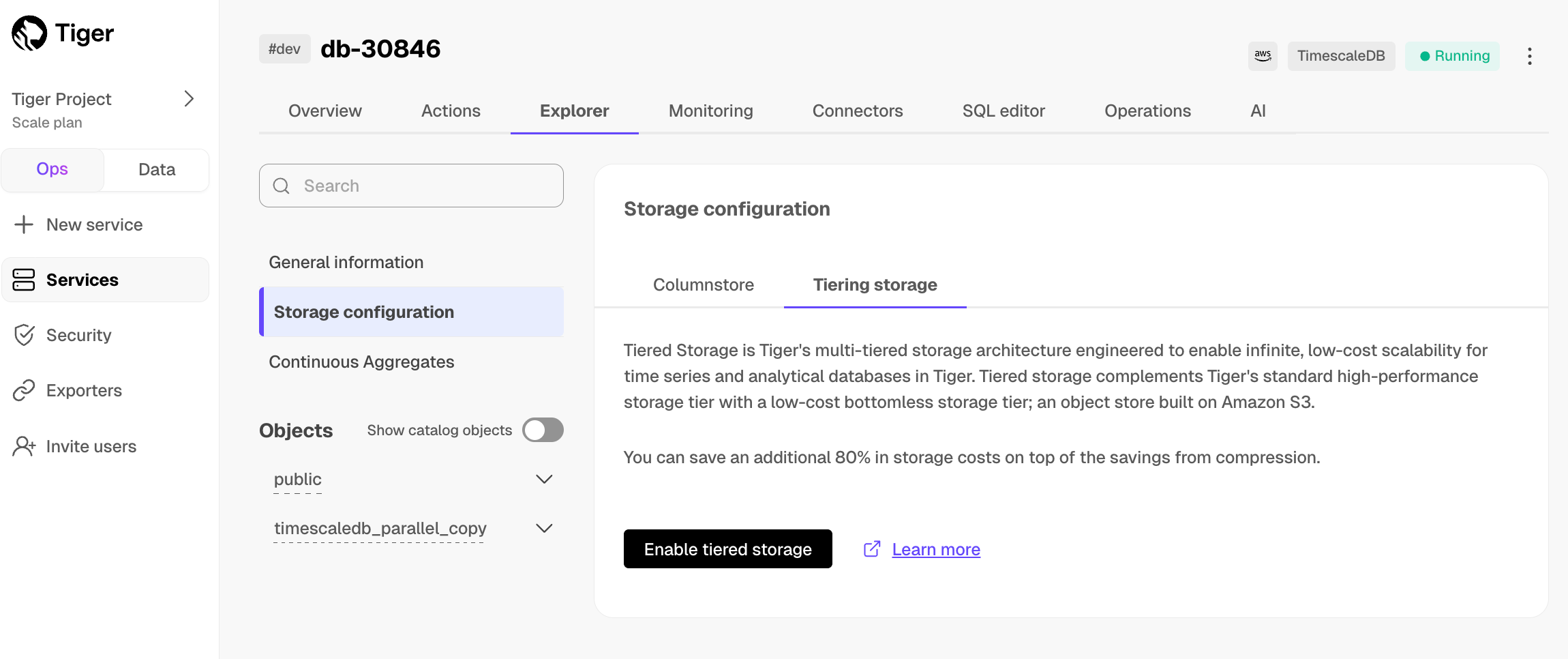
When tiered storage is enabled, you see the amount of data in the tiered object storage.
diff --git a/integrations/aws.md b/integrations/aws.md
index ab828ef7df..13e2f0662a 100644
--- a/integrations/aws.md
+++ b/integrations/aws.md
@@ -8,9 +8,11 @@ keywords: [AWS, integrations]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Amazon Web Services with $CLOUD_LONG
+
[Amazon Web Services (AWS)][aws] is a comprehensive cloud computing platform that provides on-demand infrastructure, storage, databases, AI, analytics, and security services to help businesses build, deploy, and scale applications in the cloud.
This page explains how to integrate your AWS infrastructure with $CLOUD_LONG using [AWS Transit Gateway][aws-transit-gateway].
@@ -21,6 +23,8 @@ This page explains how to integrate your AWS infrastructure with $CLOUD_LONG usi
- Set up [AWS Transit Gateway][gtw-setup].
+
+
## Connect your AWS infrastructure to your $SERVICE_LONGs
To connect to $CLOUD_LONG:
@@ -33,6 +37,11 @@ To connect to $CLOUD_LONG:
You have successfully integrated your AWS infrastructure with $CLOUD_LONG.
+
+
+
+
+
[aws]: https://aws.amazon.com/
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[gtw-setup]: https://docs.aws.amazon.com/vpc/latest/tgw/tgw-getting-started.html
diff --git a/integrations/cloudwatch.md b/integrations/cloudwatch.md
index b8aafa5488..58722a9b32 100644
--- a/integrations/cloudwatch.md
+++ b/integrations/cloudwatch.md
@@ -6,6 +6,7 @@ price_plans: [scale, enterprise]
keywords: [integrate]
---
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import CloudWatchExporter from "versionContent/_partials/_cloudwatch-data-exporter.mdx";
import ManageDataExporter from "versionContent/_partials/_manage-a-data-exporter.mdx";
@@ -24,6 +25,8 @@ This pages explains how to export telemetry data from your $SERVICE_LONG into Cl
- Sign up for [Amazon CloudWatch][cloudwatch-signup].
+
+
## Create a data exporter
A $CLOUD_LONG data exporter sends telemetry data from a $SERVICE_LONG to a third-party monitoring
@@ -33,6 +36,9 @@ tool. You create an exporter on the [project level][projects], in the same AWS r
+
+
+
[projects]: /use-timescale/:currentVersion:/security/members/
[pricing-plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-pricing-plan
[cloudwatch]: https://aws.amazon.com/cloudwatch/
diff --git a/integrations/corporate-data-center.md b/integrations/corporate-data-center.md
index c95fed50be..f097a6f454 100644
--- a/integrations/corporate-data-center.md
+++ b/integrations/corporate-data-center.md
@@ -8,6 +8,7 @@ keywords: [on-premise, integrations]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate your data center with $CLOUD_LONG
@@ -18,6 +19,7 @@ This page explains how to integrate your corporate on-premise infrastructure wit
- Set up [AWS Transit Gateway][gtw-setup].
+
## Connect your on-premise infrastructure to your $SERVICE_LONGs
@@ -33,7 +35,11 @@ To connect to $CLOUD_LONG:
-You have successfully integrated your Microsoft Azure infrastructure with $CLOUD_LONG.
+You have successfully integrated your corporate data center with $CLOUD_LONG.
+
+
+
+
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[gtw-setup]: https://docs.aws.amazon.com/vpc/latest/tgw/tgw-getting-started.html
diff --git a/integrations/datadog.md b/integrations/datadog.md
index ccd4219fc9..005f9c063f 100644
--- a/integrations/datadog.md
+++ b/integrations/datadog.md
@@ -9,6 +9,7 @@ keywords: [integrate]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import DataDogExporter from "versionContent/_partials/_datadog-data-exporter.mdx";
import ManageDataExporter from "versionContent/_partials/_manage-a-data-exporter.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Datadog with $CLOUD_LONG
@@ -36,6 +37,8 @@ This page explains how to:
- Install [Datadog Agent][datadog-agent-install].
+
+
## Monitor $SERVICE_LONG metrics with Datadog
Export telemetry data from your $SERVICE_LONGs with the time-series and analytics capability enabled to
@@ -132,6 +135,9 @@ metrics about your $SERVICE_LONGs.
Metrics for your $SERVICE_LONG are now visible in Datadog. Check the Datadog $PG integration documentation for a
comprehensive list of [metrics][datadog-postgres-metrics] collected.
+
+
+
[datadog]: https://www.datadoghq.com/
[datadog-agent-install]: https://docs.datadoghq.com/getting_started/agent/#installation
[datadog-postgres]: https://docs.datadoghq.com/integrations/postgres/
diff --git a/integrations/find-connection-details.md b/integrations/find-connection-details.md
index b92685f636..eccfbd5f4e 100644
--- a/integrations/find-connection-details.md
+++ b/integrations/find-connection-details.md
@@ -44,12 +44,12 @@ To retrieve the connection details for your $PROJECT_LONG and $SERVICE_LONG:
1. **Retrieve your project ID**:
In [$CONSOLE][console-services], click your project name in the upper left corner, then click `Copy` next to the project ID.
- 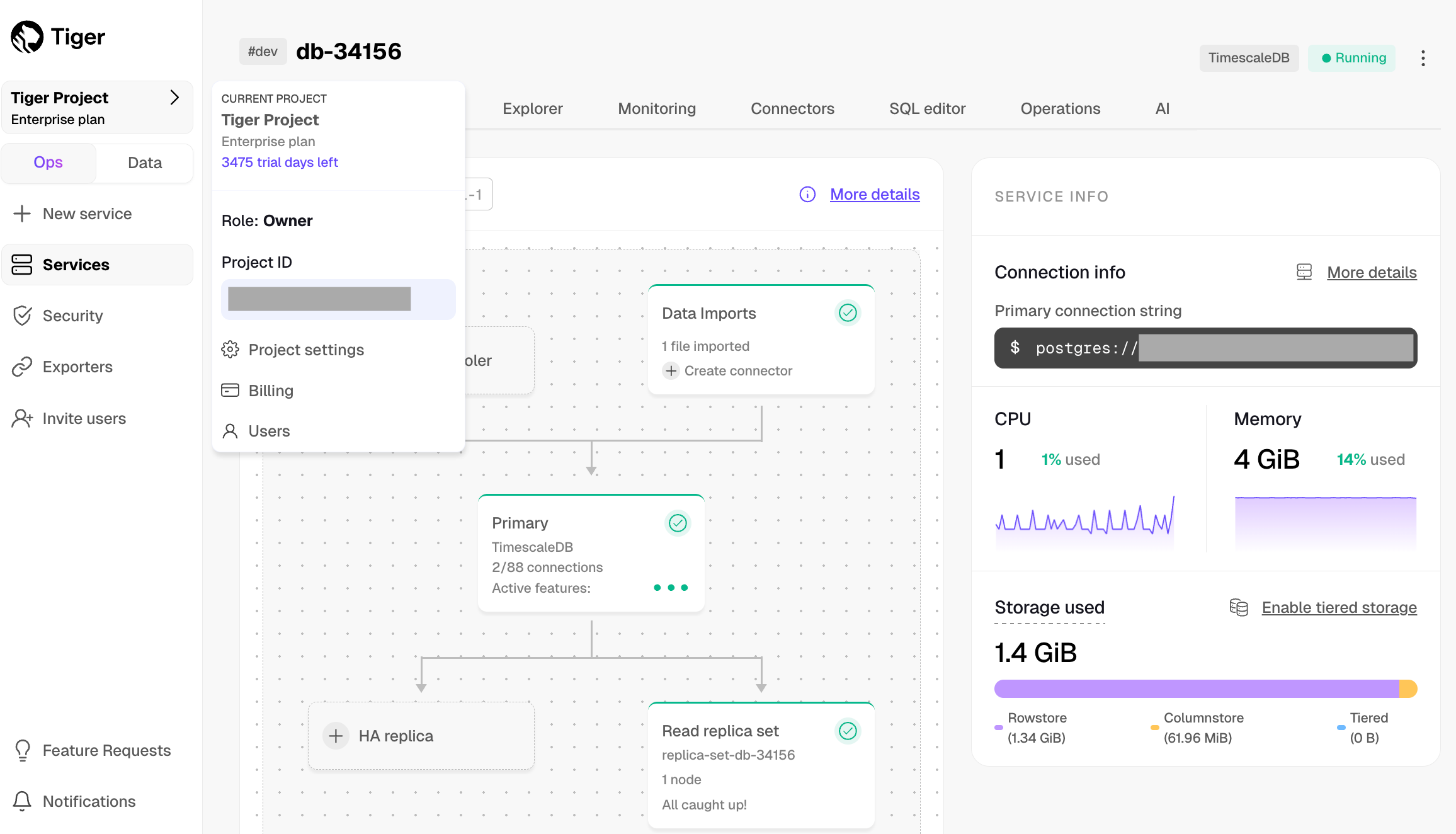
+ 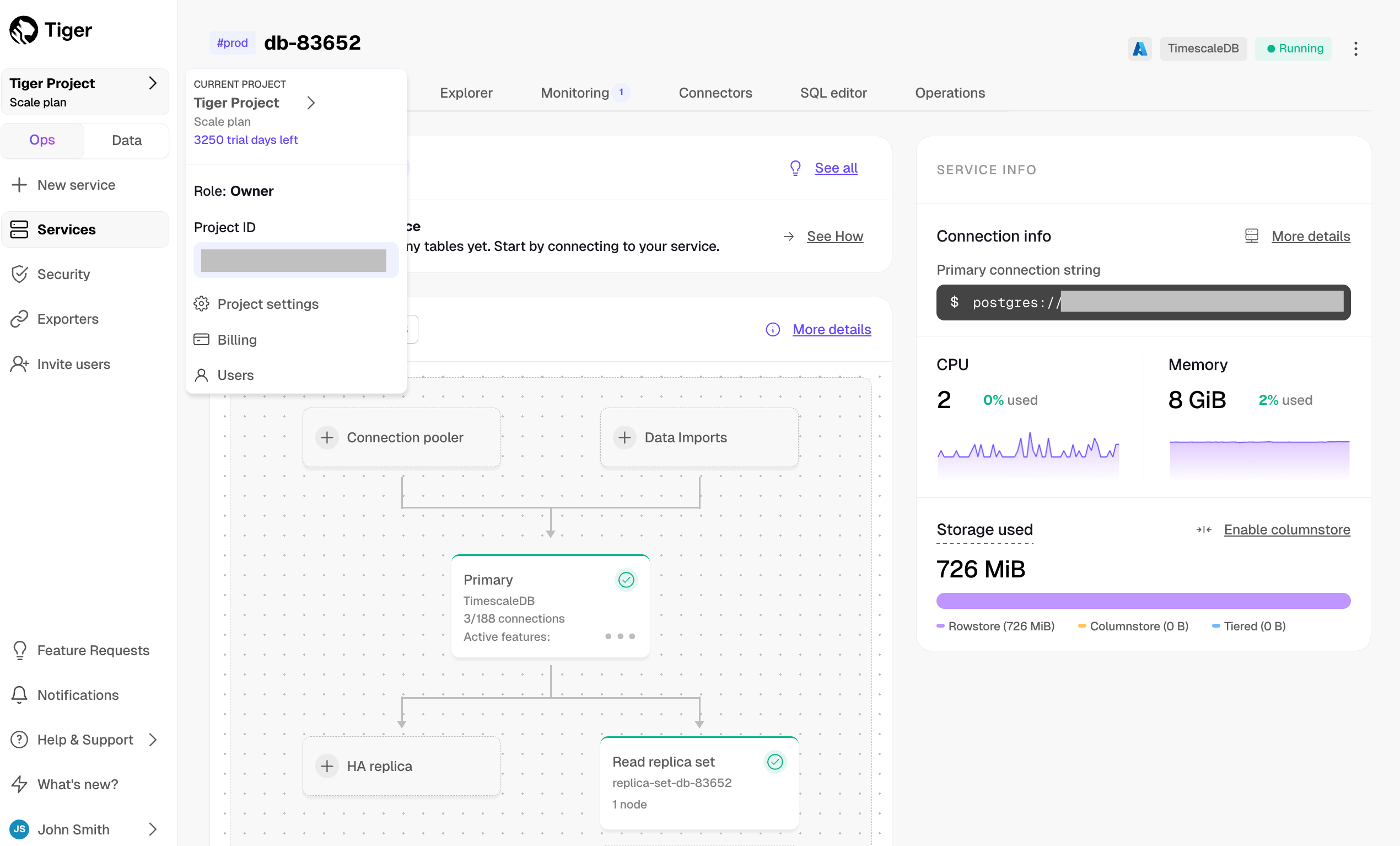
1. **Retrieve your service ID**:
Click the dots next to the service, then click `Copy` next to the service ID.
- 
+ 
diff --git a/integrations/google-cloud.md b/integrations/google-cloud.md
index 83f7cf095b..a0659da661 100644
--- a/integrations/google-cloud.md
+++ b/integrations/google-cloud.md
@@ -8,6 +8,7 @@ keywords: [Google Cloud, integrations]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Google Cloud with $CLOUD_LONG
@@ -20,6 +21,7 @@ This page explains how to integrate your Google Cloud infrastructure with $CLOUD
- Set up [AWS Transit Gateway][gtw-setup].
+
## Connect your Google Cloud infrastructure to your $SERVICE_LONGs
@@ -37,6 +39,12 @@ To connect to $CLOUD_LONG:
You have successfully integrated your Google Cloud infrastructure with $CLOUD_LONG.
+
+
+
+
+
+
[google-cloud]: https://cloud.google.com/?hl=en
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[gtw-setup]: https://docs.aws.amazon.com/vpc/latest/tgw/tgw-getting-started.html
diff --git a/integrations/microsoft-azure.md b/integrations/microsoft-azure.md
index 0be270d87a..7787d04279 100644
--- a/integrations/microsoft-azure.md
+++ b/integrations/microsoft-azure.md
@@ -8,9 +8,11 @@ keywords: [Azure, integrations]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Microsoft Azure with $CLOUD_LONG
+
[Microsoft Azure][azure] is a cloud computing platform and services suite, offering infrastructure, AI, analytics, security, and developer tools to help businesses build, deploy, and manage applications.
This page explains how to integrate your Microsoft Azure infrastructure with $CLOUD_LONG using [AWS Transit Gateway][aws-transit-gateway].
@@ -20,6 +22,7 @@ This page explains how to integrate your Microsoft Azure infrastructure with $CL
- Set up [AWS Transit Gateway][gtw-setup].
+
## Connect your Microsoft Azure infrastructure to your $SERVICE_LONGs
@@ -37,6 +40,10 @@ To connect to $CLOUD_LONG:
You have successfully integrated your Microsoft Azure infrastructure with $CLOUD_LONG.
+
+
+
+
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[gtw-setup]: https://docs.aws.amazon.com/vpc/latest/tgw/tgw-getting-started.html
[azure]: https://azure.microsoft.com/en-gb/
diff --git a/integrations/prometheus.md b/integrations/prometheus.md
index ae4a61531d..11d85e1080 100644
--- a/integrations/prometheus.md
+++ b/integrations/prometheus.md
@@ -7,7 +7,9 @@ keywords: [integrate]
---
import PrometheusIntegrate from "versionContent/_partials/_prometheus-integrate.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Prometheus with $CLOUD_LONG
-
\ No newline at end of file
+
+
diff --git a/migrate/livesync-for-kafka.md b/migrate/livesync-for-kafka.md
index de2b713f53..af08ad025a 100644
--- a/migrate/livesync-for-kafka.md
+++ b/migrate/livesync-for-kafka.md
@@ -9,12 +9,13 @@ tags: [stream, connector]
import PrereqCloud from "versionContent/_partials/_prereqs-cloud-only.mdx";
import EarlyAccessNoRelease from "versionContent/_partials/_early_access.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Stream data from Kafka
You use the Kafka source connector in $CLOUD_LONG to stream events from Kafka into your $SERVICE_SHORT. $CLOUD_LONG connects to your Confluent Cloud Kafka cluster and Schema Registry using SASL/SCRAM authentication and service account–based API keys. Only the Avro format is currently supported [with some limitations][limitations].
-This page explains how to connect $CLOUD_LONG to your Confluence Cloud Kafka cluster.
+This page explains how to connect $CLOUD_LONG to your Confluent Cloud Kafka cluster.
: the Kafka source connector is not yet supported for production use.
@@ -25,6 +26,8 @@ This page explains how to connect $CLOUD_LONG to your Confluence Cloud Kafka clu
- [Sign up][confluence-signup] for Confluence Cloud.
- [Create][create-kafka-cluster] a Kafka cluster in Confluence Cloud.
+
+
## Access your Kafka cluster in Confluent Cloud
Take the following steps to prepare your Kafka cluster for connection to $CLOUD_LONG:
diff --git a/migrate/livesync-for-postgresql.md b/migrate/livesync-for-postgresql.md
index 2a4d4c9331..844ecdf767 100644
--- a/migrate/livesync-for-postgresql.md
+++ b/migrate/livesync-for-postgresql.md
@@ -20,7 +20,7 @@ $SERVICE_SHORT, in real time. You run the connector continuously, turning $PG in
$SERVICE_SHORT as a logical replica. This enables you to leverage $CLOUD_LONG’s real-time analytics capabilities on
your replica data.
-
+
The $PG_CONNECTOR in $CLOUD_LONG leverages the well-established $PG logical replication protocol. By relying on this protocol,
$CLOUD_LONG ensures compatibility, familiarity, and a broader knowledge base—making it easier for you to adopt the connector
diff --git a/migrate/livesync-for-s3.md b/migrate/livesync-for-s3.md
index 42406175ce..b5c9e91ae1 100644
--- a/migrate/livesync-for-s3.md
+++ b/migrate/livesync-for-s3.md
@@ -9,12 +9,13 @@ tags: [recovery, logical backup, replication]
import PrereqCloud from "versionContent/_partials/_prereqs-cloud-only.mdx";
import EarlyAccessNoRelease from "versionContent/_partials/_early_access.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Sync data from S3
You use the $S3_CONNECTOR in $CLOUD_LONG to synchronize CSV and Parquet files from an S3 bucket to your $SERVICE_LONG in real time. The connector runs continuously, enabling you to leverage $CLOUD_LONG as your analytics database with data constantly synced from S3. This lets you take full advantage of $CLOUD_LONG's real-time analytics capabilities without having to develop or manage custom ETL solutions between S3 and $CLOUD_LONG.
-
+
You can use the $S3_CONNECTOR to synchronize your existing and new data. Here's what the connector can do:
@@ -63,6 +64,8 @@ The $S3_CONNECTOR continuously imports data from an Amazon S3 bucket into your d
- [Public anonymous user][credentials-public].
+
+
## Limitations
- **File naming**:
@@ -100,7 +103,7 @@ To sync data from your S3 bucket to your $SERVICE_LONG using $CONSOLE:
1. **Connect the source S3 bucket to the target $SERVICE_SHORT**
- 
+ 
1. Click `Connectors` > `Amazon S3`.
1. Click the pencil icon, then set the name for the new connector.
@@ -137,18 +140,18 @@ To sync data from your S3 bucket to your $SERVICE_LONG using $CONSOLE:
1. To view the amount of data replicated, click `Connectors`. The diagram in `Connector data flow` gives you an overview of the connectors you have created, their status, and how much data has been replicated.
- 
+ 
1. To view file import statistics and logs, click `Connectors` > `Source connectors`, then select the name of your connector in the table.
- 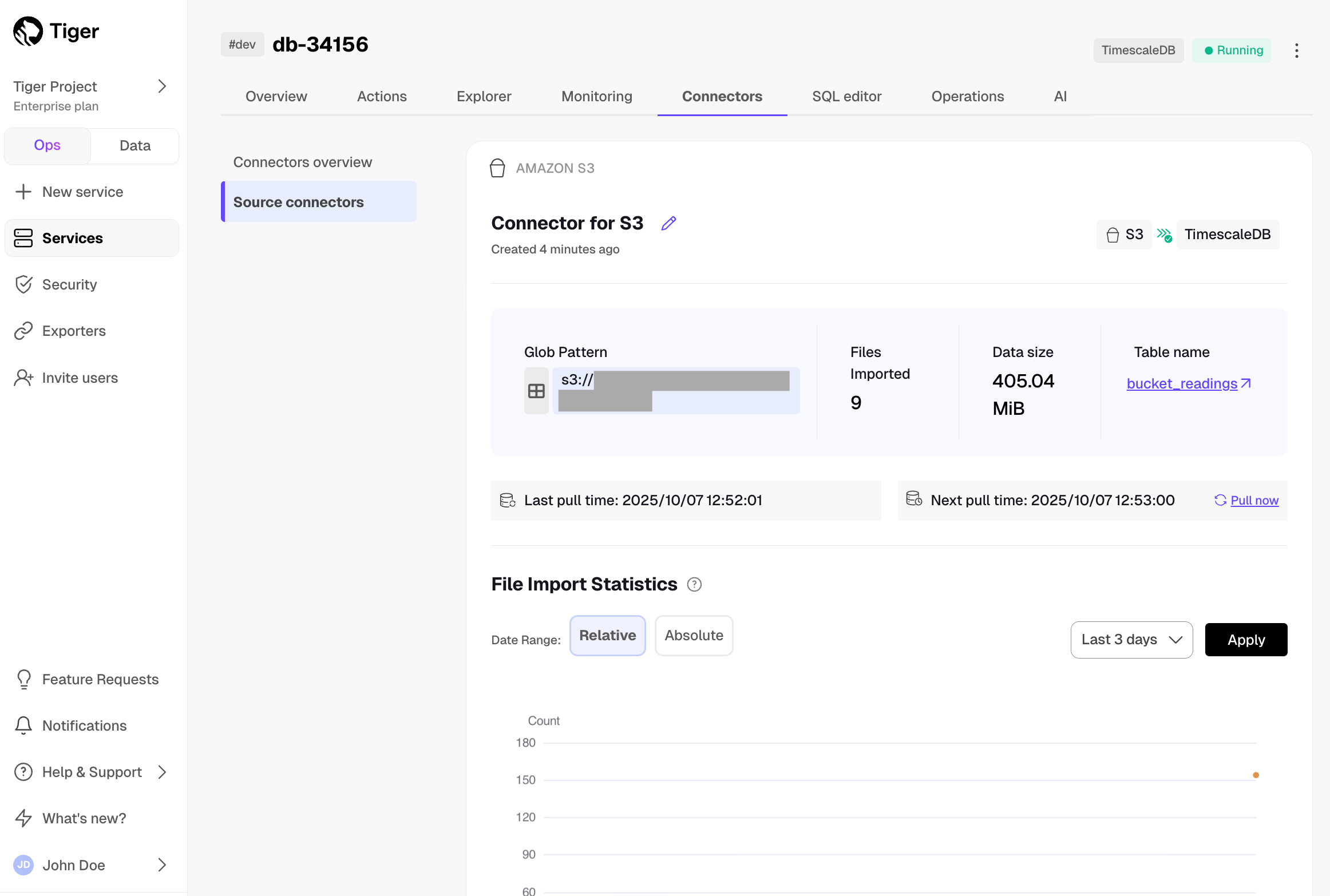
+ 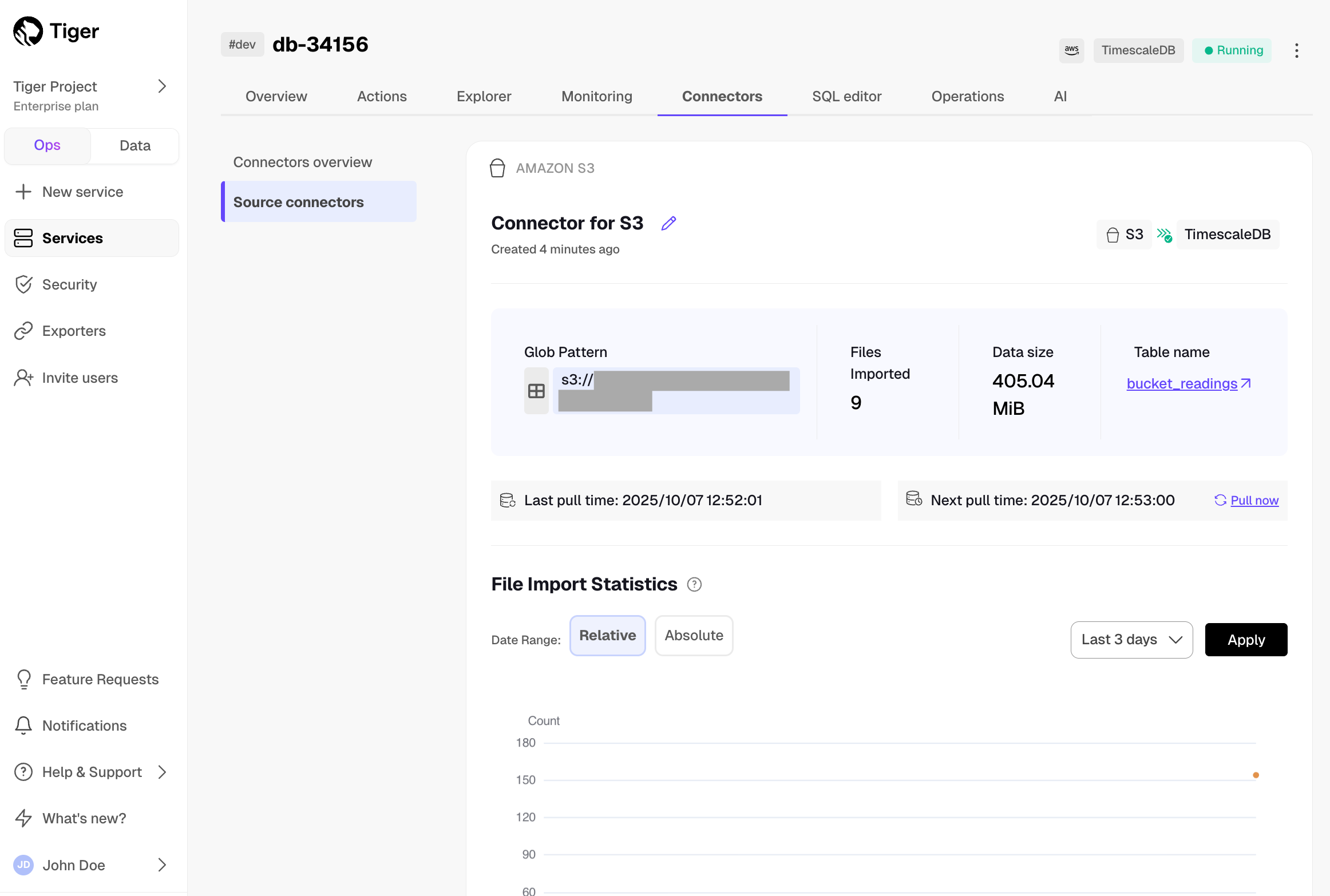
1. **Manage the connector**
1. To pause the connector, click `Connectors` > `Source connectors`. Open the three-dot menu next to your connector in the table, then click `Pause`.
- 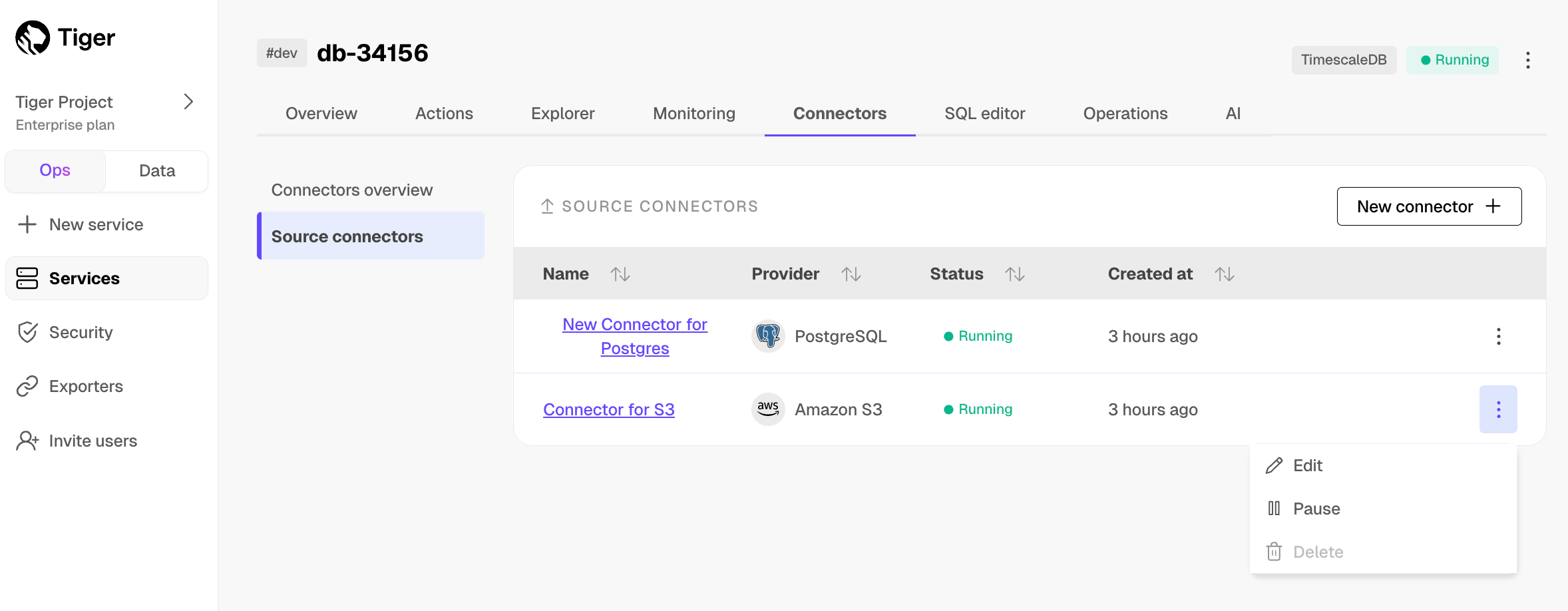
+ 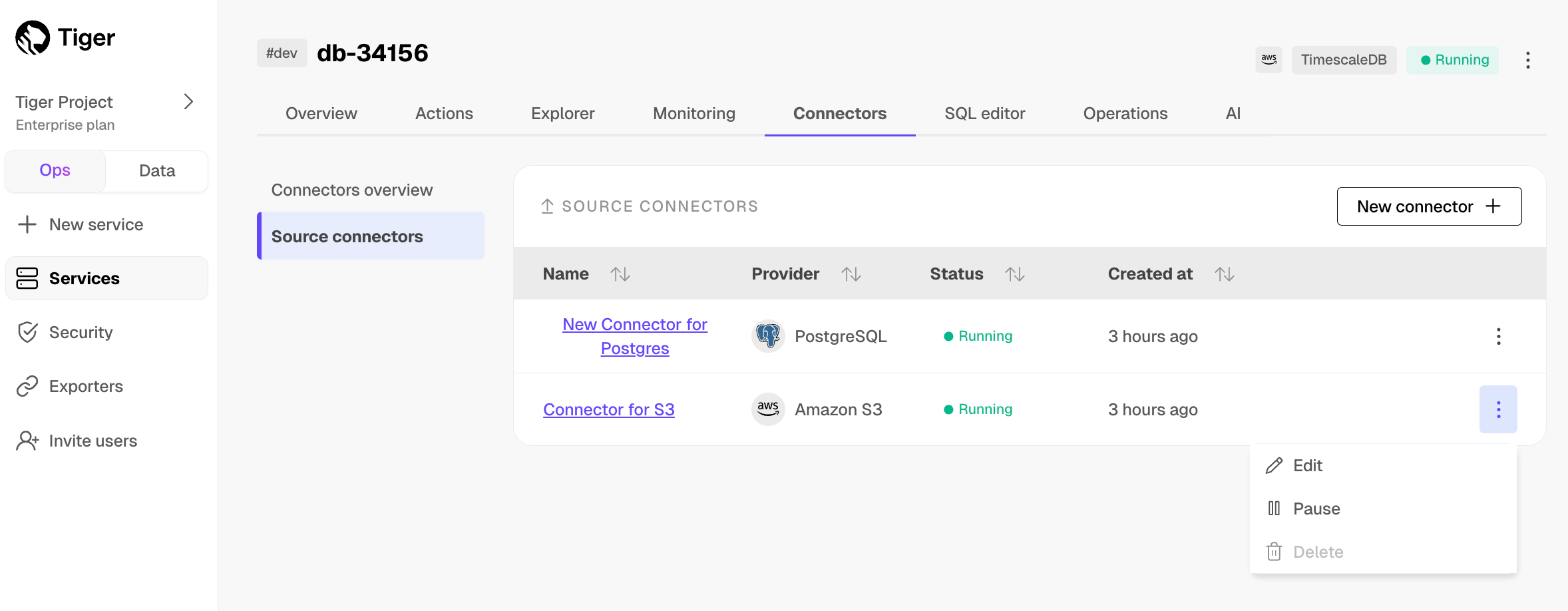
1. To edit the connector, click `Connectors` > `Source connectors`. Open the three-dot menu next to your connector in the table, then click `Edit` and scroll down to `Modify your Connector`. You must pause the connector before editing it.
@@ -162,6 +165,8 @@ To sync data from your S3 bucket to your $SERVICE_LONG using $CONSOLE:
And that is it, you are using the $S3_CONNECTOR to synchronize all the data, or specific files, from an S3 bucket to your
$SERVICE_LONG in real time.
+
+
[about-hypertables]: /use-timescale/:currentVersion:/hypertables/
[lives-sync-specify-tables]: /migrate/:currentVersion:/livesync-for-postgresql/#specify-the-tables-to-synchronize
[compression]: /use-timescale/:currentVersion:/compression/about-compression
diff --git a/migrate/upload-file-using-console.md b/migrate/upload-file-using-console.md
index accd788d8e..8fb713b2ba 100644
--- a/migrate/upload-file-using-console.md
+++ b/migrate/upload-file-using-console.md
@@ -8,6 +8,7 @@ keywords: [import]
import ImportPrerequisitesCloudNoConnection from "versionContent/_partials/_prereqs-cloud-no-connection.mdx";
import EarlyAccessGeneral from "versionContent/_partials/_early_access.mdx";
import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Upload a file into your $SERVICE_SHORT using $CONSOLE_LONG
@@ -25,6 +26,8 @@ $CONSOLE_LONG enables you to drag and drop files to upload from your local machi
+
+
@@ -127,6 +130,8 @@ $CONSOLE_LONG enables you to upload CSV and Parquet files, including archives co
- [IAM Role][credentials-iam].
- [Public anonymous user][credentials-public].
+
+
@@ -205,7 +210,6 @@ To import a Parquet file from an S3 bucket:
-
And that is it, you have imported your data to your $SERVICE_LONG.
[credentials-iam]: https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_for-user.html#roles-creatingrole-user-console
diff --git a/use-timescale/backup-restore.md b/use-timescale/backup-restore.md
index 693c389155..954f49024a 100644
--- a/use-timescale/backup-restore.md
+++ b/use-timescale/backup-restore.md
@@ -7,8 +7,13 @@ tags: [recovery, failures]
---
import CLIFORKS from "versionContent/_partials/_devops-cli-service-forks.mdx";
+import PitrIntro from "versionContent/_partials/_pitr-intro.mdx";
-# Back up and recover $SERVICE_SHORTs
+# Back up and recover your $SERVICE_SHORTs
+
+
+
+
$CLOUD_LONG provides comprehensive backup and recovery solutions to protect your data, including automatic daily backups,
cross-region protection, and point-in-time recovery.
@@ -22,9 +27,9 @@ $CLOUD_LONG automatically creates one full backup every week, and incremental ba
your $SERVICE_SHORT. Additionally, all [Write-Ahead Log (WAL)][wal] files are retained back to the oldest full backup.
This means that you always have a full backup available for the current and previous week:
-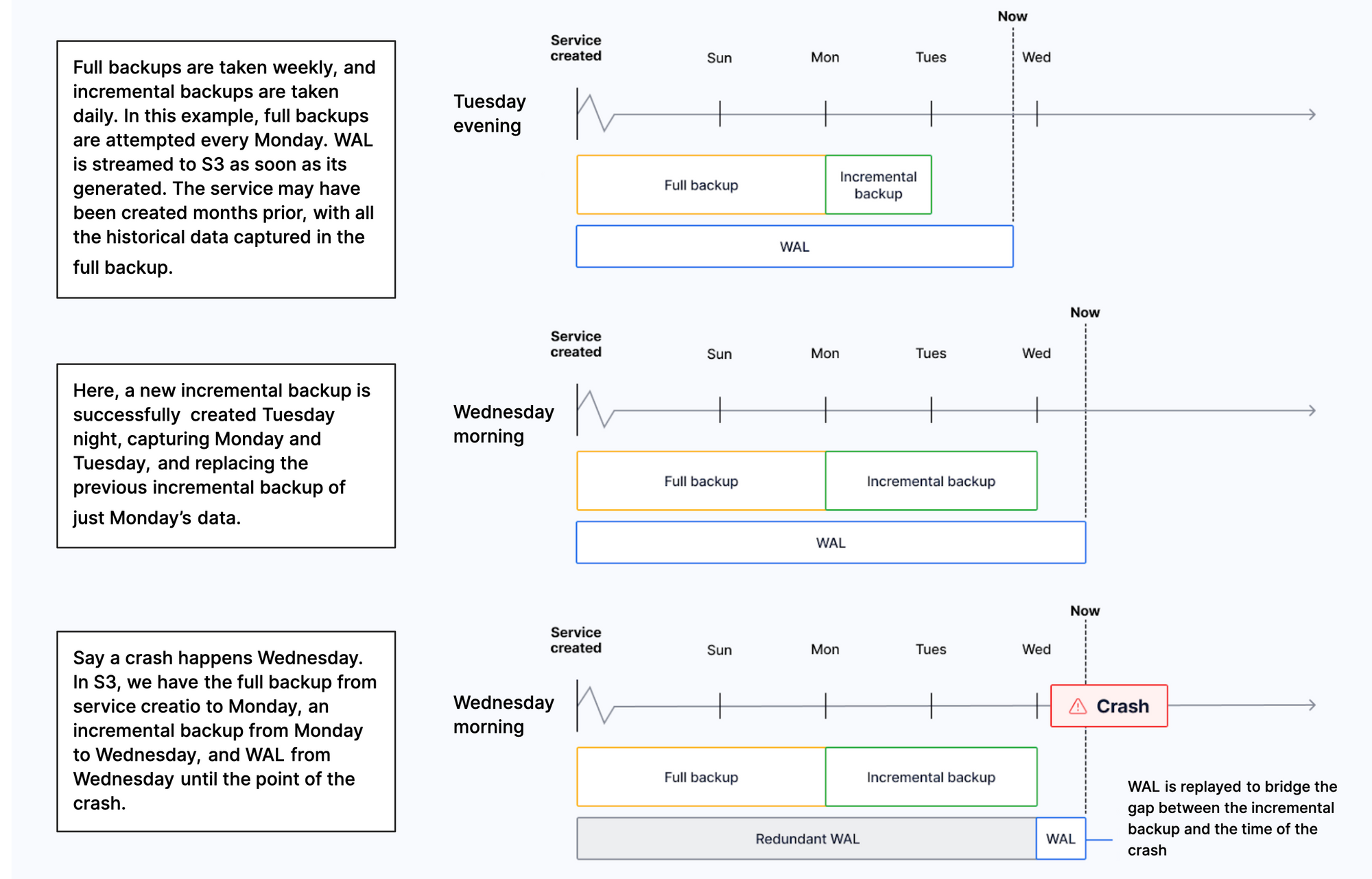
+
-On [$SCALE and $PERFORMANCE][pricing-and-account-management] $PRICING_PLANs, you can check the list of backups for the previous 14 days in $CONSOLE_LONG. To do so, select your $SERVICE_SHORT, then click `Operations` > `Backup and restore` > `Backup history`.
+On [$SCALE and $PERFORMANCE][pricing-and-account-management] $PRICING_PLANs, you can check the list of backups for the previous 14 days in $CONSOLE_LONG. To do so, select your $SERVICE_SHORT, then click `Operations` > `Backup and restore` > `Backup history`.
In the event of a storage failure, a $SERVICE_SHORT automatically recovers from a backup
to the point of failure. If the whole availability zone goes down, your $SERVICE_LONGs are recovered in a different zone. In the event of a user error, you can [create a point-in-time recovery fork][create-fork].
@@ -43,7 +48,7 @@ You enable cross-region backup when you create a $SERVICE_SHORT, or configure it
1. In `Cross-region backup`, select the region in the dropdown and click `Enable backup`.
- 
+ 
You can now see the backup, its region, and creation date in a list.
@@ -57,7 +62,7 @@ You can have one cross-region backup per $SERVICE_SHORT. To change the region of
1. Click the trash icon next to the existing backup to disable it.
- 
+ 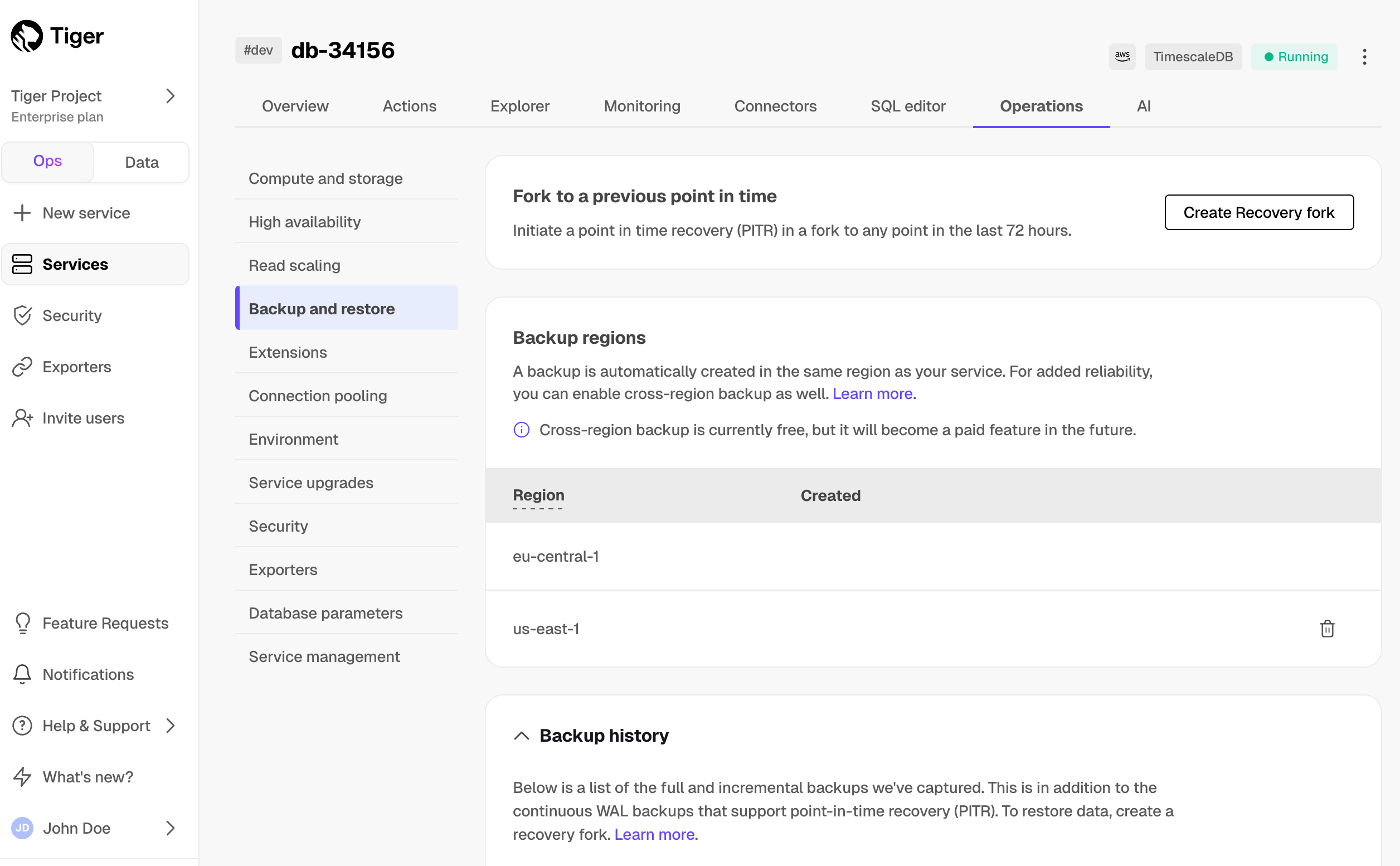
1. Create a new backup in a different region.
@@ -65,26 +70,7 @@ You can have one cross-region backup per $SERVICE_SHORT. To change the region of
## Create a point-in-time recovery fork
-
-
-To recover your $SERVICE_SHORT from a destructive or unwanted action, create a point-in-time recovery fork. You can
-recover a $SERVICE_SHORT to any point within the period [defined by your pricing plan][pricing-and-account-management].
-The provision time for the recovery fork is typically less than twenty minutes, but can take longer depending on the
-amount of WAL to be replayed. The original $SERVICE_SHORT stays untouched to avoid losing data created since the time
-of recovery.
-
-All tiered data remains recoverable during the PITR period. When restoring to any point-in-time recovery fork, your
-$SERVICE_SHORT contains all data that existed at that moment - whether it was stored in high-performance or low-cost
-storage.
-
-When you restore a recovery fork:
-- Data restored from a PITR point is placed into high-performance storage
-- The tiered data, as of that point in time, remains in tiered storage
-
-
-
-To avoid paying for compute for the recovery fork and the original $SERVICE_SHORT, pause the original to only pay
-storage costs.
+
You initiate a point-in-time recovery from a same-region or cross-region backup in $CONSOLE_LONG:
@@ -127,11 +113,67 @@ You initiate a point-in-time recovery from a same-region or cross-region backup
+## Create a service fork
+
+
+
+
+
+
+
+$CLOUD_LONG provides comprehensive backup and recovery solutions to protect your data, including automatic daily backups and point-in-time recovery.
+
+## Automatic backups
+
+$CLOUD_LONG automatically handles backup for your $SERVICE_LONGs using the `pgBackRest` tool. You don't need to perform
+backups manually.
+
+$CLOUD_LONG automatically creates one full backup every week, and incremental backups every day in the same region as
+your $SERVICE_SHORT. Additionally, all [Write-Ahead Log (WAL)][wal] files are retained back to the oldest full backup.
+This means that you always have a full backup available for the current and previous week:
+
+
+
+On [$SCALE and $PERFORMANCE][pricing-and-account-management] $PRICING_PLANs, you can check the list of backups for the previous 14 days in $CONSOLE_LONG. To do so, select your $SERVICE_SHORT, then click `Operations` > `Backup and restore` > `Backup history`.
+
+In the event of a storage failure, a $SERVICE_SHORT automatically recovers from a backup
+to the point of failure. If the whole availability zone goes down, your $SERVICE_LONGs are recovered in a different zone. In the event of a user error, you can [create a point-in-time recovery fork][create-fork].
+
+## Create a point-in-time recovery fork
+
+
+
+You initiate a point-in-time recovery in $CONSOLE_LONG:
+
+
+
+1. In [$CONSOLE][console], from the `Services` list, ensure the $SERVICE_SHORT
+ you want to recover has a status of `Running` or `Paused`.
+1. Navigate to `Operations` > `Backup & restore` and click `Create recovery fork`.
+1. Select the recovery point, ensuring the correct time zone (UTC offset).
+1. Configure the fork.
+
+ 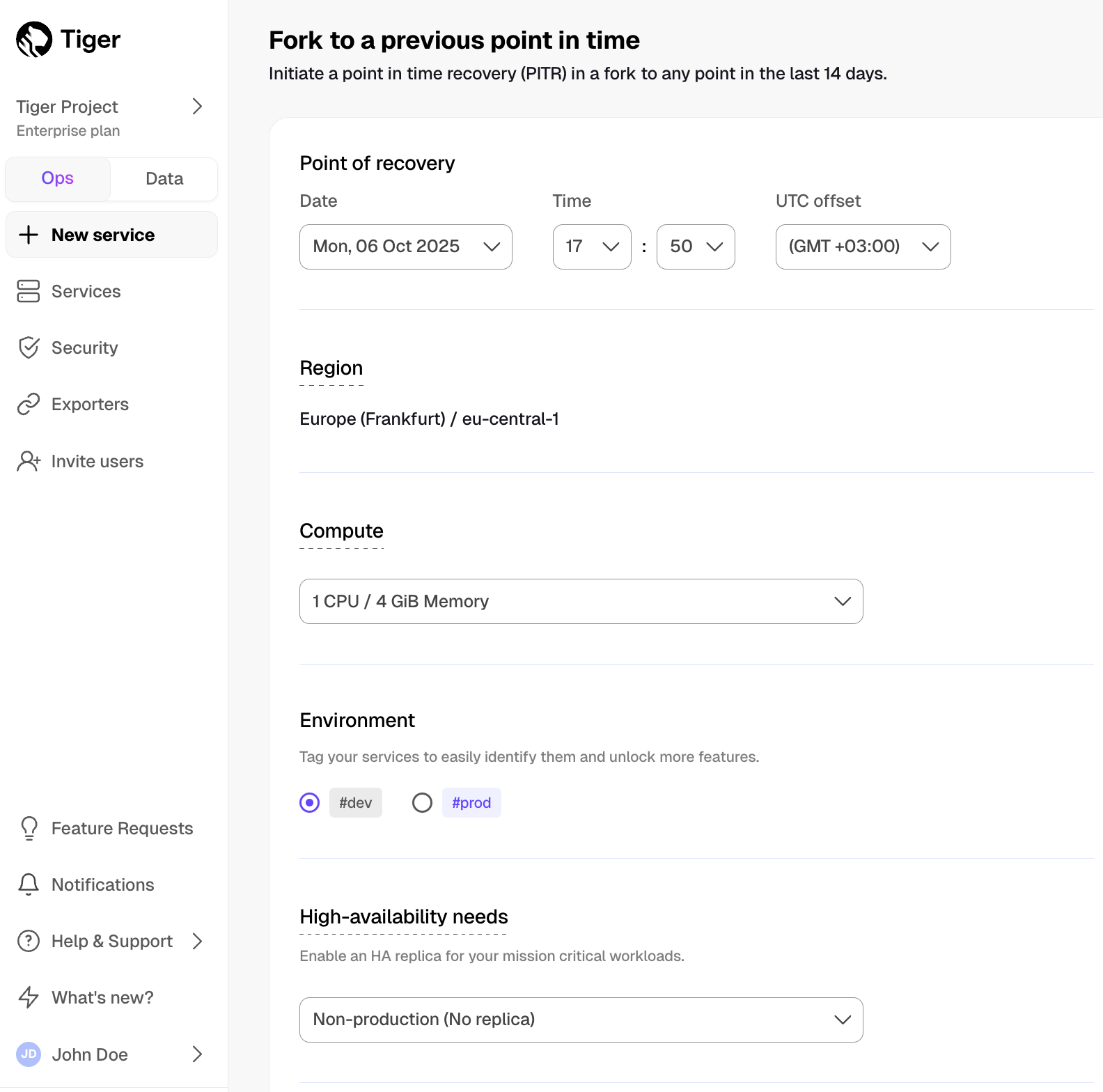
+
+ You can configure the compute resources, add an HA replica, tag your fork, and
+ add a connection pooler. Best practice is to match
+ the same configuration you had at the point you want to recover to.
+1. Confirm by clicking `Create recovery fork`.
+
+ A fork of the $SERVICE_SHORT is created. The recovered $SERVICE_SHORT shows in `Services` with a label specifying which $SERVICE_SHORT it has been forked from.
+1. Update the connection strings in your app to use the fork.
+
+
## Create a service fork
+
+
+
+
+
[console]: https://console.cloud.timescale.com/dashboard/services
[ha-replicas]: /about/use-timescale/:currentVersion:/ha-replicas/
diff --git a/use-timescale/configuration/customize-configuration.md b/use-timescale/configuration/customize-configuration.md
index 5b87d05af3..b525426a85 100644
--- a/use-timescale/configuration/customize-configuration.md
+++ b/use-timescale/configuration/customize-configuration.md
@@ -32,7 +32,7 @@ To modify configuration parameters, first select the $SERVICE_SHORT that you wan
modify. This displays the $SERVICE_SHORT details, with these tabs across the top:
`Overview`, `Actions`, `Explorer`, `Monitoring`, `Connections`, `SQL Editor`, `Operations`, and `AI`. Select `Operations`, then `Database parameters`.
-
+
### Modify basic parameters
diff --git a/use-timescale/data-tiering/about-data-tiering.md b/use-timescale/data-tiering/about-data-tiering.md
index 9a2f71300b..a6fc0791de 100644
--- a/use-timescale/data-tiering/about-data-tiering.md
+++ b/use-timescale/data-tiering/about-data-tiering.md
@@ -10,6 +10,7 @@ cloud_ui:
---
import TieredStorageBilling from "versionContent/_partials/_tiered-storage-billing.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# About storage tiers
@@ -34,6 +35,8 @@ $CLOUD_LONG high-performance storage comes in the following types:
Once you [enable tiered storage][manage-tiering], you can start moving rarely used data to the object tier. The object tier is based on AWS S3 and stores your data in the [Apache Parquet][parquet] format. Within a Parquet file, a set of rows is grouped together to form a row group. Within a row group, values for a single column across multiple rows are stored together. The original size of the data in your $SERVICE_SHORT, compressed or uncompressed, does not correspond directly to its size in S3. A compressed hypertable may even take more space in S3 than it does in $CLOUD_LONG.
+
+
Apache Parquet allows for more efficient scans across longer time periods, and $CLOUD_LONG uses other metadata and query optimizations to reduce the amount of data that needs to be fetched to satisfy a query, such as:
- **Chunk skipping**: exclude the chunks that fall outside the query time window.
@@ -122,6 +125,7 @@ The low-cost storage tier comes with the following limitations:
partitioned on more than one dimension. Make sure your hypertables are
partitioned on time only, before you enable tiered storage.
+
[blog-data-tiering]: https://www.timescale.com/blog/expanding-the-boundaries-of-postgresql-announcing-a-bottomless-consumption-based-object-storage-layer-built-on-amazon-s3/
[querying-tiered-data]: /use-timescale/:currentVersion:/data-tiering/querying-tiered-data/
[parquet]: https://parquet.apache.org/
diff --git a/use-timescale/data-tiering/enabling-data-tiering.md b/use-timescale/data-tiering/enabling-data-tiering.md
index 310a702a70..ceb62e3b87 100644
--- a/use-timescale/data-tiering/enabling-data-tiering.md
+++ b/use-timescale/data-tiering/enabling-data-tiering.md
@@ -11,6 +11,7 @@ cloud_ui:
---
import TieredStorageBilling from "versionContent/_partials/_tiered-storage-billing.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Manage storage and tiering
@@ -44,7 +45,7 @@ This storage type gives you up to 16 TB of storage and is available under [all $
- Under the [$PERFORMANCE $PRICING_PLAN][pricing-plans], IOPS is set to 3,000 - 5,000 autoscale and cannot be changed.
- Under the [$SCALE and $ENTERPRISE $PRICING_PLANs][pricing-plans], IOPS is set to 5,000 - 8,000 autoscale and can be upgraded to 16,000 IOPS.
- 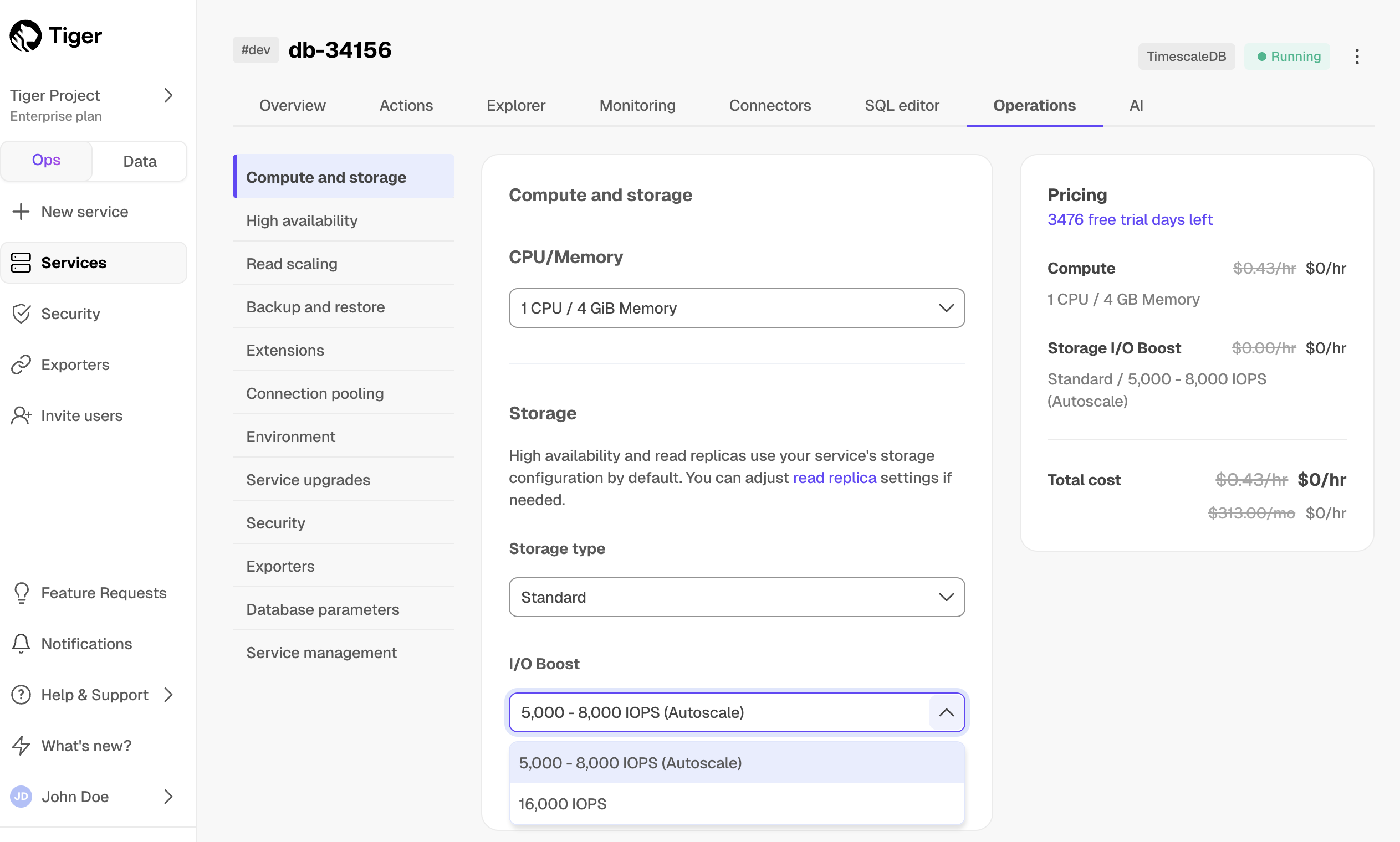
+ 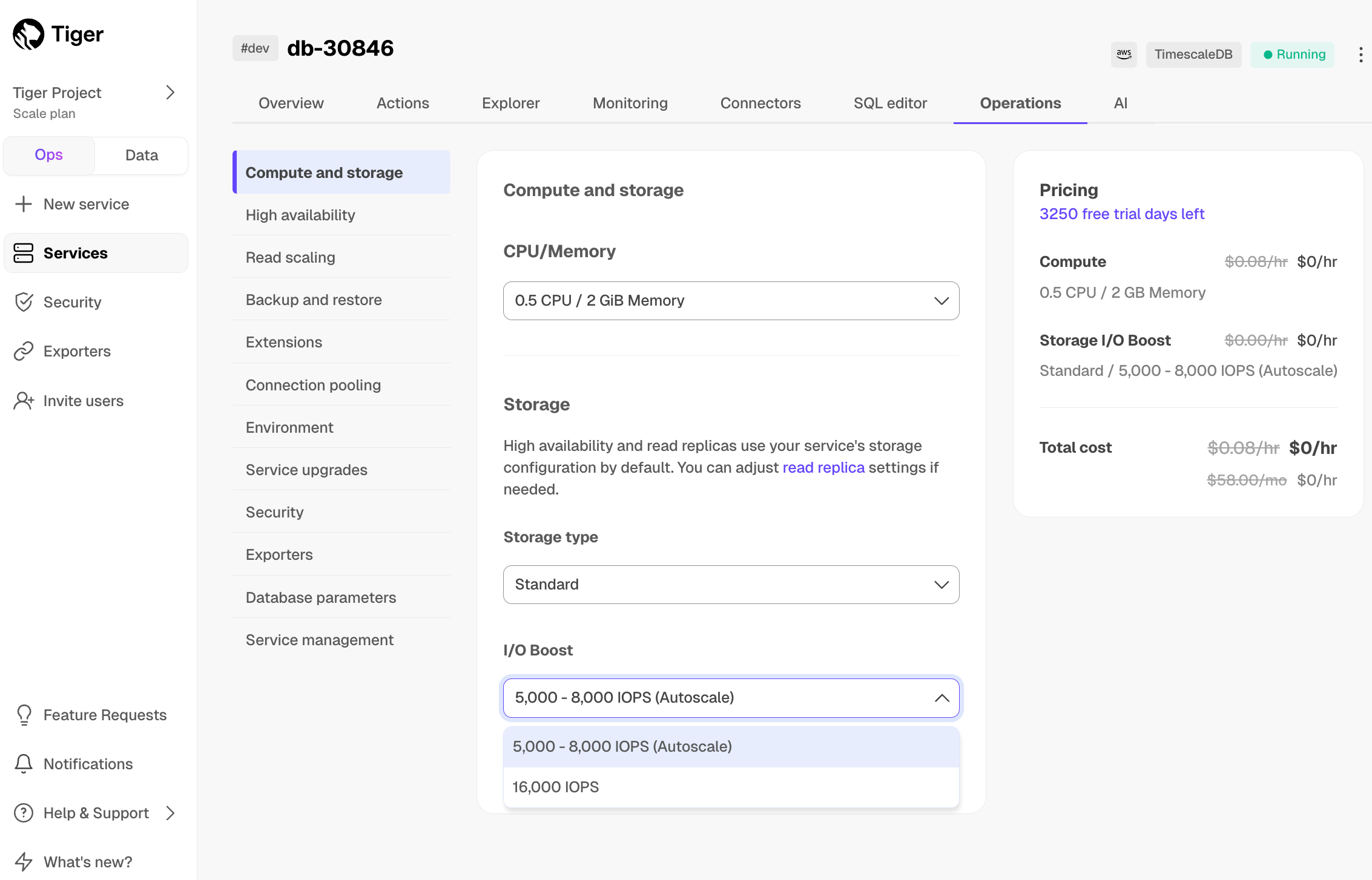
1. **Click `Apply`**
@@ -54,14 +55,18 @@ This storage type gives you up to 16 TB of storage and is available under [all $
-This storage type gives you up to 64 TB and 32,000 IOPS, and is available under the [$ENTERPRISE $PRICING_PLAN][pricing-plans]. To get enhanced storage:
+This storage type gives you up to 64 TB and 32,000 IOPS, and is available under the [$ENTERPRISE $PRICING_PLAN][pricing-plans].
+
+
+
+To get enhanced storage:
1. **In [$CONSOLE][console], select your $SERVICE_SHORT, then click `Operations` > `Compute and storage`**
1. **Select `Enhanced` in the `Storage type` dropdown**
- 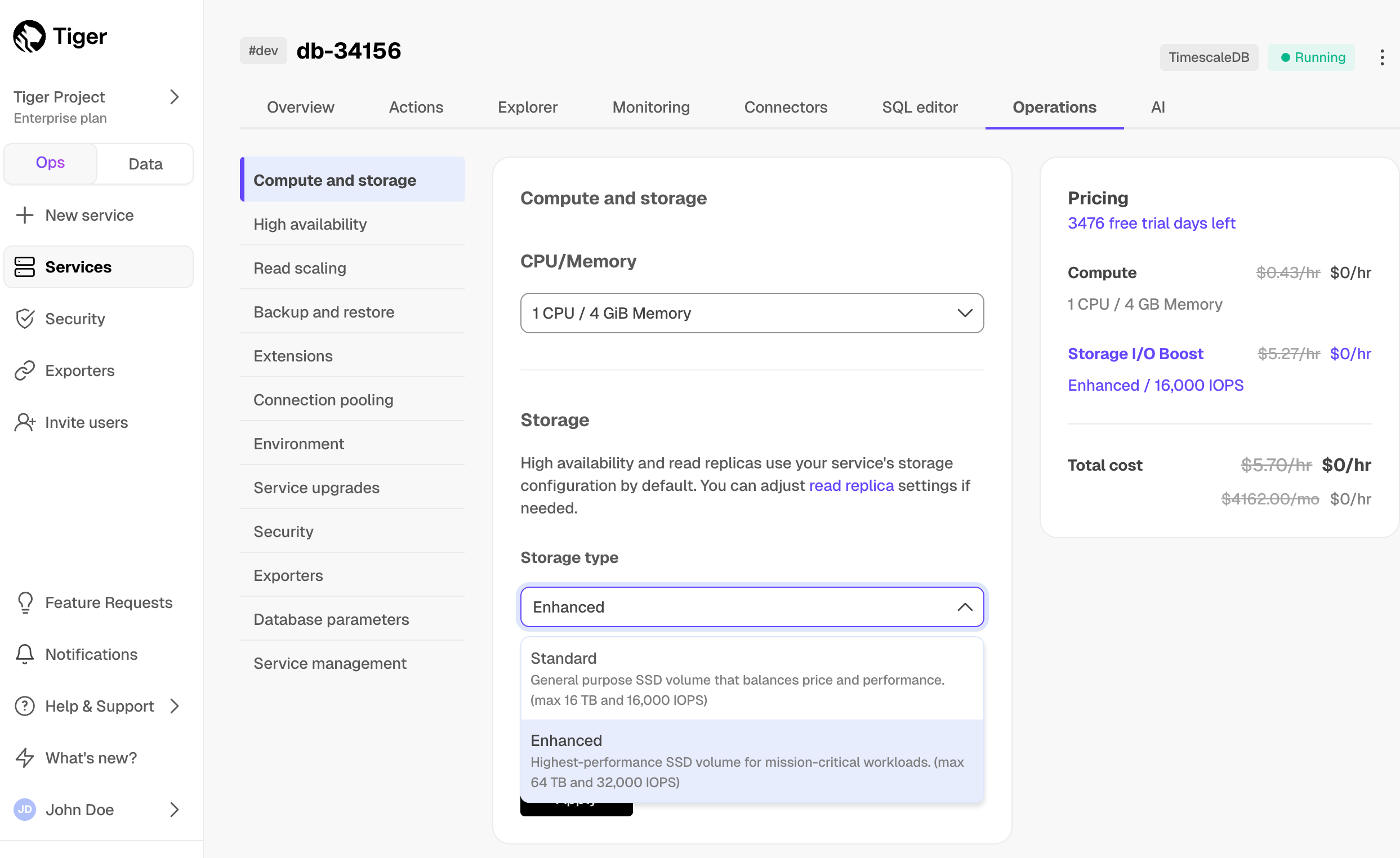
+ 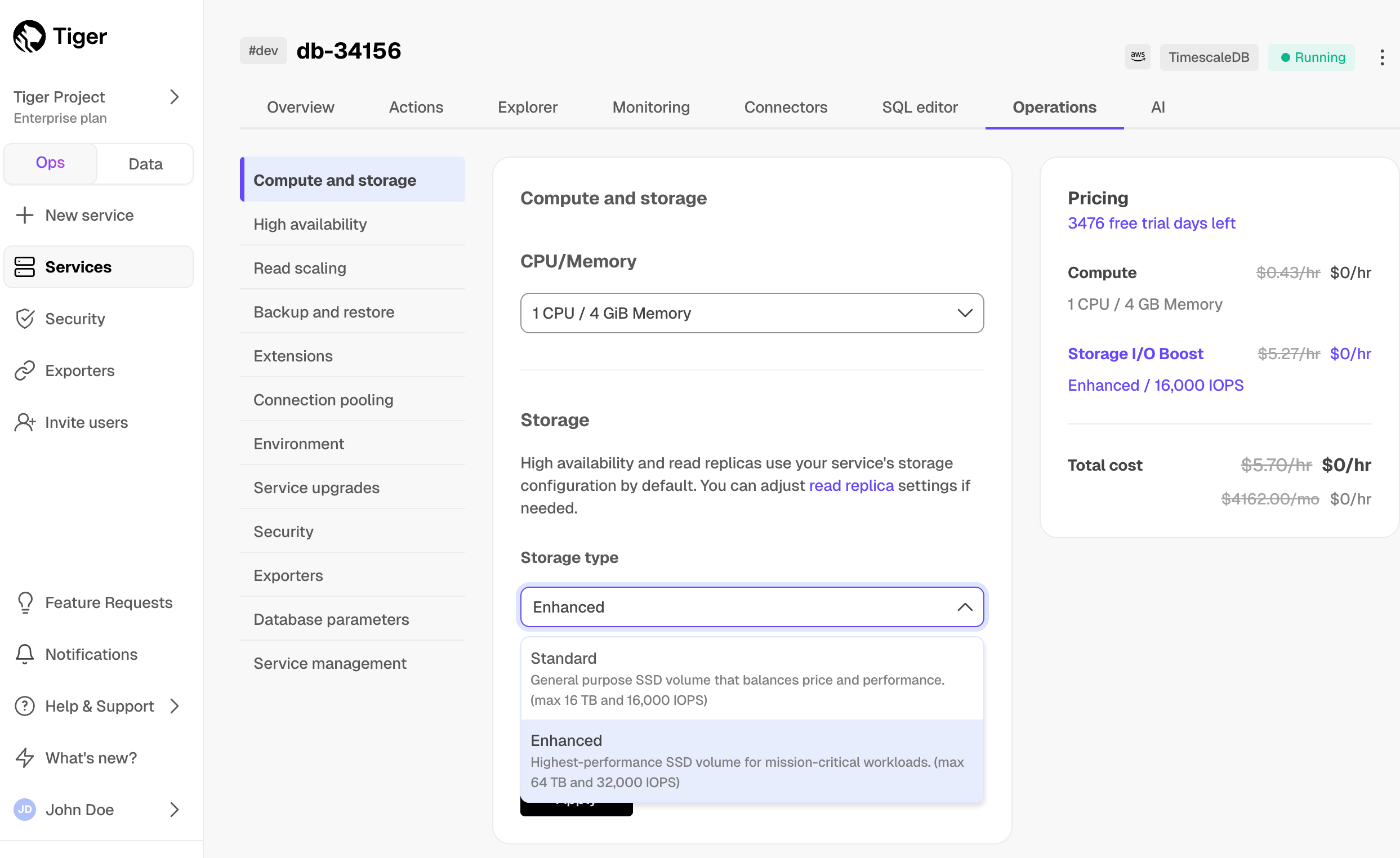
@@ -73,7 +78,7 @@ This storage type gives you up to 64 TB and 32,000 IOPS, and is available under
Select between 8,000, 16,000, 24,000, and 32,0000 IOPS. The value that you can apply depends on the number of CPUs in your $SERVICE_SHORT. $CONSOLE notifies you if your selected IOPS requires increasing the number of CPUs. To increase IOPS to 64,000, click `Contact us` and we will be in touch to confirm the details.
- 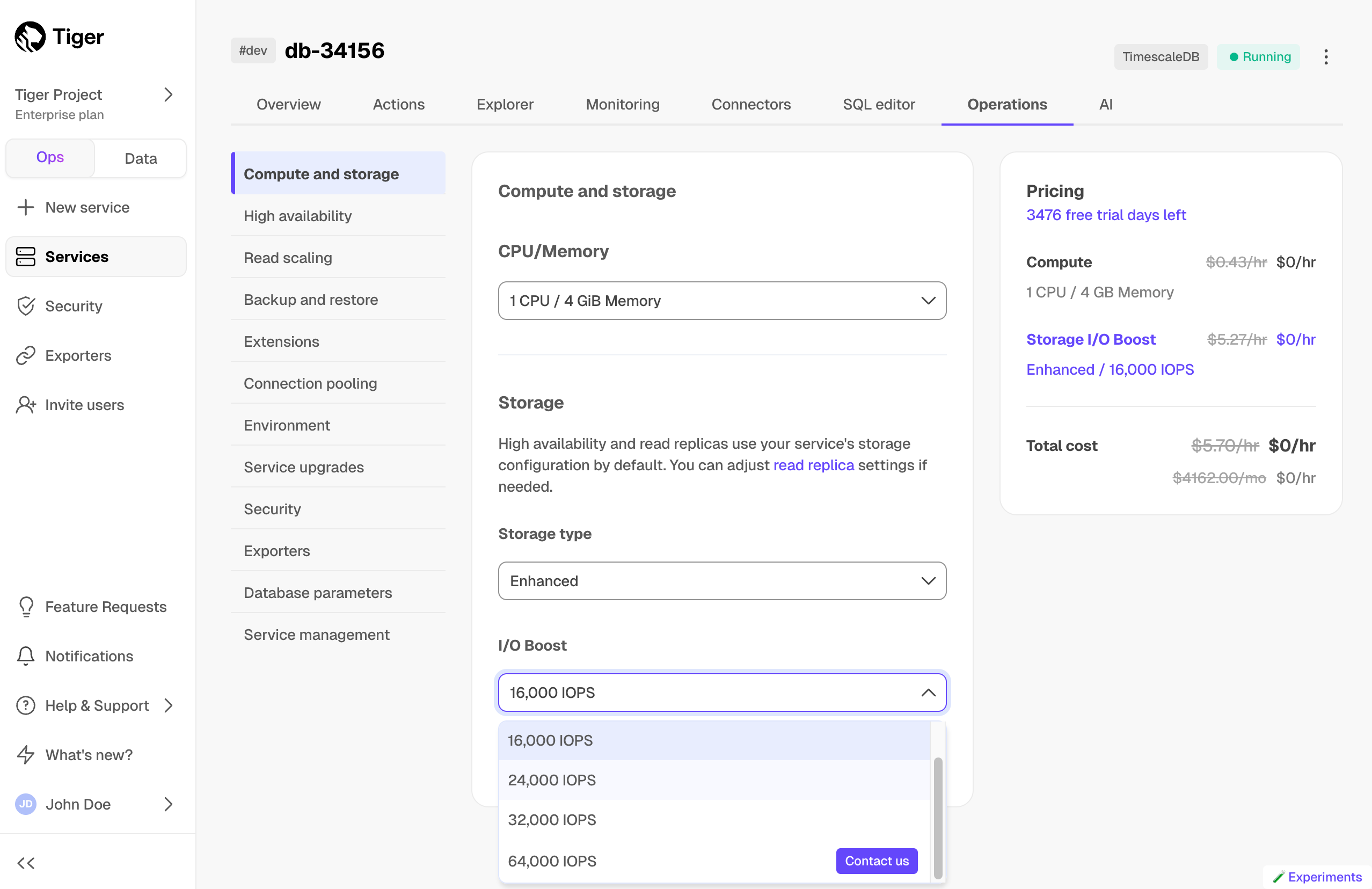
+ 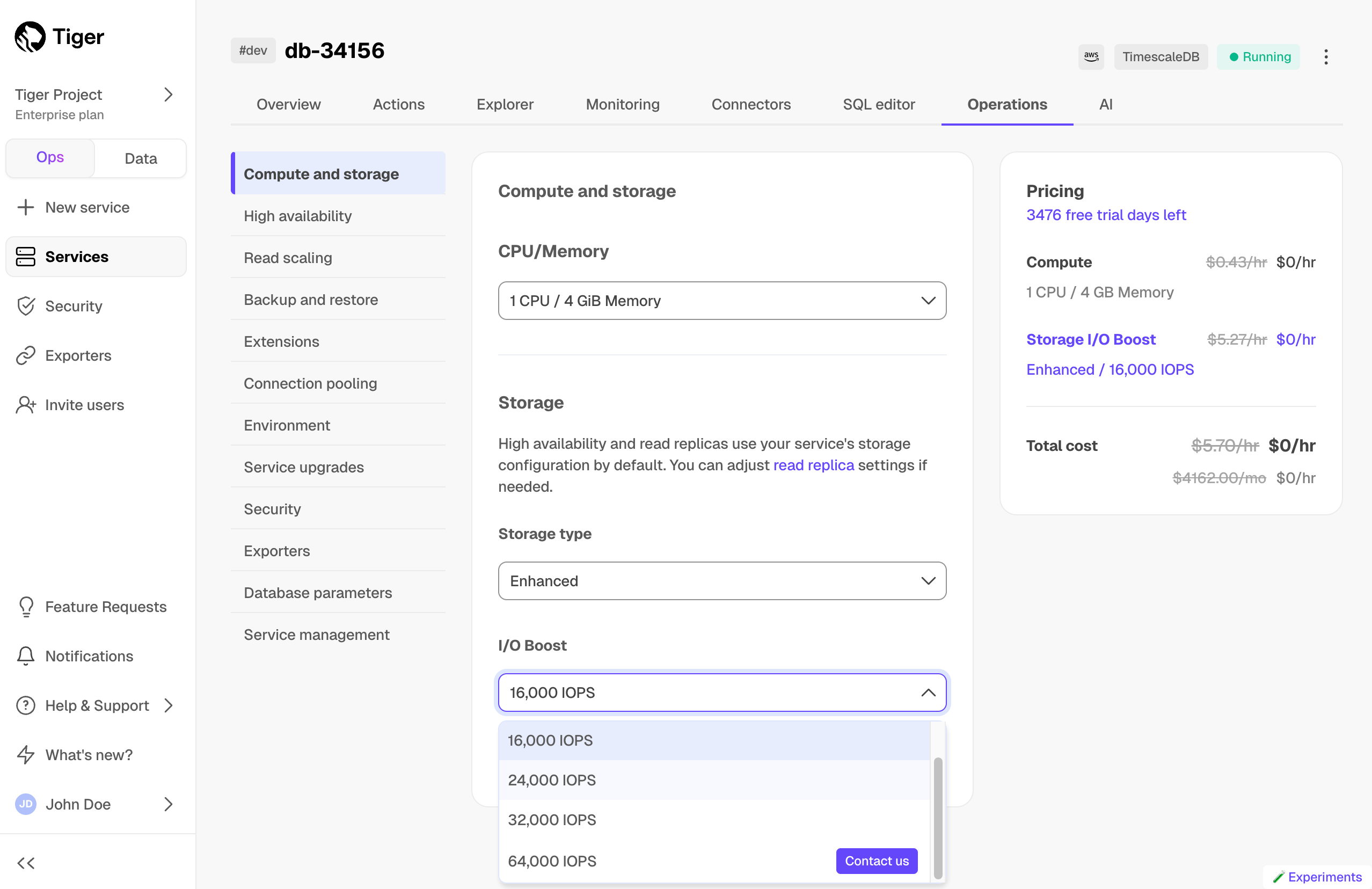
1. **Click `Apply`**
@@ -87,6 +92,8 @@ You change from enhanced storage to standard in the same way. If you are using o
You enable the low-cost object storage tier in $CONSOLE and then tier the data with policies or manually.
+
+
### Enable tiered storage
You enable tiered storage from the `Overview` tab in $CONSOLE.
@@ -97,7 +104,7 @@ You enable tiered storage from the `Overview` tab in $CONSOLE.
1. **In `Explorer`, click `Storage configuration` > `Tiering storage`, then click `Enable tiered storage`**
- 
+ 
Once enabled, you can proceed to [tier data manually][manual-tier] or [set up tiering policies][tiering-policies]. When tiered storage is enabled, you see the amount of data in the tiered object storage.
@@ -280,6 +287,7 @@ If you no longer want to use tiered storage for a particular hypertable, drop th
+
[data-retention]: /use-timescale/:currentVersion:/data-retention/
[console]: https://console.cloud.timescale.com/dashboard/services
[hypertable]: /use-timescale/:currentVersion:/hypertables/
diff --git a/use-timescale/data-tiering/index.md b/use-timescale/data-tiering/index.md
index fac5c509c9..046e307f69 100644
--- a/use-timescale/data-tiering/index.md
+++ b/use-timescale/data-tiering/index.md
@@ -1,6 +1,6 @@
---
-title: Storage in Tiger
-excerpt: Save on storage costs by tiering older data to a low-cost bottomless object storage tier. Tiger Cloud tiered storage makes sure you cut costs while having data available for analytical queries
+title: Storage on Tiger Cloud
+excerpt: Save on storage costs by tiering older data to a low-cost bottomless object storage tier. Tiger tiered storage makes sure you cut costs while having data available for analytical queries
products: [cloud]
keywords: [tiered storage]
tags: [storage, data management]
@@ -8,6 +8,10 @@ tags: [storage, data management]
# Storage
+
+
+
+
Tiered storage is a [hierarchical storage management architecture][hierarchical-storage] for
[real-time analytics][create-service] $SERVICE_SHORTs you create in [$CLOUD_LONG](https://console.cloud.timescale.com/).
@@ -42,6 +46,19 @@ In this section, you:
* [Learn about replicas and forks with tiered data][replicas-and-forks]: understand how tiered storage works
with forks and replicas of your $SERVICE_SHORT.
+
+
+
+
+$CLOUD_LONG stores your data in high-performance storage optimized for frequent querying. Based on [AWS EBS gp3][aws-gp3], the high-performance storage provides you with up to 16 TB and 16,000 IOPS. Its [$HYPERCORE row-columnar storage engine][hypercore], designed specifically for real-time analytics, enables you to compress your data by up to 98%, while improving performance.
+
+Coupled with other optimizations, $CLOUD_LONG high-performance storage makes sure your data is always accessible and your queries run at lightning speed.
+
+
+
+
+
+
[about-data-tiering]: /use-timescale/:currentVersion:/data-tiering/about-data-tiering/
[enabling-data-tiering]: /use-timescale/:currentVersion:/data-tiering/enabling-data-tiering/
[replicas-and-forks]: /use-timescale/:currentVersion:/data-tiering/tiered-data-replicas-forks/
@@ -49,4 +66,6 @@ In this section, you:
[querying-tiered-data]: /use-timescale/:currentVersion:/data-tiering/querying-tiered-data/
[add-retention-policies]: /api/:currentVersion:/continuous-aggregates/add_policies/
[create-service]: /getting-started/:currentVersion:/services/
-[hierarchical-storage]: https://en.wikipedia.org/wiki/Hierarchical_storage_management
\ No newline at end of file
+[hierarchical-storage]: https://en.wikipedia.org/wiki/Hierarchical_storage_management
+[hypercore]: /use-timescale/:currentVersion:/hypercore
+[aws-gp3]: https://docs.aws.amazon.com/ebs/latest/userguide/general-purpose.html
\ No newline at end of file
diff --git a/use-timescale/data-tiering/querying-tiered-data.md b/use-timescale/data-tiering/querying-tiered-data.md
index 9b19ed5686..a33a961a6d 100644
--- a/use-timescale/data-tiering/querying-tiered-data.md
+++ b/use-timescale/data-tiering/querying-tiered-data.md
@@ -7,6 +7,8 @@ keywords: [ tiered storage, tiering ]
tags: [ storage, data management ]
---
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
+
# Querying tiered data
Once rarely used data is tiered and migrated to the object storage tier, it can still be queried
@@ -24,6 +26,8 @@ Your hypertable is spread across the tiers, so queries and `JOIN`s work and fetc
By default, tiered data is not accessed by queries. Querying tiered data may slow down query performance
as the data is not stored locally on the high-performance storage tier. See [Performance considerations](#performance-considerations).
+
+
## Enable querying tiered data for a single query
@@ -186,3 +190,5 @@ Queries over tiered data are expected to be slower than over local data. However
* Text and non-native types (JSON, JSONB, GIS) filtering is slower when querying tiered data.
+
+
diff --git a/use-timescale/data-tiering/tiered-data-replicas-forks.md b/use-timescale/data-tiering/tiered-data-replicas-forks.md
index 645ea13a6d..d1b23af3b7 100644
--- a/use-timescale/data-tiering/tiered-data-replicas-forks.md
+++ b/use-timescale/data-tiering/tiered-data-replicas-forks.md
@@ -7,7 +7,9 @@ keywords: [tiered storage]
tags: [storage, data management]
---
-# How tiered data works on replicas and forks
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
+
+# How tiered data works on replicas and forks
There is one more thing that makes Tiered Storage even more amazing: when you keep data in the low-cost object storage tier,
you pay for this data only once, regardless of whether you have a [high-availability replica][ha-replica]
@@ -19,6 +21,8 @@ When creating one (or more) forks, you won't be billed for data shared with the
If you decide to tier more data that's not in the primary, you will pay to store it in the low-cost tier,
but you will still see substantial savings by moving that data from the high-performance tier of the fork to the cheaper object storage tier.
+
+
## How this works behind the scenes
Once you tier data to the low-cost object storage tier, we keep a reference to that data on your Database's catalog.
@@ -68,6 +72,7 @@ In the case of such a restore, new references are added to the deleted tiered ch
Once 14 days pass after soft deleting the data,that is the number of references to the tiered data drop to 0, we hard delete the tiered data.
+
[ha-replica]: /use-timescale/:currentVersion:/ha-replicas/high-availability/
[read-replica]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/#read-replicas
[operations-forking]: /use-timescale/:currentVersion:/services/service-management/#fork-a-service
diff --git a/use-timescale/ha-replicas/read-scaling.md b/use-timescale/ha-replicas/read-scaling.md
index b9b9f6acf2..e9447a9569 100644
--- a/use-timescale/ha-replicas/read-scaling.md
+++ b/use-timescale/ha-replicas/read-scaling.md
@@ -78,7 +78,7 @@ To change the compute and storage configuration of your $READ_REPLICA set:
1. **In [$CONSOLE][timescale-console-services], expand and click the $READ_REPLICA set under your primary $SERVICE_SHORT**
- 
+ 
1. **Click `Operations` > `Compute and storage`**
@@ -102,7 +102,7 @@ is measured in bytes, against the current state of the primary instance. To chec
You see a list of configured $READ_REPLICA sets for this $SERVICE_SHORT, including their status and lag:
- 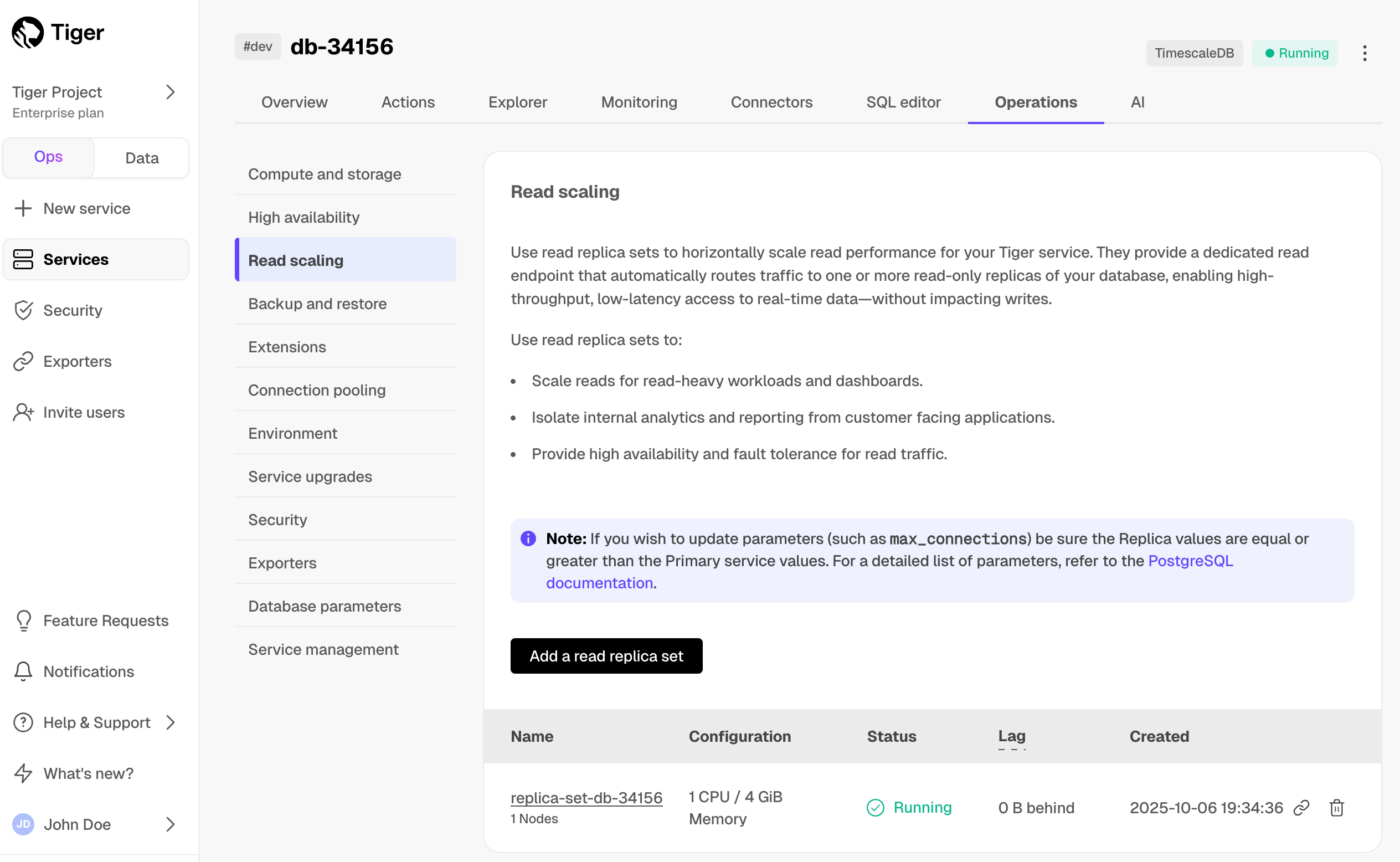
+ 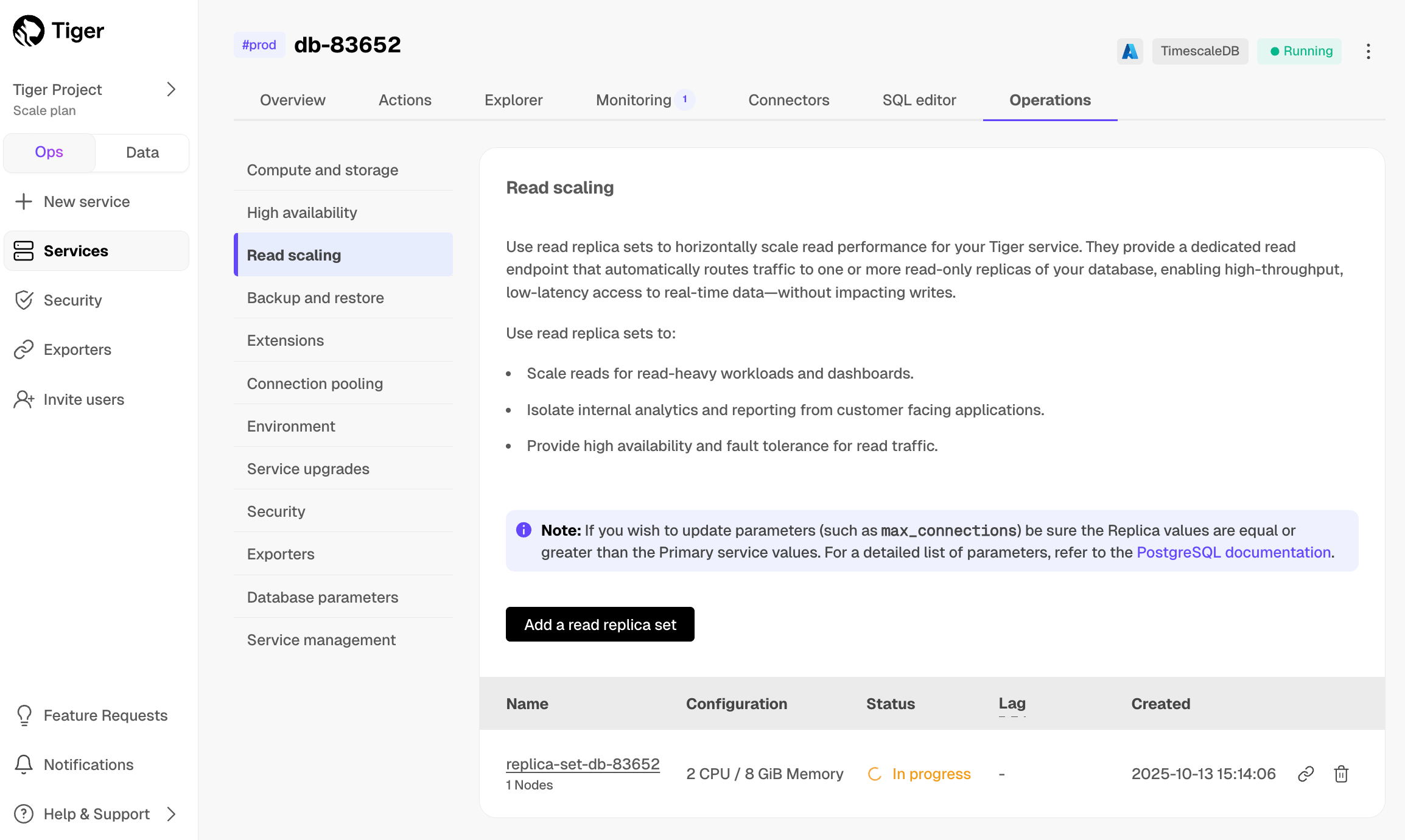
1. **Configure the allowable lag**
diff --git a/use-timescale/metrics-logging/aws-cloudwatch.md b/use-timescale/metrics-logging/aws-cloudwatch.md
index 21167975c7..a5ee21f90a 100644
--- a/use-timescale/metrics-logging/aws-cloudwatch.md
+++ b/use-timescale/metrics-logging/aws-cloudwatch.md
@@ -10,6 +10,7 @@ tags: [telemetry, monitor]
import ManageDataExporter from "versionContent/_partials/_manage-a-data-exporter.mdx";
import PrereqsCloud from "versionContent/_partials/_prereqs-cloud-no-connection.mdx";
import CloudWatchExporter from "versionContent/_partials/_cloudwatch-data-exporter.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Export telemetry data to AWS Cloudwatch
@@ -22,6 +23,8 @@ This page shows you how to create an Amazon CloudWatch exporter in $CONSOLE, and
+
+
## Create a data exporter
$CLOUD_LONG data exporters send telemetry data from a $SERVICE_LONG to a third-party monitoring
@@ -35,6 +38,8 @@ This section shows you how to attach, monitor, edit, and delete a data exporter.
+
+
[cloudwatch]: https://aws.amazon.com/cloudwatch/
[cloudwatch-docs]: https://docs.aws.amazon.com/cloudwatch/index.html
[console-integrations]: https://console.cloud.timescale.com/dashboard/integrations
diff --git a/use-timescale/metrics-logging/datadog.md b/use-timescale/metrics-logging/datadog.md
index 48ce55f8a9..a1dcbb4cc3 100644
--- a/use-timescale/metrics-logging/datadog.md
+++ b/use-timescale/metrics-logging/datadog.md
@@ -10,6 +10,7 @@ tags: [telemetry, monitor]
import DataDogExporter from "versionContent/_partials/_datadog-data-exporter.mdx";
import PrereqsCloud from "versionContent/_partials/_prereqs-cloud-no-connection.mdx";
import ManageDataExporter from "versionContent/_partials/_manage-a-data-exporter.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Export telemetry data to Datadog
@@ -21,6 +22,8 @@ This page shows you how to create a Datadog exporter in $CONSOLE, and manage the
+
+
## Create a data exporter
$CLOUD_LONG data exporters send telemetry data from a $SERVICE_LONG to third-party monitoring
@@ -34,6 +37,8 @@ This section shows you how to attach, monitor, edit, and delete a data exporter.
+
+
[datadog]: https://www.datadoghq.com
[datadog-api-key]: https://docs.datadoghq.com/account_management/api-app-keys/#add-an-api-key-or-client-token
[datadog-docs]: https://docs.datadoghq.com/
diff --git a/use-timescale/metrics-logging/index.md b/use-timescale/metrics-logging/index.md
index 47000ace7d..4d6e9147be 100644
--- a/use-timescale/metrics-logging/index.md
+++ b/use-timescale/metrics-logging/index.md
@@ -19,6 +19,7 @@ Find metrics and logs for your $SERVICE_SHORTs in $CONSOLE, or integrate with th
* Export metrics to [Amazon Cloudwatch][cloudwatch].
* Export metrics to [Prometheus][prometheus].
+
[prometheus]: /use-timescale/:currentVersion:/metrics-logging/metrics-to-prometheus/
[datadog]: /use-timescale/:currentVersion:/metrics-logging/datadog/
[cloudwatch]: /use-timescale/:currentVersion:/metrics-logging/aws-cloudwatch/
diff --git a/use-timescale/metrics-logging/metrics-to-prometheus.md b/use-timescale/metrics-logging/metrics-to-prometheus.md
index df2e3c2a6d..6bfbb8aa52 100644
--- a/use-timescale/metrics-logging/metrics-to-prometheus.md
+++ b/use-timescale/metrics-logging/metrics-to-prometheus.md
@@ -15,4 +15,4 @@ import PrometheusIntegrate from "versionContent/_partials/_prometheus-integrate.
# Export metrics to Prometheus
-
\ No newline at end of file
+
diff --git a/use-timescale/metrics-logging/monitoring.md b/use-timescale/metrics-logging/monitoring.md
index 26aa5205da..277784dde0 100644
--- a/use-timescale/metrics-logging/monitoring.md
+++ b/use-timescale/metrics-logging/monitoring.md
@@ -29,7 +29,7 @@ This pages explains what specific data you get at each point.
$CLOUD_LONG shows you CPU, memory, and storage metrics for up to 30 previous days and with down to 10-second granularity.
To access metrics, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Metrics`:
-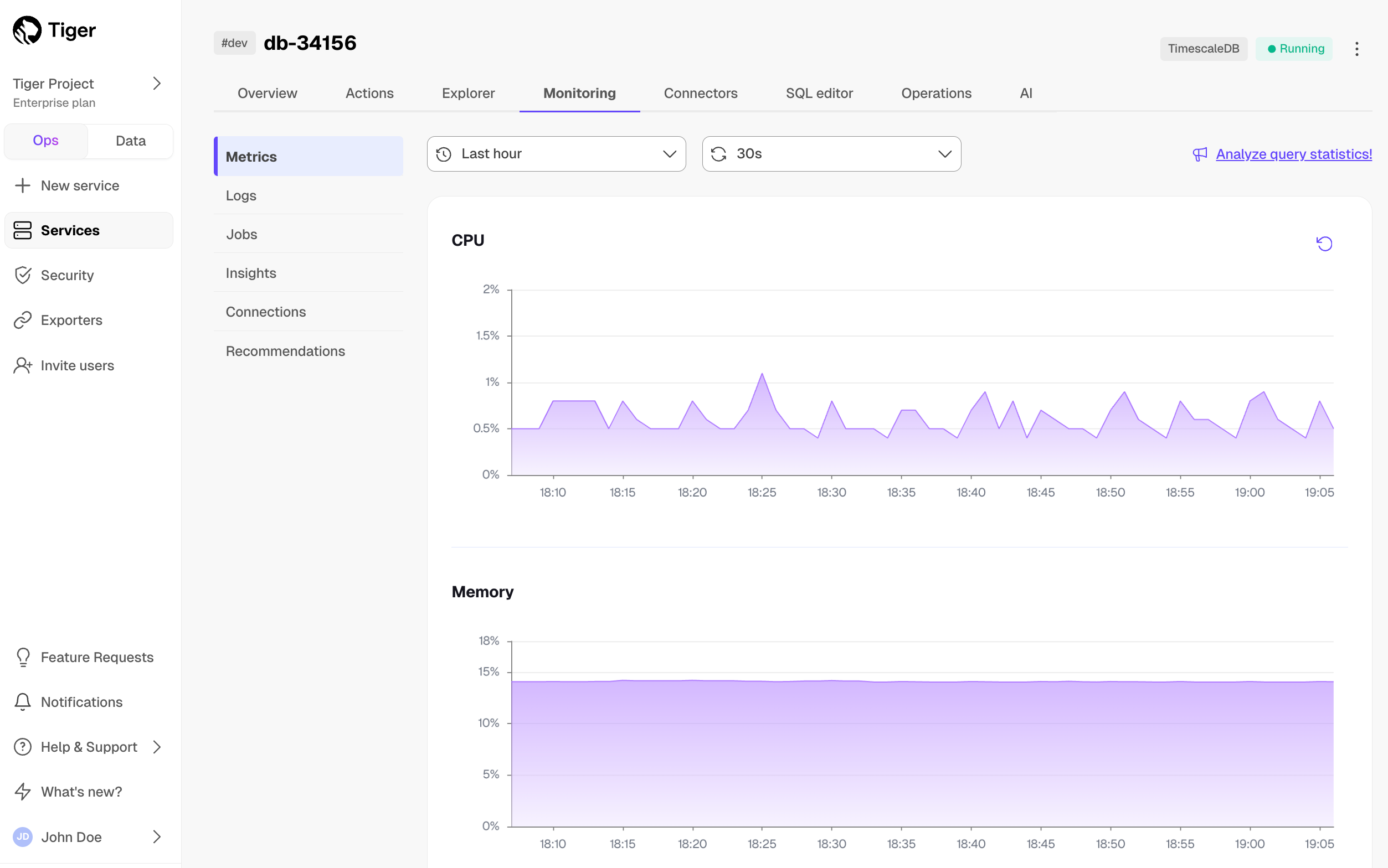
+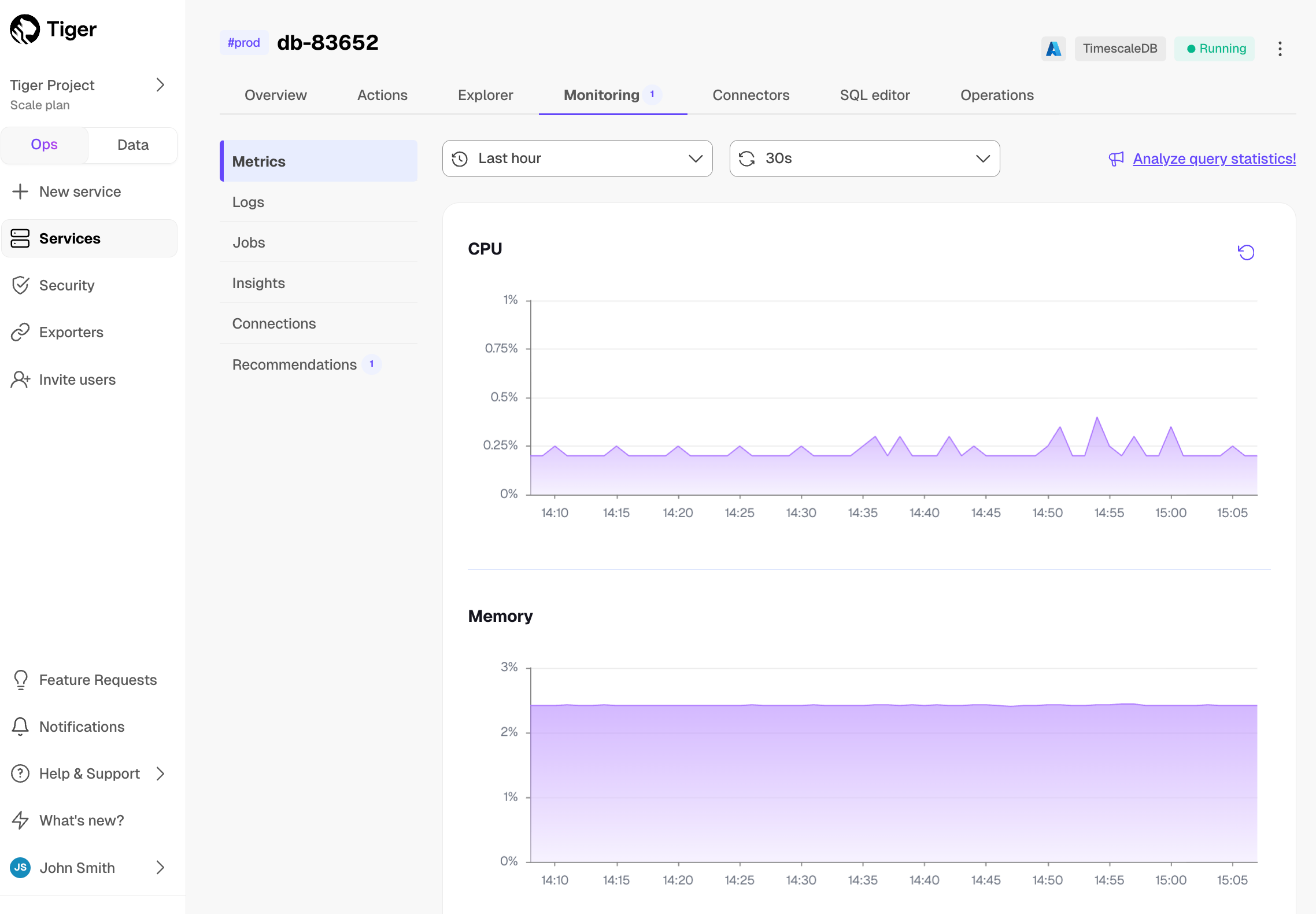
The following metrics are represented by graphs:
@@ -95,7 +95,7 @@ $CLOUD_LONG shows you detailed logs for your $SERVICE_SHORT, which you can filte
To access logs, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Logs`:
-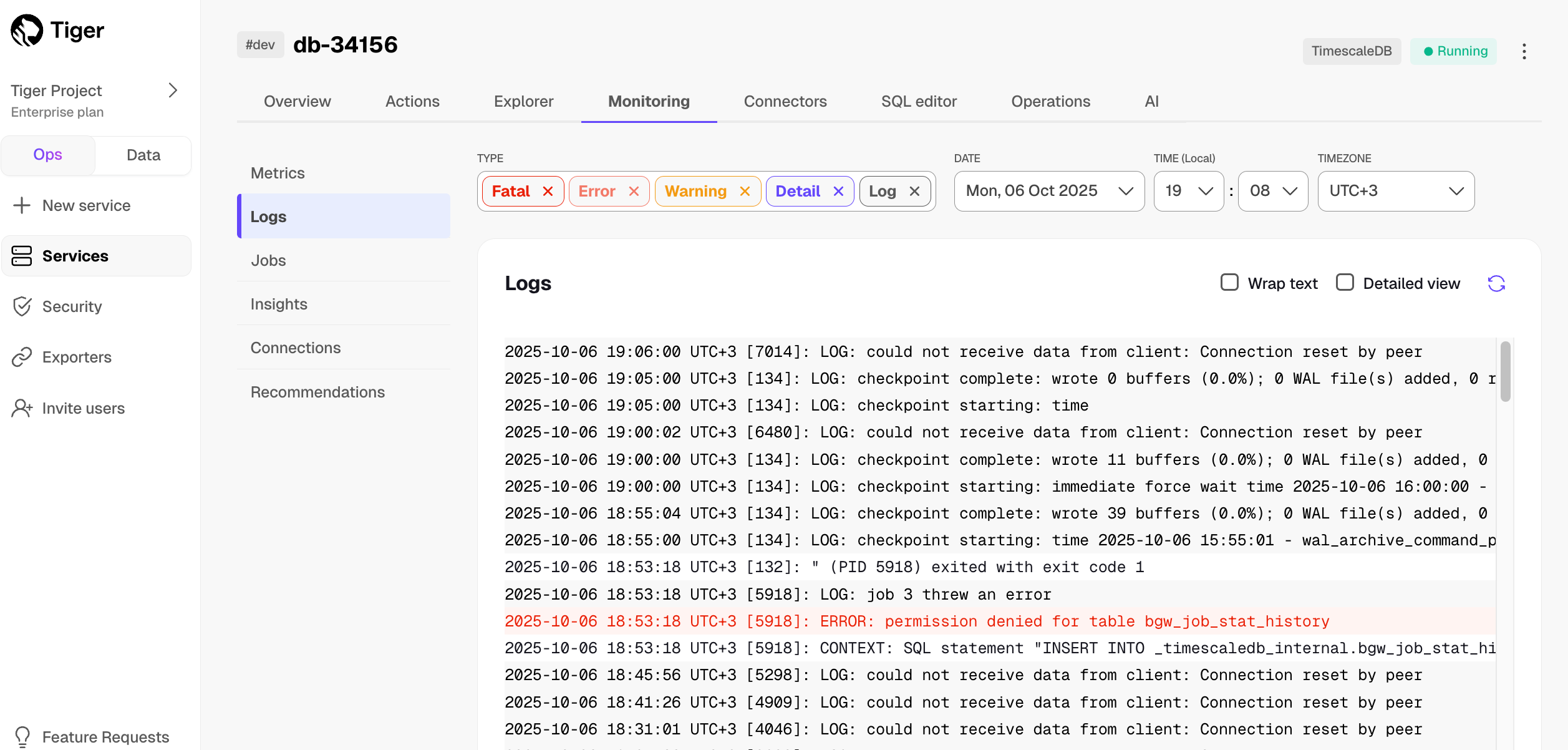
+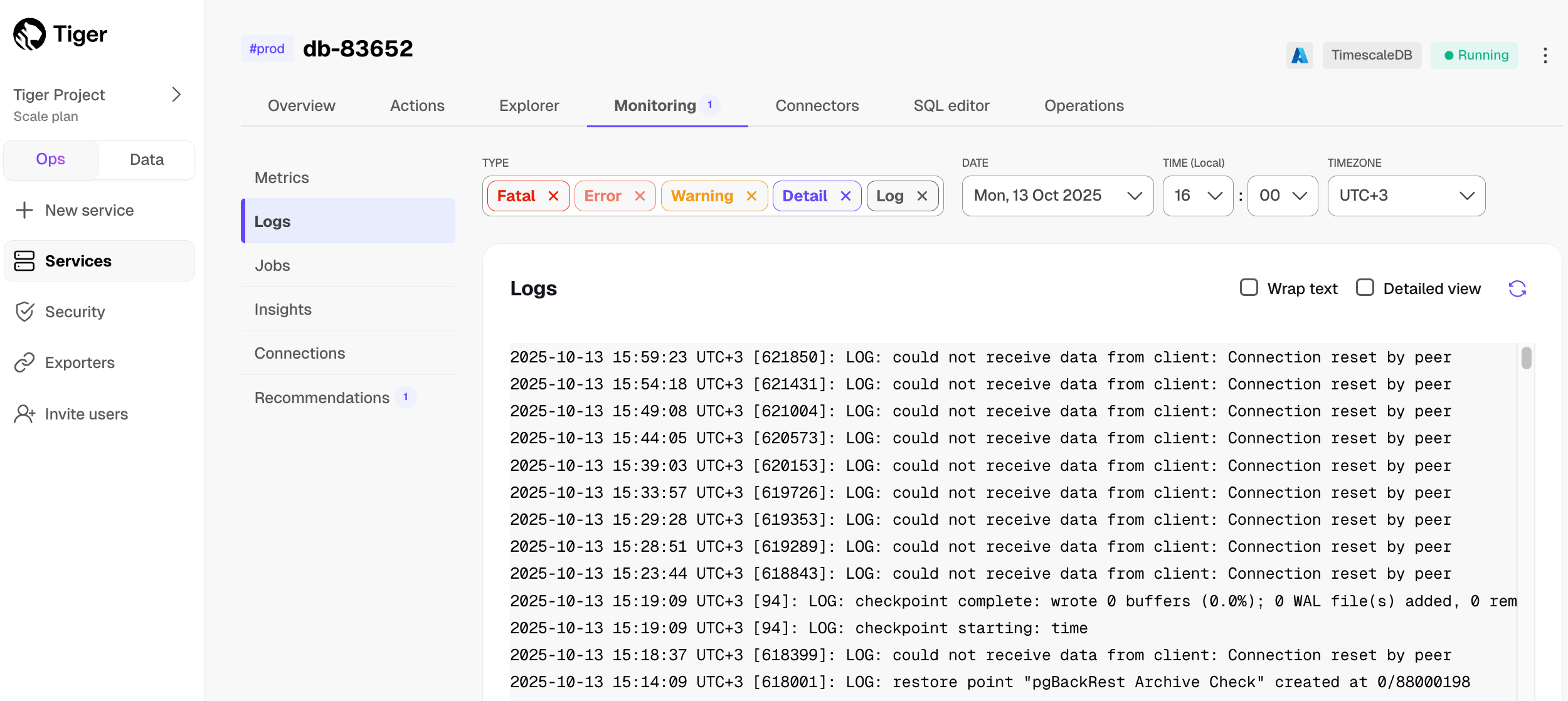
## Insights
@@ -103,7 +103,7 @@ Insights help you get a comprehensive understanding of how your queries perform
To view insights, select your $SERVICE_SHORT, then click `Monitoring` > `Insights`. Search or filter queries by type, maximum execution time, and time frame.
-
+
Insights include `Metrics`, `Current lock contention`, and `Queries`.
@@ -138,7 +138,7 @@ query. Check out the last update value at the top of the query table to identify
Click a query in the list to see the drill-down view. This view not only helps you identify spikes and unexpected behaviors, but also offers information to optimize your query.
-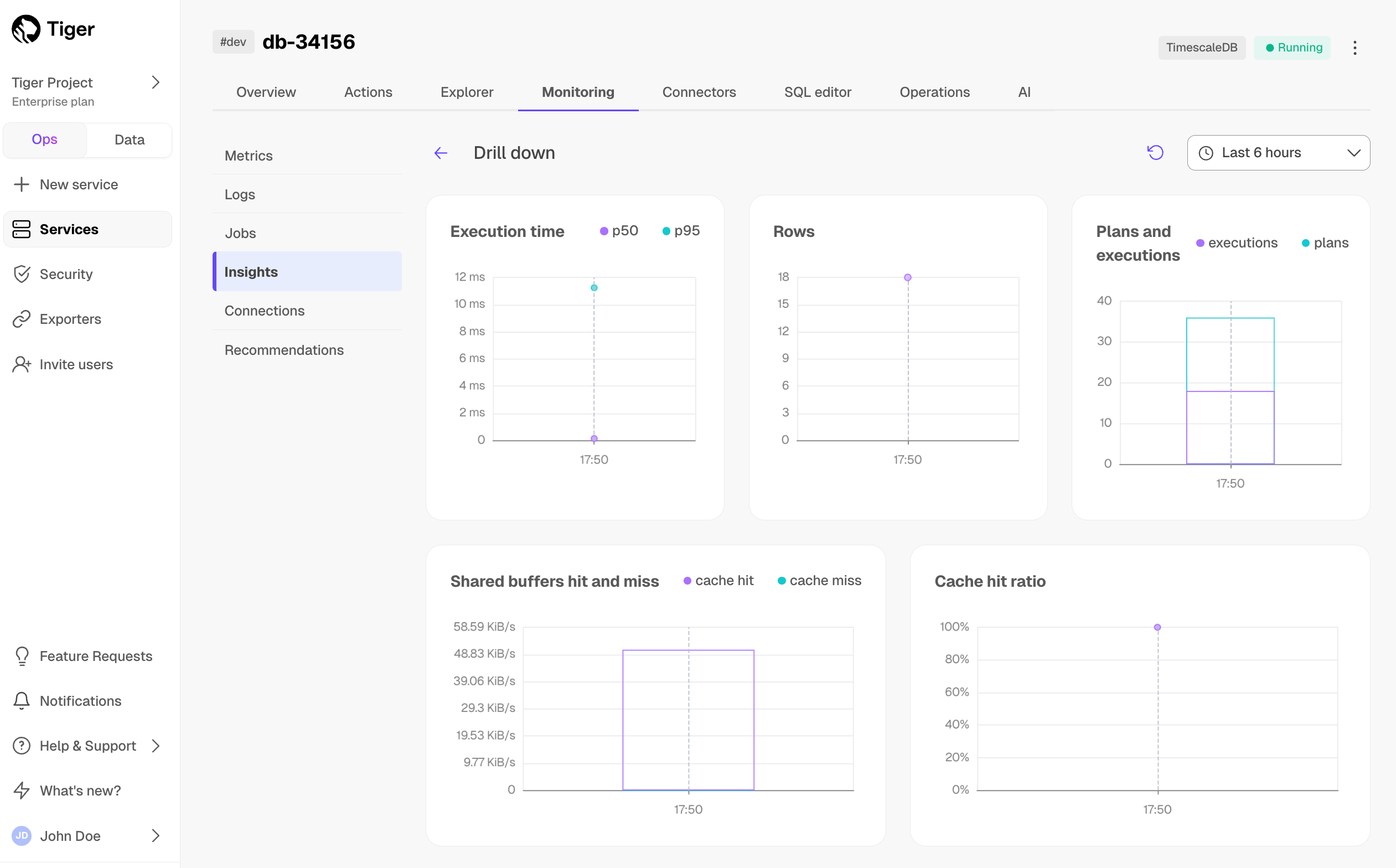
+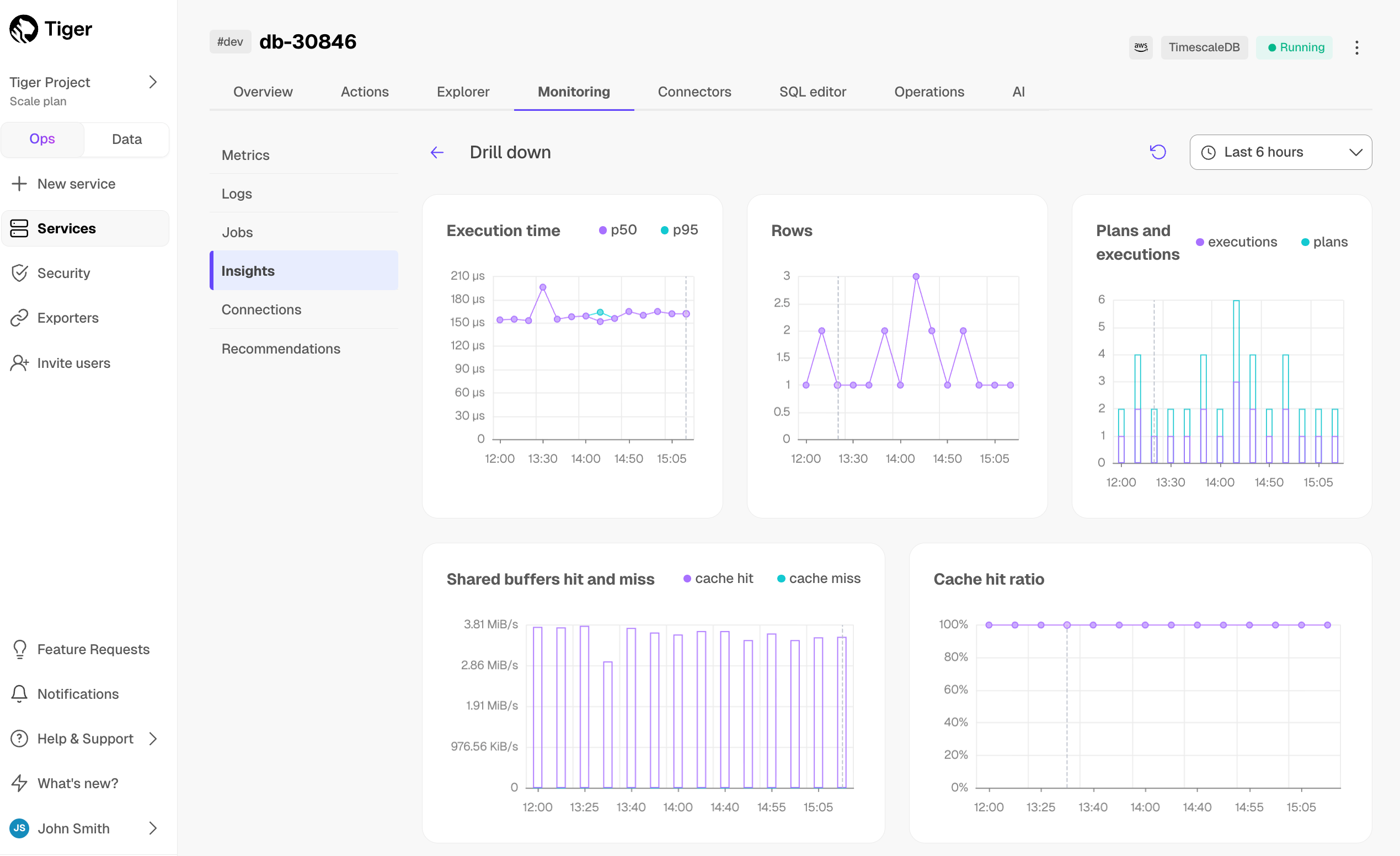
This view includes the following graphs:
@@ -157,11 +157,11 @@ $CLOUD_LONG summarizes all [$JOBs][jobs] set up for your $SERVICE_SHORT along wi
1. To view $JOBs, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Jobs`:
- 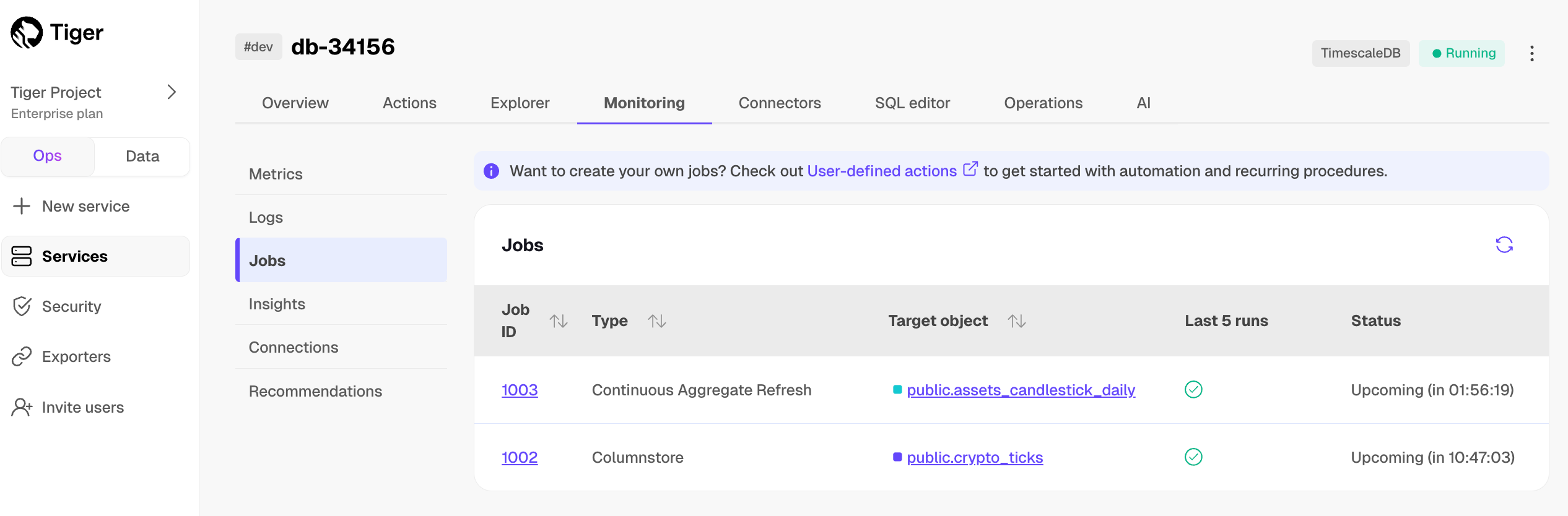
+ 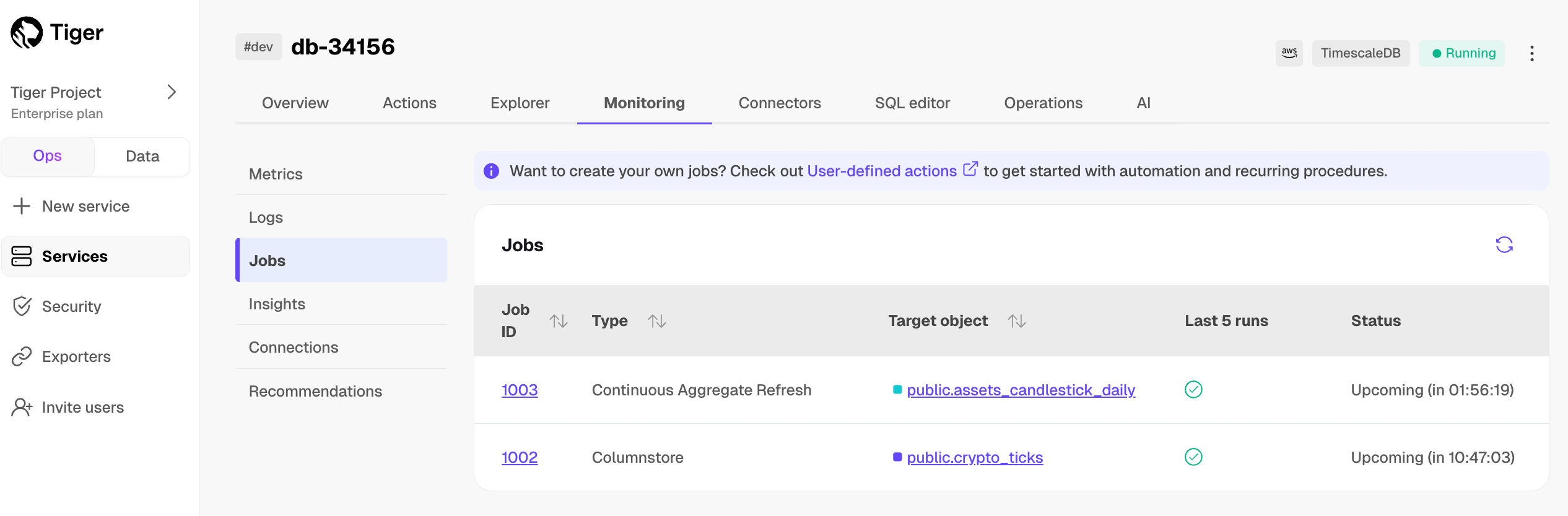
1. Click a $JOB ID in the list to view its config and run history:
- 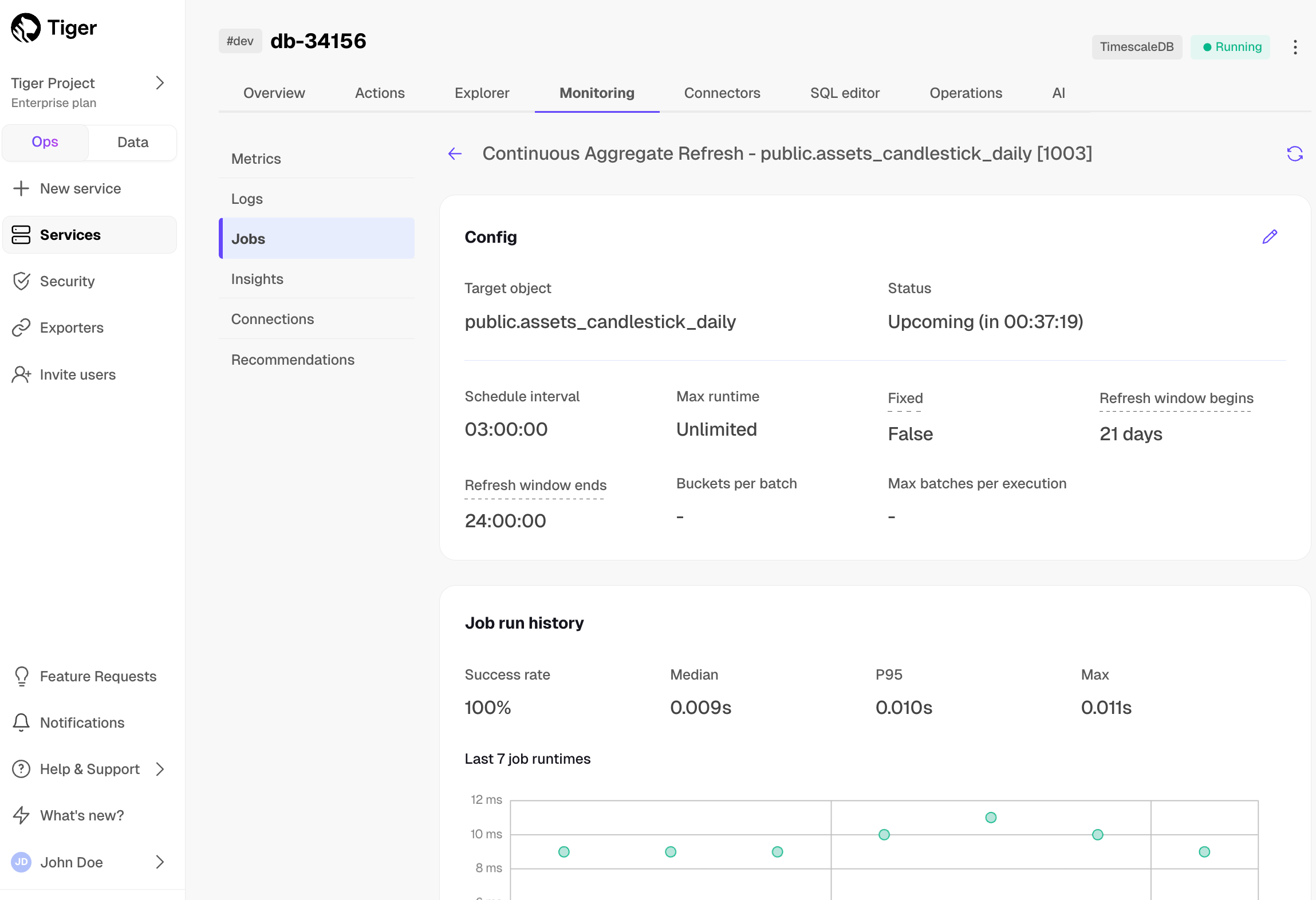
+ 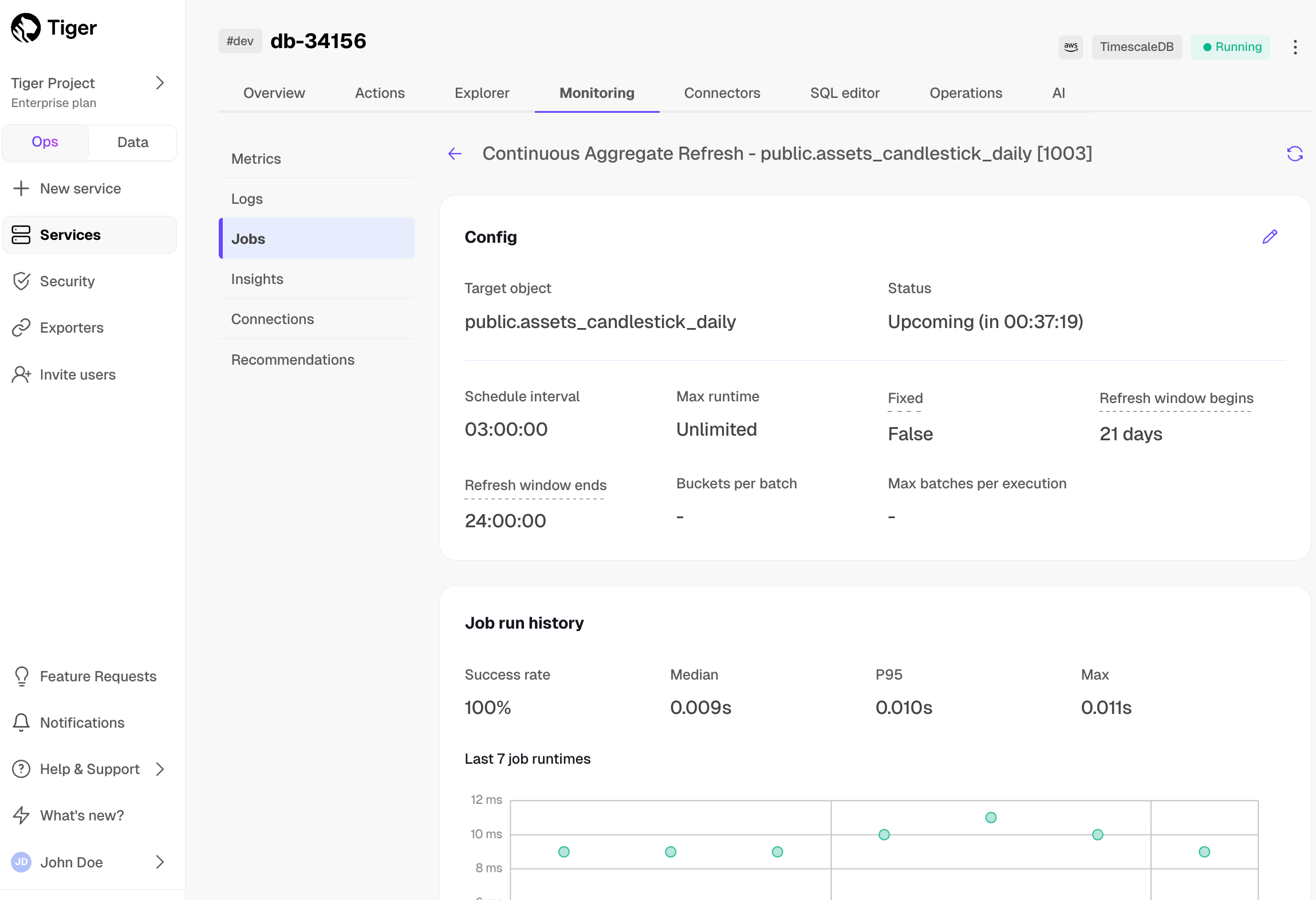
1. Click the pencil icon to edit the $JOB config:
@@ -175,7 +175,7 @@ $CLOUD_LONG lists current and past connections to your $SERVICE_SHORT. This incl
To view connections, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Connections`. Expand the query underneath each connection to see the full SQL.
-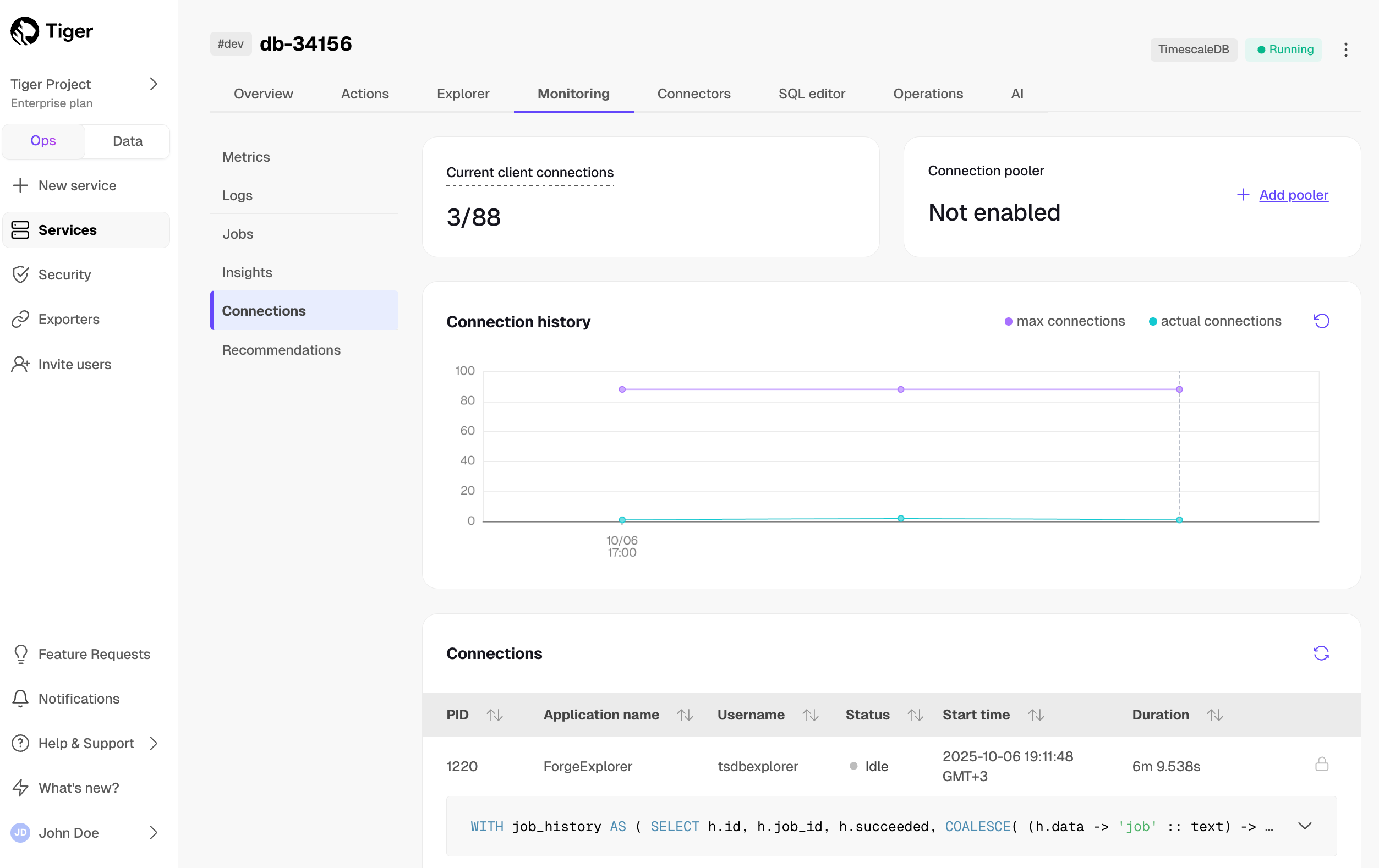
+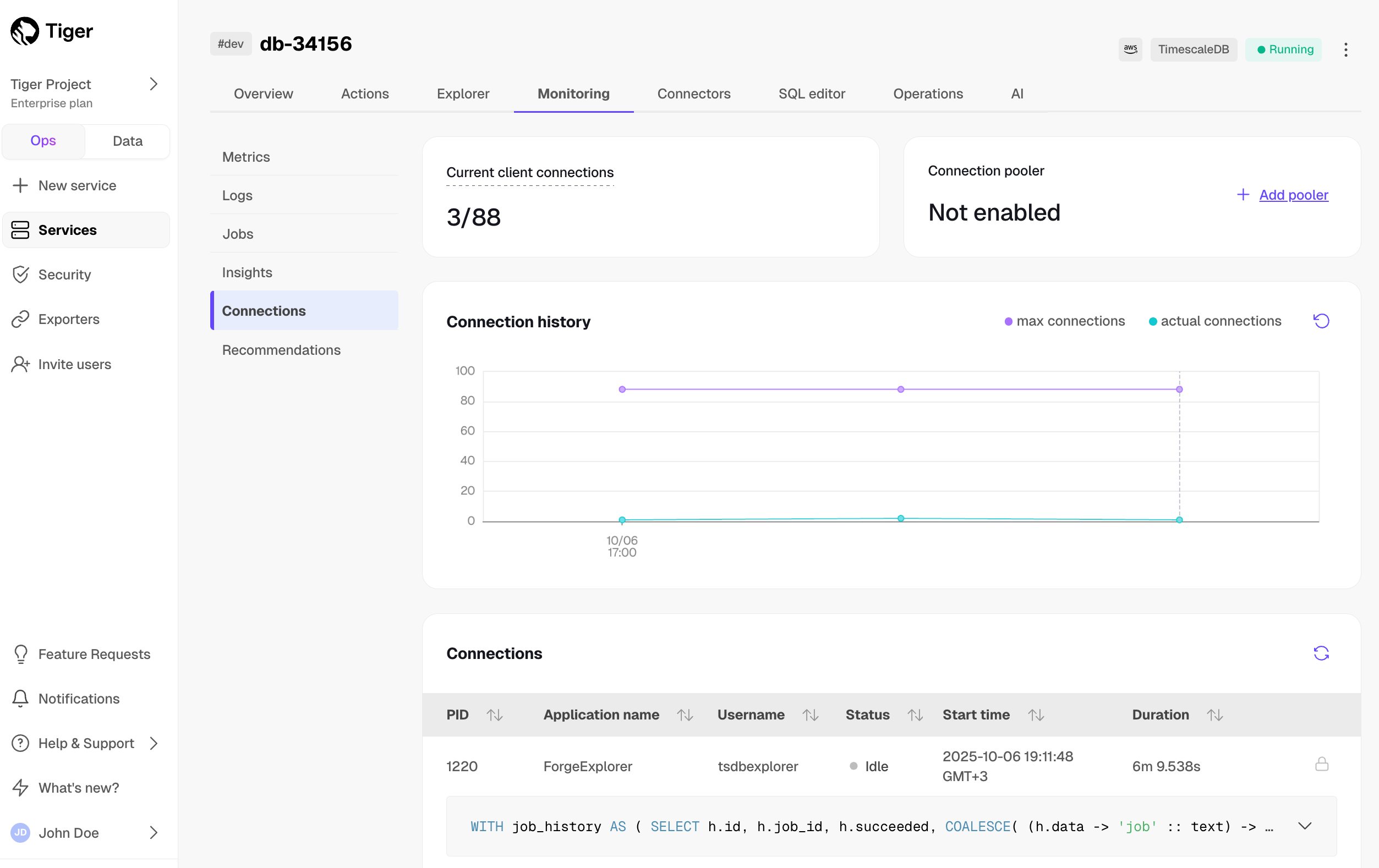
Click the trash icon next to a connection in the list to terminate it. A lock icon means that a connection cannot be terminated; hover over the icon to see the reason.
@@ -185,7 +185,7 @@ $CLOUD_LONG offers specific tips on configuring your $SERVICE_SHORT. This includ
To view recommendations, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Recommendations`:
-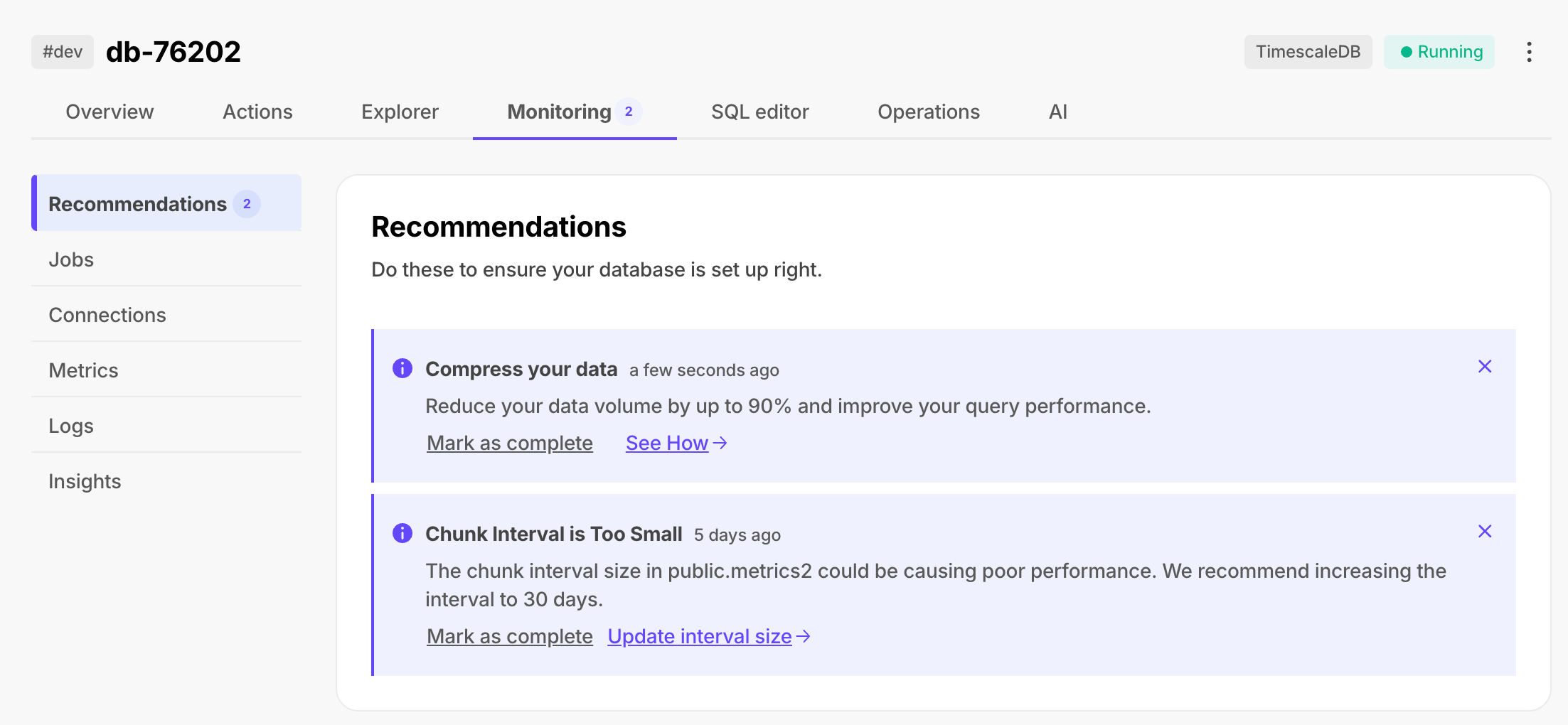
+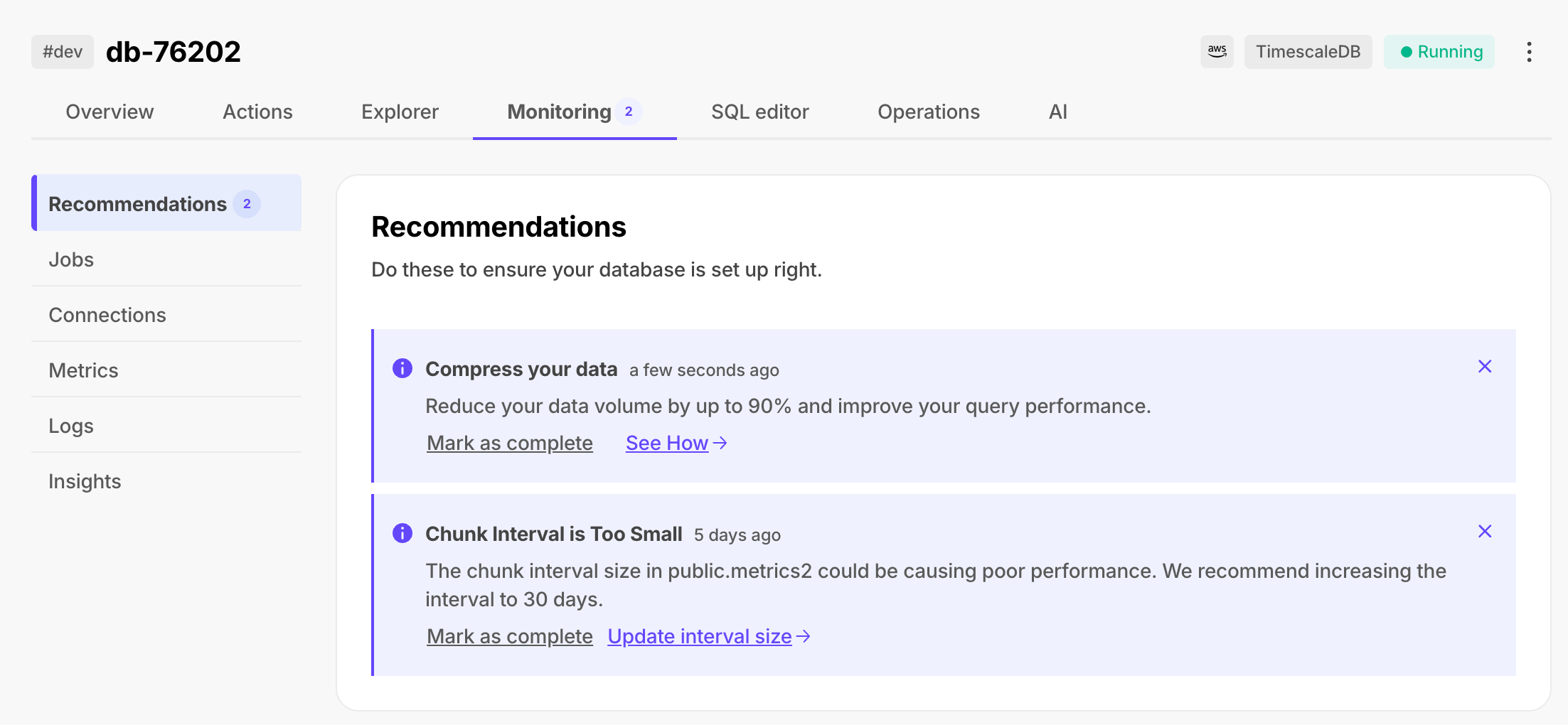
## Query-level statistics with `pg_stat_statements`
diff --git a/use-timescale/security/ip-allow-list.md b/use-timescale/security/ip-allow-list.md
index 6a579bdf9b..c7510405fa 100644
--- a/use-timescale/security/ip-allow-list.md
+++ b/use-timescale/security/ip-allow-list.md
@@ -38,7 +38,7 @@ You attach a $SERVICE_SHORT to either one $VPC, or one IP allow list. You cannot
1. **Select a $SERVICE_LONG, then click `Operations` > `Security` > `IP Allow List`**
- 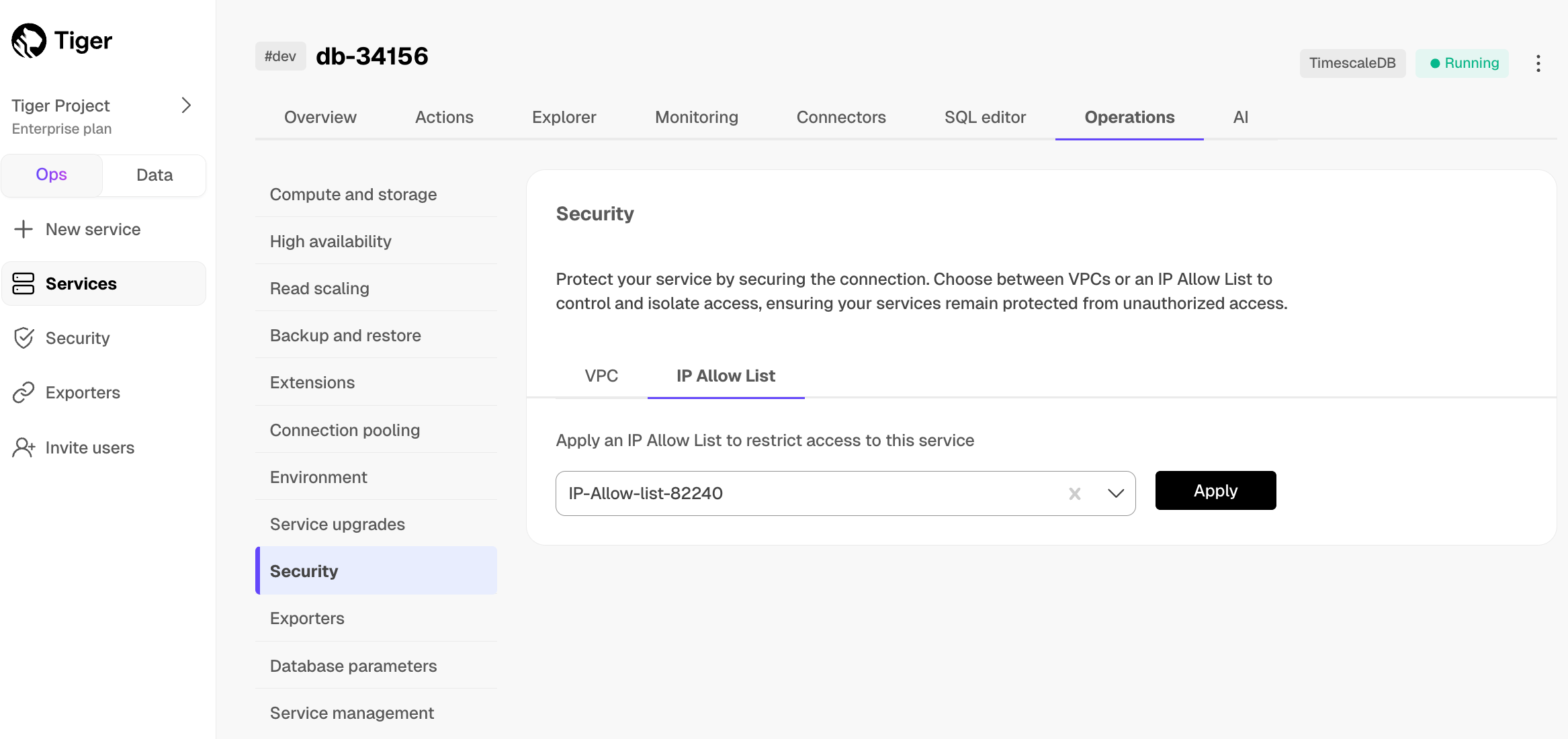
+ 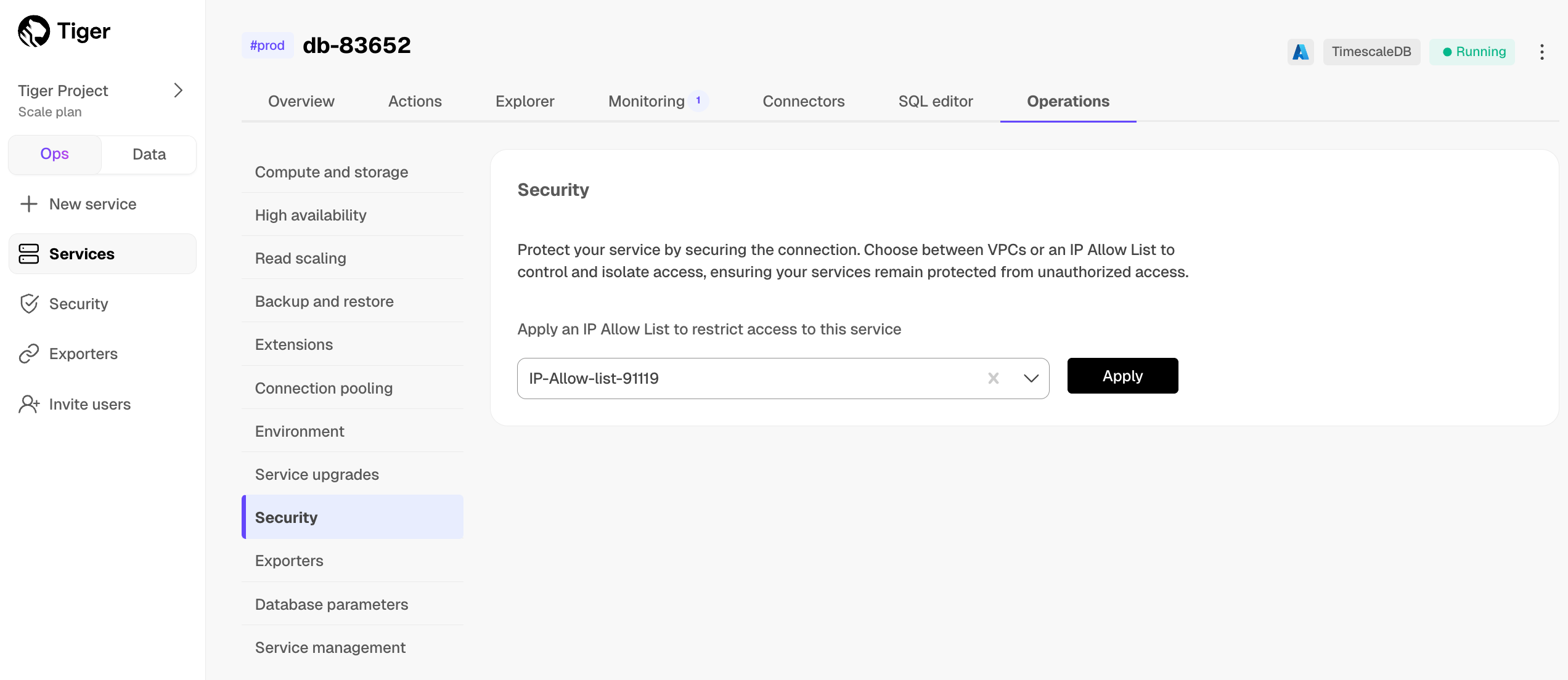
1. **Select the list in the drop-down and click `Apply`**
diff --git a/use-timescale/security/transit-gateway.md b/use-timescale/security/transit-gateway.md
index 735488b652..8721a3aece 100644
--- a/use-timescale/security/transit-gateway.md
+++ b/use-timescale/security/transit-gateway.md
@@ -11,11 +11,14 @@ cloud_ui:
---
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Securely connect to $CLOUD_LONG using AWS Transit Gateway
[AWS Transit Gateway][aws-transit-gateway] enables you to securely connect to your $CLOUD_LONG from AWS, Google Cloud, Microsoft Azure, or any other cloud or on-premise environment.
+
+
You use AWS Transit Gateway as a traffic controller for your network. Instead of setting up multiple direct connections to different clouds, on-premise data centers, and other AWS services, you connect everything to AWS Transit Gateway. This simplifies your network and makes it easier to manage and scale.
You can then create a peering connection between your $SERVICE_LONGs and AWS Transit Gateway in $CLOUD_LONG. This means that, no matter how big or complex your infrastructure is, you can connect securely to your $SERVICE_LONGs.
@@ -87,7 +90,7 @@ AWS Transit Gateway enables you to connect from almost any environment, this pag
-You can now securely access your $SERVICE_SHORTs in $CLOUD_LONG.
+You can now securely access your $SERVICE_SHORTs in $CLOUD_LONG.
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
diff --git a/use-timescale/security/vpc.md b/use-timescale/security/vpc.md
index edccadb84b..f195b8d3fe 100644
--- a/use-timescale/security/vpc.md
+++ b/use-timescale/security/vpc.md
@@ -11,6 +11,7 @@ cloud_ui:
---
import VpcLimitations from "versionContent/_partials/_vpc-limitations.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Secure your $CLOUD_LONG services with $VPC Peering and AWS PrivateLink
@@ -18,6 +19,8 @@ You use Virtual Private Cloud ($VPC) peering to ensure that your $SERVICE_LONGs
only accessible through your secured AWS infrastructure. This reduces the potential
attack vector surface and improves security.
+
+
The data isolation architecture that ensures a highly secure connection between your apps and
$CLOUD_LONG is:
@@ -216,6 +219,7 @@ Migration takes a few minutes to complete and requires a change to DNS settings
$SERVICE_SHORT. The $SERVICE_SHORT is not accessible during this time. If you receive a DNS error, allow
some time for DNS propagation.
+
[aws-dashboard]: https://console.aws.amazon.com/vpc/home#PeeringConnections:
[aws-security-groups]: https://console.aws.amazon.com/vpcconsole/home#securityGroups:
[console-login]: https://console.cloud.timescale.com/
diff --git a/use-timescale/services/change-resources.md b/use-timescale/services/change-resources.md
index bacac5a2ba..e9763c98e9 100644
--- a/use-timescale/services/change-resources.md
+++ b/use-timescale/services/change-resources.md
@@ -25,7 +25,7 @@ You can change the CPU and memory allocation for your $SERVICE_SHORT at any time
minimal downtime, usually less than a minute. The new resources become available as soon as
the $SERVICE_SHORT restarts. You can change the CPU and memory allocation up or down, as frequently as required.
-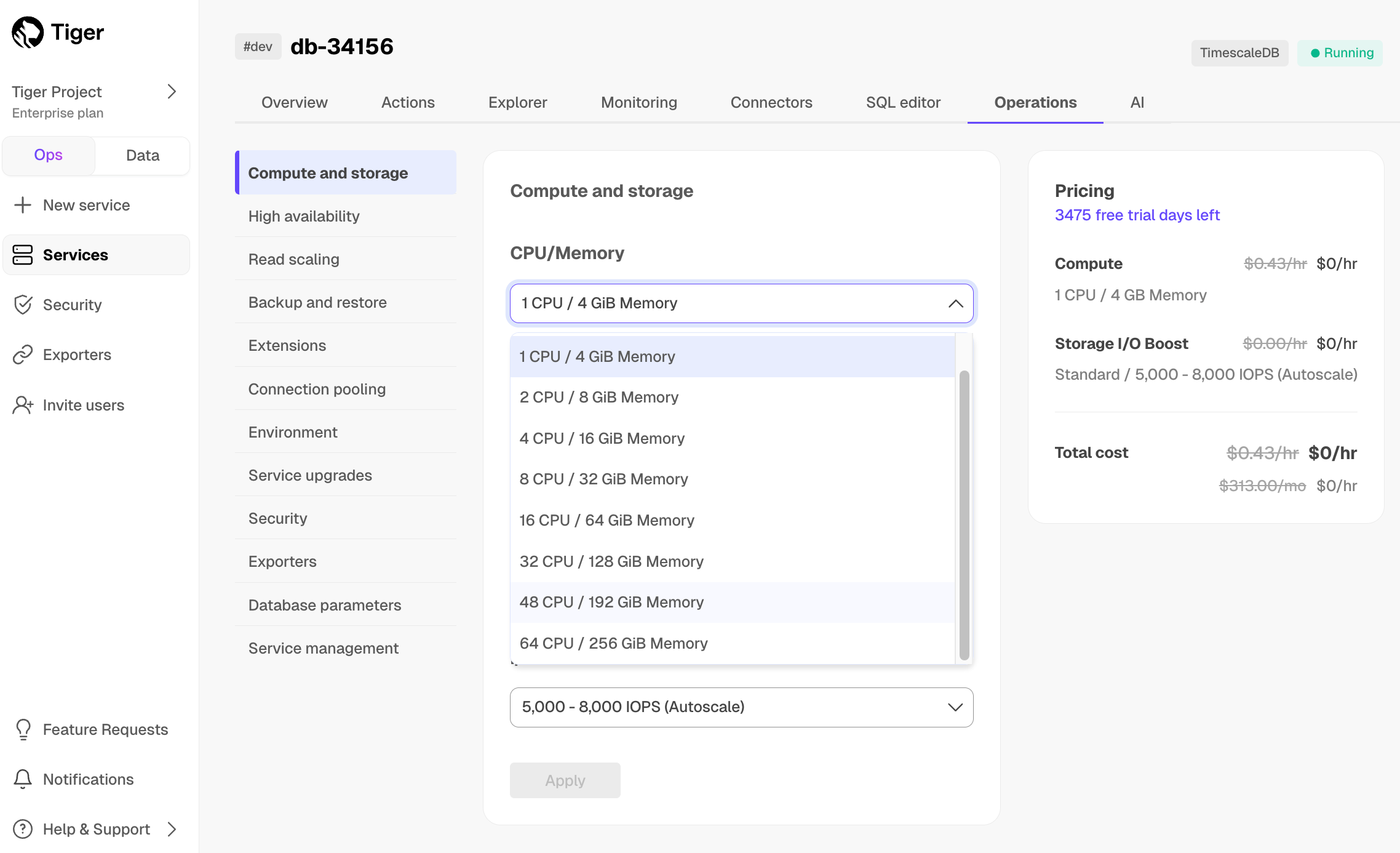
+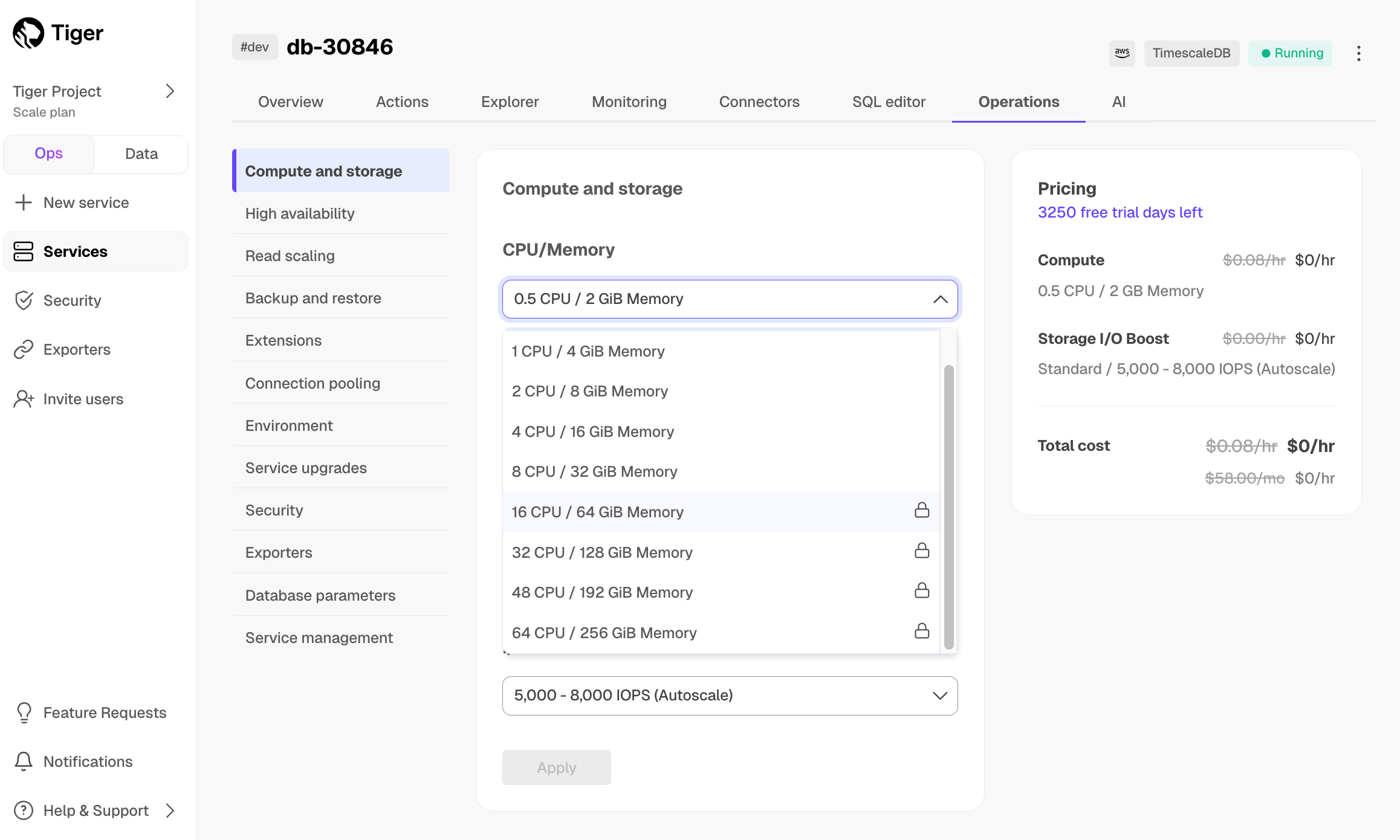
Note that:
@@ -73,7 +73,7 @@ memory than is available.
When this happens, an `OOM killer` process shuts down $PG processes using
`SIGKILL` commands until the memory usage falls below the upper limit. Because
-this kills the entire server process, it usually requires a restart.
+this kills the entire server process, it usually requires a restart.
To prevent $SERVICE_SHORT disruption caused by OOM errors, $CLOUD_LONG attempts to
shut down only the query that caused the problem. This means that the
@@ -85,11 +85,11 @@ operate normally.
```yml
2021-09-09 18:15:08 UTC [560567]:TimescaleDB: LOG: server process (PID 2351983) was terminated by signal 9: Killed
```
-
- Wait for the $SERVICE_SHORT to come back online before reconnecting.
-* $CLOUD_LONG shuts the client connection only
-
+ Wait for the $SERVICE_SHORT to come back online before reconnecting.
+
+* $CLOUD_LONG shuts the client connection only
+
If $CLOUD_LONG successfully guards the $SERVICE_SHORT against the OOM killer, it shuts
down only the client connection that was using too much memory. This prevents
the entire $SERVICE_SHORT from shutting down, so you can reconnect immediately. The error log looks like this:
diff --git a/use-timescale/services/service-explorer.md b/use-timescale/services/service-explorer.md
index f9527a2e6c..f0cbfd2f17 100644
--- a/use-timescale/services/service-explorer.md
+++ b/use-timescale/services/service-explorer.md
@@ -30,7 +30,7 @@ summary of your $SERVICE_SHORT, including all your hypertables and
relational tables. It summarizes your overall compression ratios, and other
policy and continuous aggregate data. And, if you aren't already using key features like continuous aggregates, columnstore compression, or other automation policies and actions, it provides pointers to tutorials and documentation to help you get started.
-
+
## Tables
@@ -43,7 +43,7 @@ ranges, and columnstore compression status.
From this section, you can also set an automated policy to compress chunks into the columnstore. For more information,
see the [hypercore documentation][hypercore].
-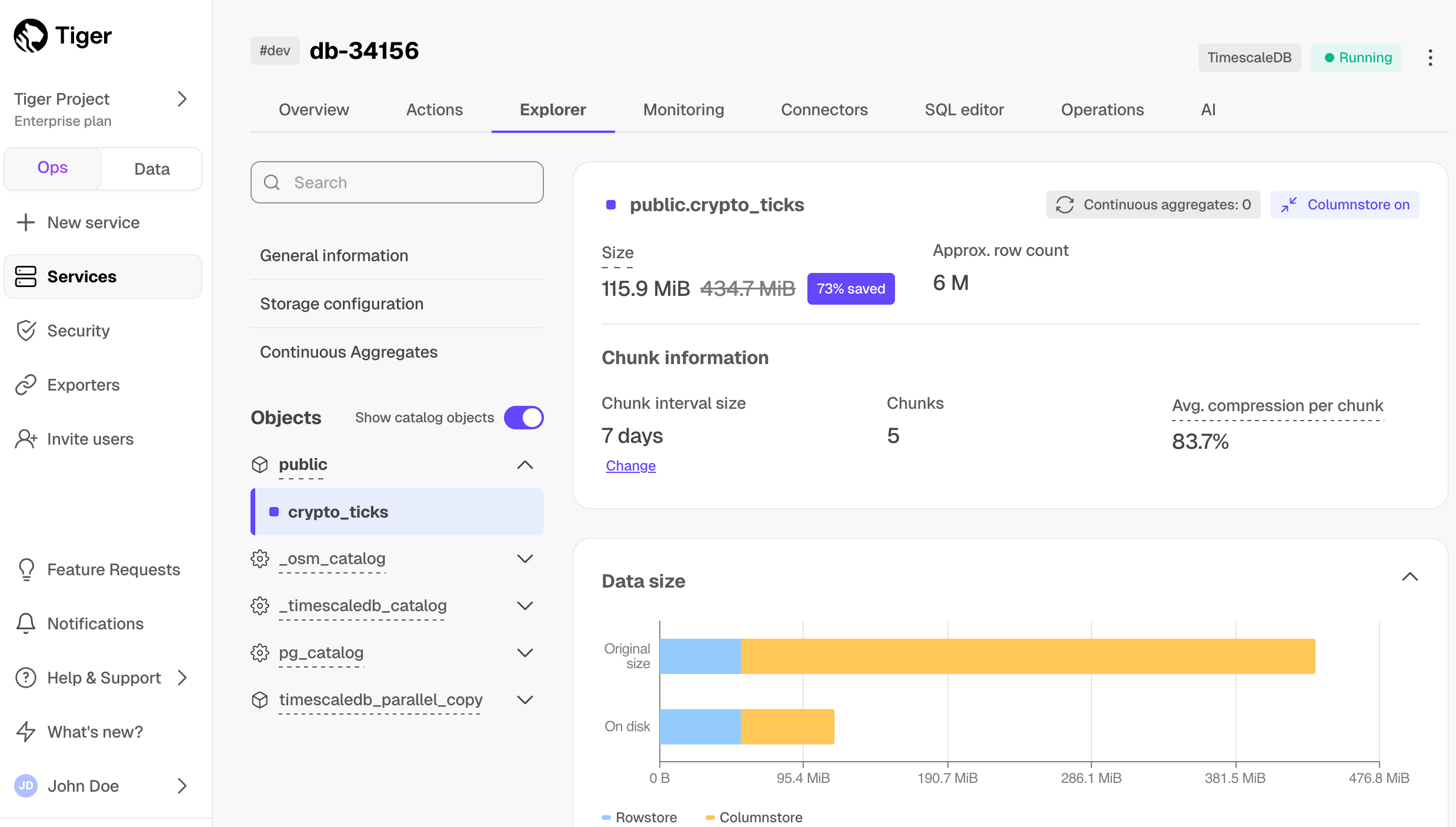
+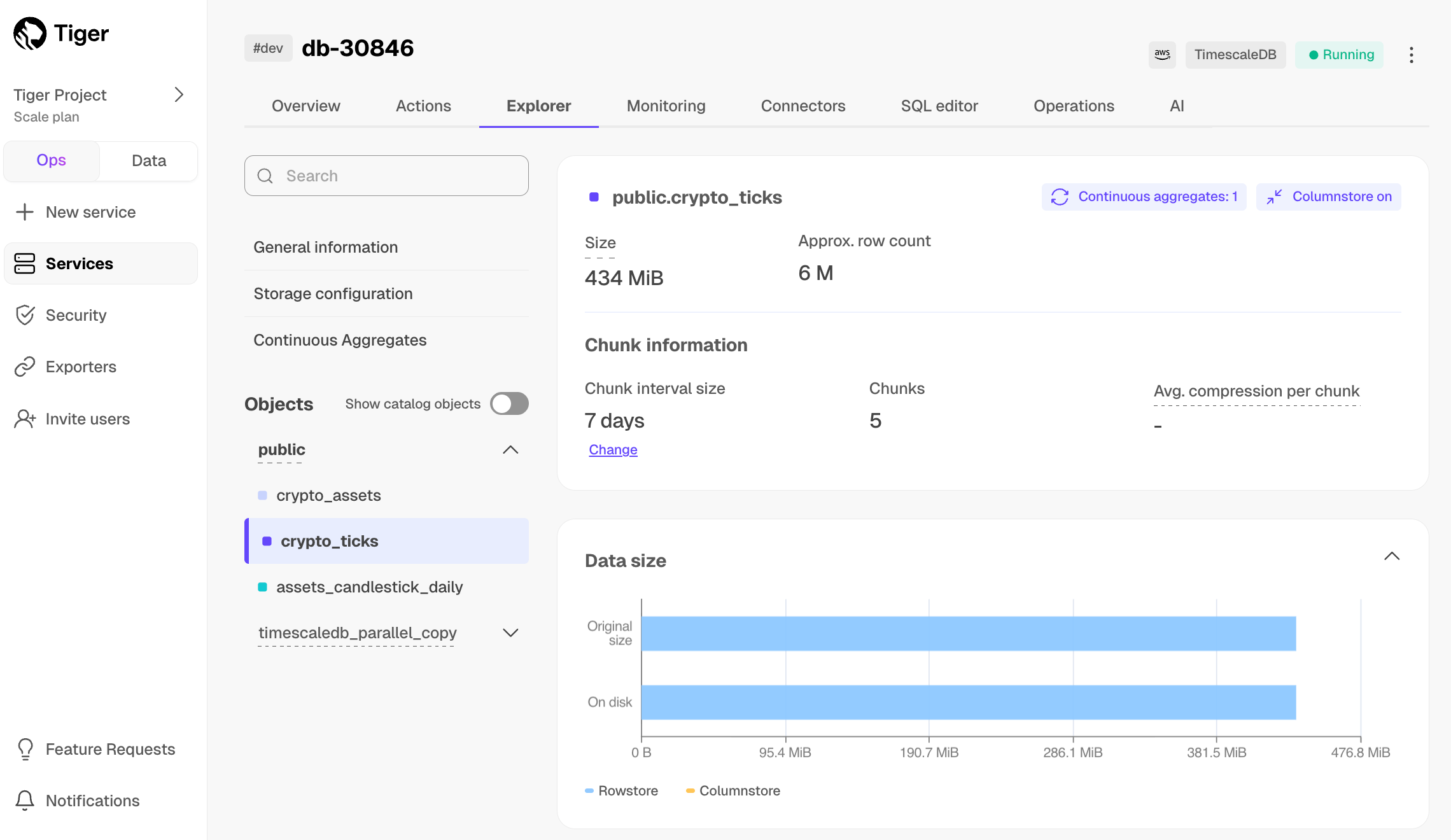
For more information about hypertables, see the
@@ -55,7 +55,7 @@ In the `Continuous aggregate` section, you can see all your continuous
aggregates, including top-level information such as their size, whether they are
configured for real-time aggregation, and their refresh periods.
-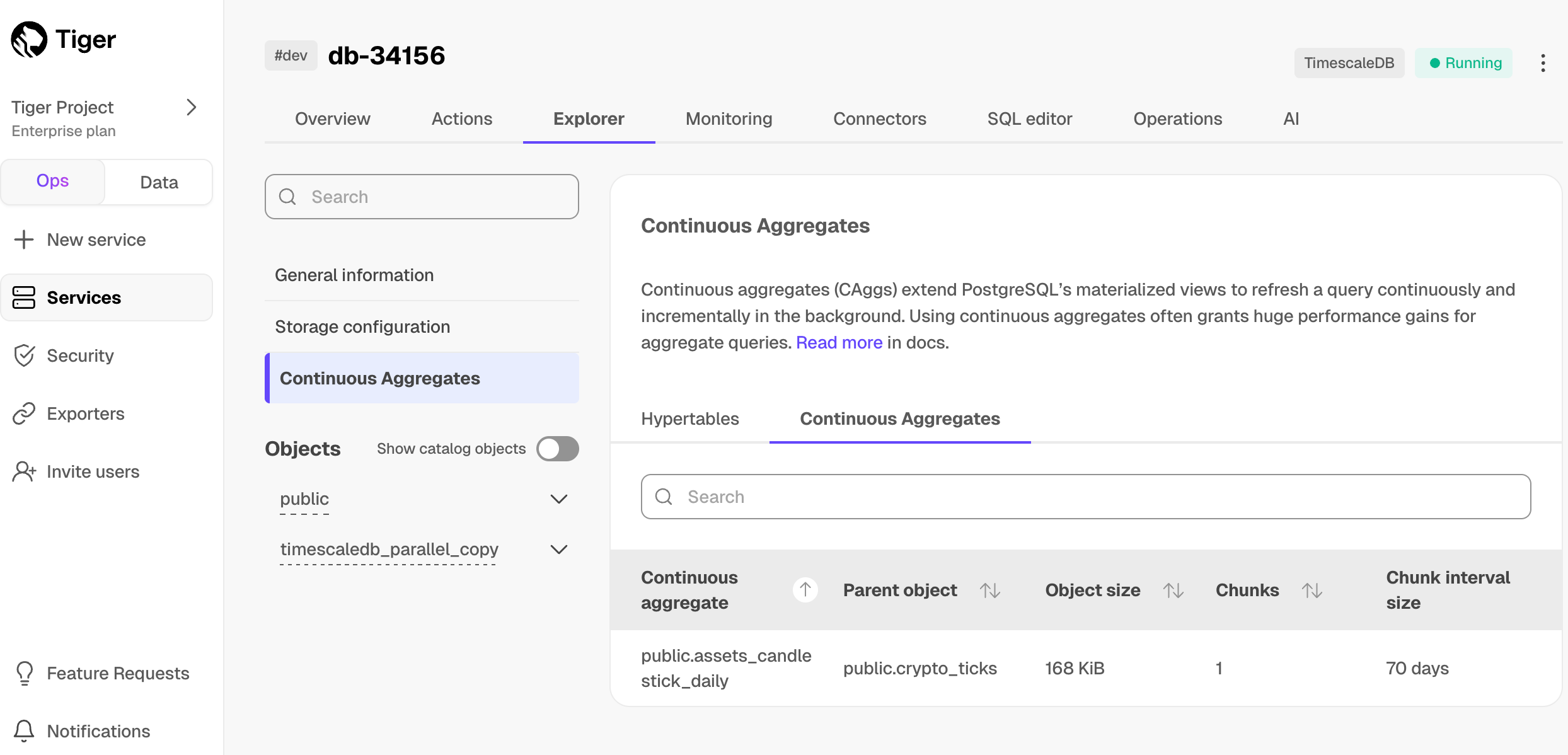
+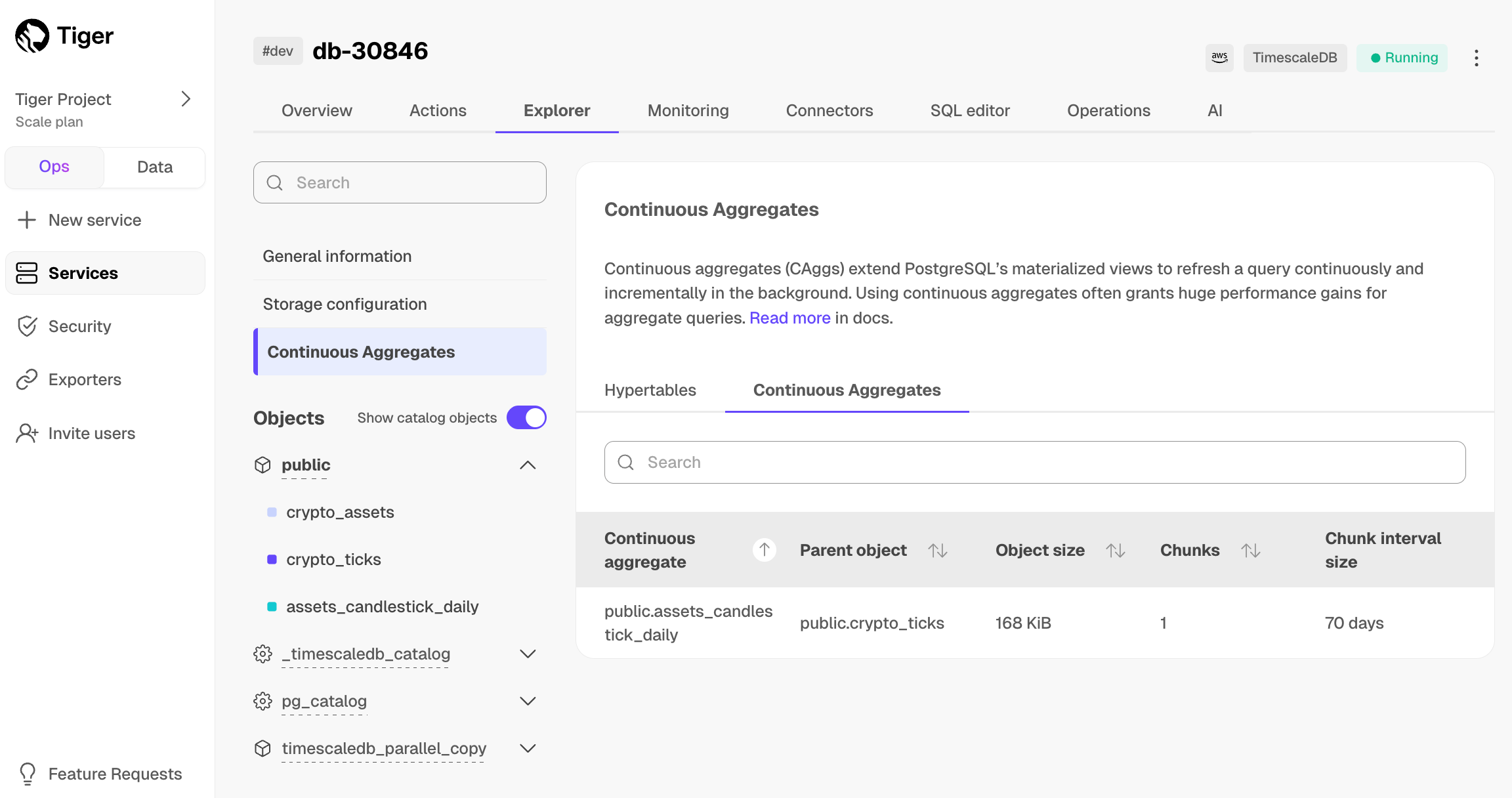
For more information about continuous aggregates, see the
[continuous aggregates section][caggs].
diff --git a/use-timescale/services/service-overview.md b/use-timescale/services/service-overview.md
index 8f312fca1b..371ed4332b 100644
--- a/use-timescale/services/service-overview.md
+++ b/use-timescale/services/service-overview.md
@@ -9,37 +9,52 @@ cloud_ui:
- [services, :serviceId, overview]
---
import ServiceOverview from "versionContent/_partials/_service-overview.mdx";
+import ServiceOverviewAzure from "versionContent/_partials/_service-overview-azure.mdx";
+import ServiceUsers from "versionContent/_partials/_service-users.mdx";
# About $SERVICE_LONGs
+
+
+
+
When you log into [$CONSOLE][cloud-login], you see the
$PROJECT_SHORT overview. Click a $SERVICE_SHORT to view run-time data and connection information.
Click `Operations` to configure your $SERVICE_SHORT.
-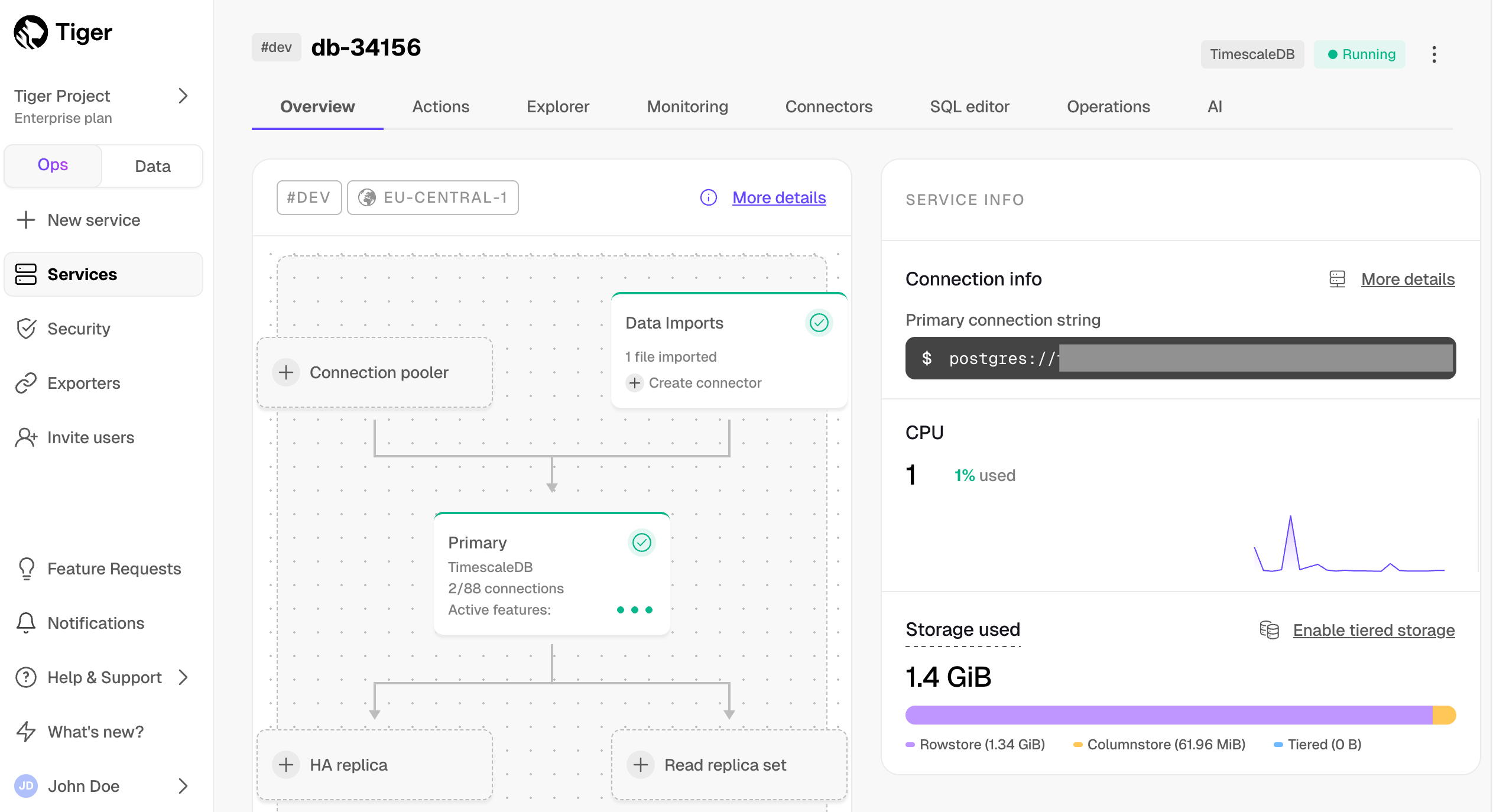
+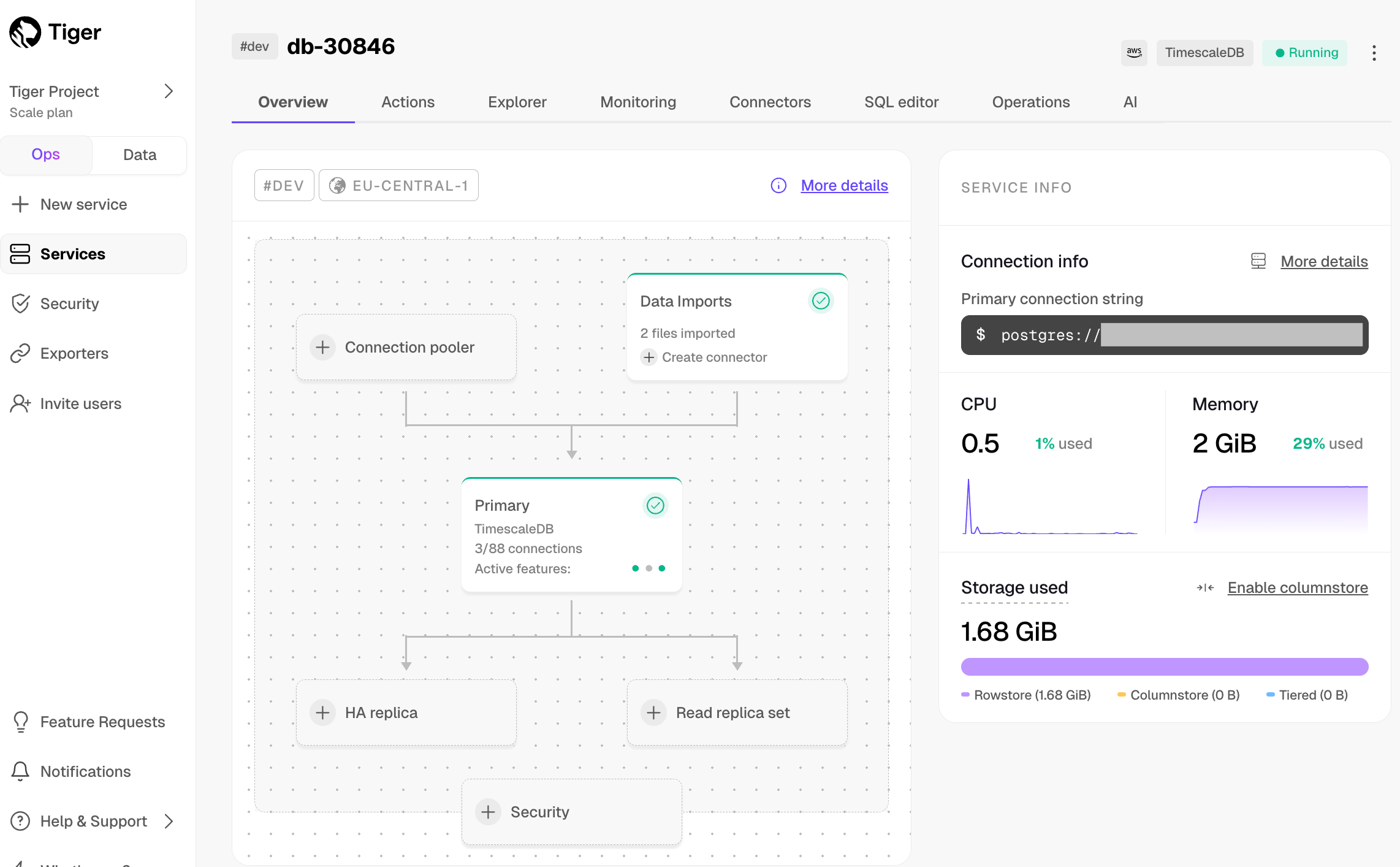
Each $SERVICE_SHORT hosts a single database managed for you by $CLOUD_LONG.
If you need more than one database, [create a new $SERVICE_SHORT][create-service].
## $SERVICE_SHORT_CAP users
-By default, when you create a new $SERVICE_SHORT, a new `tsdbadmin` user is created.
-This is the user that you use to connect to your new $SERVICE_SHORT.
+
+
+
+
+
+
+
-
+When you log into [$CONSOLE][cloud-login], you see the
+$PROJECT_SHORT overview. Click a $SERVICE_SHORT to view run-time data and connection information.
+Click `Operations` to configure your $SERVICE_SHORT.
+
+
-The `tsdbadmin` user is the owner of the database, but is not a superuser. You
-cannot access the `postgres` user. There is no superuser access to $CLOUD_LONG databases.
+Each $SERVICE_SHORT hosts a single database managed for you by $CLOUD_LONG.
+If you need more than one database, [create a new $SERVICE_SHORT][create-service].
+
+## $SERVICE_SHORT_CAP users
-
+
-In your $SERVICE_SHORT, the `tsdbadmin` user can create another user
-with any other role. For a complete list of roles available, see the
-[$PG role attributes documentation][pg-roles-doc].
+
-You cannot create multiple databases in a single $SERVICE_SHORT. If you need data isolation, use schemas or create additional $SERVICE_SHORTs.
+
[cloud-login]: https://console.cloud.timescale.com/
[pg-roles-doc]: https://www.postgresql.org/docs/current/role-attributes.html
diff --git a/use-timescale/tigerlake.md b/use-timescale/tigerlake.md
index 236ba73e12..235c8a9dad 100644
--- a/use-timescale/tigerlake.md
+++ b/use-timescale/tigerlake.md
@@ -8,6 +8,7 @@ keywords: [data lake, lakehouse, s3, iceberg]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import EarlyAccessGeneral from "versionContent/_partials/_early_access.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate data lakes with $CLOUD_LONG
@@ -29,6 +30,8 @@ Tiger Lake is currently in private beta. Please contact us to request access.
+
+
## Integrate a data lake with your $SERVICE_LONG
To connect a $SERVICE_LONG to your data lake:
@@ -361,6 +364,9 @@ data lake:
* Writing to the same S3 table bucket from multiple services is not supported, bucket-to-service mapping is one-to-one.
* Iceberg snapshots are pruned automatically if the amount exceeds 2500.
+
+
+
[cmc]: https://console.aws.amazon.com/cloudformation/
[aws-athena]: https://aws.amazon.com/athena/
[apache-spark]: https://spark.apache.org/
diff --git a/use-timescale/upgrades.md b/use-timescale/upgrades.md
index 8bafee0e8c..f12e396d0a 100644
--- a/use-timescale/upgrades.md
+++ b/use-timescale/upgrades.md
@@ -211,7 +211,7 @@ To change your maintenance window:
In [$CONSOLE][cloud-login], select the $SERVICE_SHORT you want to manage.
1. **Set your maintenance window**
1. Click `Operations` > `Environment`, then click `Change maintenance window`.
- 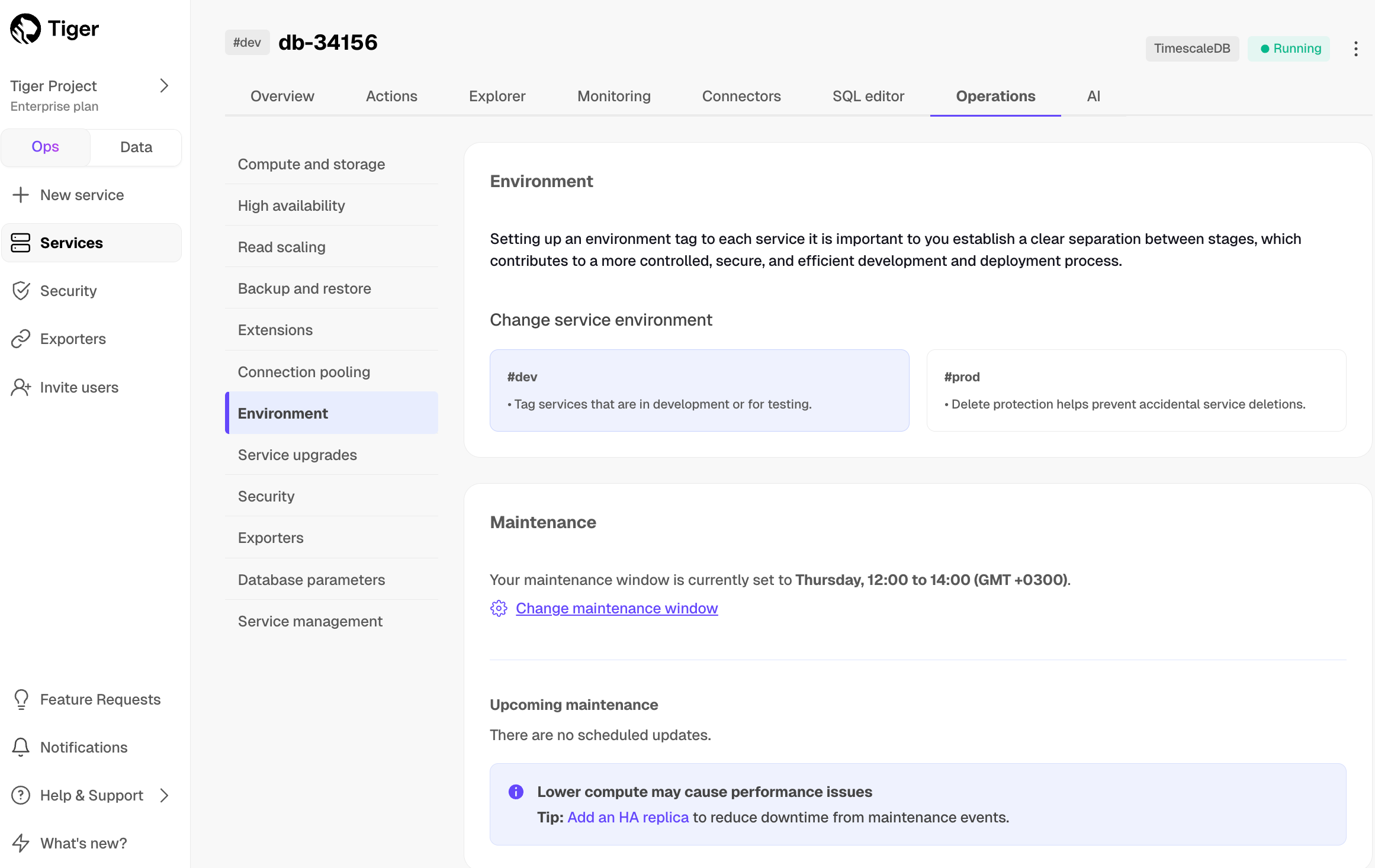
+ 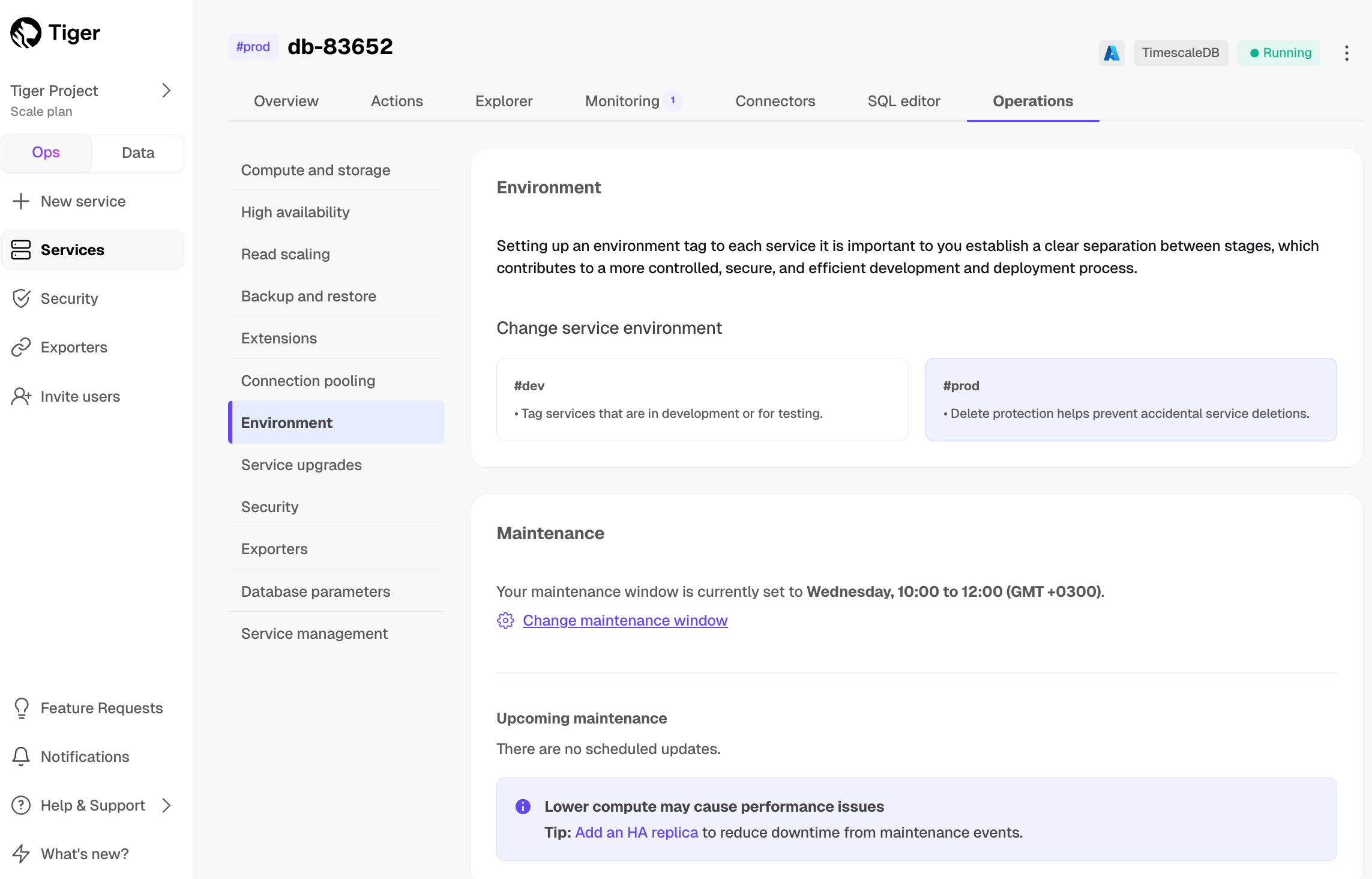
1. Select the maintence window start time, then click `Apply`.
Maintenance windows can run for up to four hours.
-
-- **Details**: an overview of your $PRICING_PLAN, usage, and payment details. You can add up
- to three credit cards to your `Wallet`. If you prefer to pay by invoice,
- [contact $COMPANY][contact-company] and ask to change to corporate billing.
+
-- **History**: the list of your downloadable $CLOUD_LONG invoices.
-- **Emails**: the addresses $COMPANY uses to communicate with you. Payment
- confirmations and alerts are sent to the email address you signed up with.
- Add another address to send details to other departments in your organization.
+
-- **$PRICING_PLAN_CAP**: choose the $PRICING_PLAN supplying the [features][plan-features] that suit your business and
- engineering needs.
-
-- **Add-ons**: add `Production support` and improved database performance for mission-critical workloads.
-
-## AWS Marketplace pricing
-
-When you get $CLOUD_LONG at AWS Marketplace, the following pricing options are available:
-
-- **Pay-as-you-go**: your consumption is calculated at the end of the month and included in your AWS invoice. No upfront costs, standard $CLOUD_LONG rates apply.
-- **Annual commit**: your consumption is calculated at the end of the month ensuring predictable pricing and seamless billing through your AWS account. We confirm the contract terms with you before finalizing the commitment.
+
[cloud-login]: https://console.cloud.timescale.com/
[data-tiering]: /use-timescale/:currentVersion:/data-tiering/
diff --git a/about/supported-platforms.md b/about/supported-platforms.md
index 59ebde05d0..e1bbb9b10a 100644
--- a/about/supported-platforms.md
+++ b/about/supported-platforms.md
@@ -8,6 +8,7 @@ tags: [platforms, os, versions]
import ServiceTypes from "versionContent/_partials/_timescale-cloud-services.mdx";
import Regions from "versionContent/_partials/_timescale-cloud-regions.mdx";
+import RegionsAzure from "versionContent/_partials/_timescale-cloud-regions-azure.mdx";
import Platforms from "versionContent/_partials/_timescale-cloud-platforms.mdx";
# Supported platforms and regions
@@ -32,16 +33,26 @@ See the available [service capabilities][service-types] and [regions][regions].
### Available service capabilities
-
-
### Available regions
-
+
+
+
+
+
+
+
+
+
+
+
+
+
## Self-hosted products
diff --git a/getting-started/get-started-devops-as-code.md b/getting-started/get-started-devops-as-code.md
index 27bac9b31a..fc2a56d2fe 100644
--- a/getting-started/get-started-devops-as-code.md
+++ b/getting-started/get-started-devops-as-code.md
@@ -11,6 +11,7 @@ tags:
- security
- services
- authentication
+products: [cloud]
---
import RESTGS from "versionContent/_partials/_devops-rest-api-get-started.mdx";
diff --git a/getting-started/run-queries-from-console.md b/getting-started/run-queries-from-console.md
index d7623814d3..bdbee2e8c2 100644
--- a/getting-started/run-queries-from-console.md
+++ b/getting-started/run-queries-from-console.md
@@ -57,7 +57,7 @@ To connect to a $SERVICE_SHORT:
In [$CONSOLE][services-portal], check that your $SERVICE_SHORT is marked as `Running`:
- 
+ 
1. **Connect to your $SERVICE_SHORT**
@@ -213,7 +213,7 @@ $SQL_ASSISTANT_SHORT settings are:
$SQL_EDITOR is an integrated secure UI that you use to run queries and see the results
for a $SERVICE_LONG.
-
+
To enable or disable $SQL_EDITOR in your $SERVICE_SHORT, click `Operations` > `Service management`, then
update the setting for $SQL_EDITOR.
@@ -226,13 +226,13 @@ To use $SQL_EDITOR:
In the [$OPS_MODE][portal-ops-mode] in $CONSOLE, select a $SERVICE_SHORT, then click `SQL editor`.
- 
+ 
1. **Run a test query**
Type `SELECT CURRENT_DATE;` in the UI and click `Run`. The results appear in the lower window:
- 
+ 
diff --git a/getting-started/services.md b/getting-started/services.md
index c3e93a5f57..1f1c8ce2ae 100644
--- a/getting-started/services.md
+++ b/getting-started/services.md
@@ -5,15 +5,26 @@ products: [cloud]
content_group: Getting started
---
-import Install from "versionContent/_partials/_cloud-installation.mdx";
-import Connect from "versionContent/_partials/_cloud-connect-service.mdx";
+import CloudIntro from "versionContent/_partials/_cloud-intro.mdx";
import ServiceIntro from "versionContent/_partials/_services-intro.mdx";
import ServiceOverview from "versionContent/_partials/_service-overview.mdx";
-import CloudIntro from "versionContent/_partials/_cloud-intro.mdx";
+import StartUsingCloud from "versionContent/_partials/_start-using-cloud.mdx";
+import Install from "versionContent/_partials/_cloud-installation.mdx";
+import CreateService from "versionContent/_partials/_create-service.mdx";
+import Connect from "versionContent/_partials/_cloud-connect-service.mdx";
import WhereNext from "versionContent/_partials/_where-to-next.mdx";
+import InstallAzure from "versionContent/_partials/_cloud-installation-azure.mdx";
+import ServiceIntroAzure from "versionContent/_partials/_services-intro-azure.mdx";
+import ServiceOverviewAzure from "versionContent/_partials/_service-overview-azure.mdx";
+import StartUsingCloudAzure from "versionContent/_partials/_start-using-cloud-azure.mdx";
+
# Create a $SERVICE_LONG
+
+
+
+
## What is a $SERVICE_LONG?
@@ -22,39 +33,49 @@ import WhereNext from "versionContent/_partials/_where-to-next.mdx";
-To start using $CLOUD_LONG for your data:
+
-1. [Create a $ACCOUNT_LONG][create-an-account]: register to get access to $CONSOLE as a centralized point to administer and interact with your data.
-1. [Create a $SERVICE_LONG][create-a-service]: that is, a $PG database instance, powered by [$TIMESCALE_DB][timescaledb], built for production, and extended with cloud features like transparent data tiering to object storage.
-1. [Connect to your $SERVICE_LONG][connect-to-your-service]: to run queries, add and migrate your data from other sources.
+## Create a $ACCOUNT_LONG
-## Create a $SERVICE_LONG
+## Create a $SERVICE_SHORT
Now that you have an active $ACCOUNT_LONG, you create and manage your $SERVICE_SHORTs in $CONSOLE. When you create a $SERVICE_SHORT, you effectively create a blank $PG database with additional $CLOUD_LONG features available under your $PRICING_PLAN. You then add or migrate your data into this database.
-To create a free or standard $SERVICE_SHORT:
+
+
+## Connect to your $SERVICE_SHORT
+
+To run queries and perform other operations, connect to your $SERVICE_SHORT:
+
+
+
+
+
+
-
+
-1. In the [$SERVICE_SHORT creation page][create-service], click `+ New service`.
+
+
+## What is a $SERVICE_LONG?
- Follow the wizard to configure your $SERVICE_SHORT depending on its type.
-
-1. Click `Create service`.
+
- Your $SERVICE_SHORT is constructed and ready to use in a few seconds.
+
-1. Click `Download the config` and store the configuration information you need to connect to this $SERVICE_SHORT in a secure location.
+
- This file contains the passwords and configuration information you need to connect to your $SERVICE_SHORT using the
- $CONSOLE $DATA_MODE, from the command line, or using third-party database administration tools.
+## Create a $ACCOUNT_LONG
-If you choose to go directly to the $SERVICE_SHORT overview, [Connect to your $SERVICE_SHORT][connect-to-your-service]
-shows you how to connect.
+
-
+## Create a $SERVICE_SHORT
+
+Now that you have an active $ACCOUNT_LONG, you create and manage your $SERVICE_SHORTs in $CONSOLE. When you create a $SERVICE_SHORT, you effectively create a blank $PG database with additional $CLOUD_LONG features available under your $PRICING_PLAN. You then add or migrate your data into this database.
+
+
## Connect to your $SERVICE_SHORT
@@ -64,6 +85,9 @@ To run queries and perform other operations, connect to your $SERVICE_SHORT:
+
+
+
[tsc-portal]: https://console.cloud.timescale.com/
[services-how-to]: /use-timescale/:currentVersion:/services/
diff --git a/getting-started/try-key-features-timescale-products.md b/getting-started/try-key-features-timescale-products.md
index 09acb528a0..13151c0b03 100644
--- a/getting-started/try-key-features-timescale-products.md
+++ b/getting-started/try-key-features-timescale-products.md
@@ -211,7 +211,7 @@ For example, yesterday's market data.
90%. This helps you save on storage costs and keeps your queries operating at lightning speed. To see the amount of space
saved, click `Explorer` > `public` > `crypto_ticks`.
- 
+ 
@@ -360,7 +360,7 @@ To set up data tiering:
1. In `Explorer`, click `Storage configuration` > `Tiering storage`, then click `Enable tiered storage`.
- 
+ 
When tiered storage is enabled, you see the amount of data in the tiered object storage.
diff --git a/integrations/aws.md b/integrations/aws.md
index ab828ef7df..13e2f0662a 100644
--- a/integrations/aws.md
+++ b/integrations/aws.md
@@ -8,9 +8,11 @@ keywords: [AWS, integrations]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Amazon Web Services with $CLOUD_LONG
+
[Amazon Web Services (AWS)][aws] is a comprehensive cloud computing platform that provides on-demand infrastructure, storage, databases, AI, analytics, and security services to help businesses build, deploy, and scale applications in the cloud.
This page explains how to integrate your AWS infrastructure with $CLOUD_LONG using [AWS Transit Gateway][aws-transit-gateway].
@@ -21,6 +23,8 @@ This page explains how to integrate your AWS infrastructure with $CLOUD_LONG usi
- Set up [AWS Transit Gateway][gtw-setup].
+
+
## Connect your AWS infrastructure to your $SERVICE_LONGs
To connect to $CLOUD_LONG:
@@ -33,6 +37,11 @@ To connect to $CLOUD_LONG:
You have successfully integrated your AWS infrastructure with $CLOUD_LONG.
+
+
+
+
+
[aws]: https://aws.amazon.com/
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[gtw-setup]: https://docs.aws.amazon.com/vpc/latest/tgw/tgw-getting-started.html
diff --git a/integrations/cloudwatch.md b/integrations/cloudwatch.md
index b8aafa5488..58722a9b32 100644
--- a/integrations/cloudwatch.md
+++ b/integrations/cloudwatch.md
@@ -6,6 +6,7 @@ price_plans: [scale, enterprise]
keywords: [integrate]
---
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import CloudWatchExporter from "versionContent/_partials/_cloudwatch-data-exporter.mdx";
import ManageDataExporter from "versionContent/_partials/_manage-a-data-exporter.mdx";
@@ -24,6 +25,8 @@ This pages explains how to export telemetry data from your $SERVICE_LONG into Cl
- Sign up for [Amazon CloudWatch][cloudwatch-signup].
+
+
## Create a data exporter
A $CLOUD_LONG data exporter sends telemetry data from a $SERVICE_LONG to a third-party monitoring
@@ -33,6 +36,9 @@ tool. You create an exporter on the [project level][projects], in the same AWS r
+
+
+
[projects]: /use-timescale/:currentVersion:/security/members/
[pricing-plan-features]: /about/:currentVersion:/pricing-and-account-management/#features-included-in-each-pricing-plan
[cloudwatch]: https://aws.amazon.com/cloudwatch/
diff --git a/integrations/corporate-data-center.md b/integrations/corporate-data-center.md
index c95fed50be..f097a6f454 100644
--- a/integrations/corporate-data-center.md
+++ b/integrations/corporate-data-center.md
@@ -8,6 +8,7 @@ keywords: [on-premise, integrations]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate your data center with $CLOUD_LONG
@@ -18,6 +19,7 @@ This page explains how to integrate your corporate on-premise infrastructure wit
- Set up [AWS Transit Gateway][gtw-setup].
+
## Connect your on-premise infrastructure to your $SERVICE_LONGs
@@ -33,7 +35,11 @@ To connect to $CLOUD_LONG:
-You have successfully integrated your Microsoft Azure infrastructure with $CLOUD_LONG.
+You have successfully integrated your corporate data center with $CLOUD_LONG.
+
+
+
+
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[gtw-setup]: https://docs.aws.amazon.com/vpc/latest/tgw/tgw-getting-started.html
diff --git a/integrations/datadog.md b/integrations/datadog.md
index ccd4219fc9..005f9c063f 100644
--- a/integrations/datadog.md
+++ b/integrations/datadog.md
@@ -9,6 +9,7 @@ keywords: [integrate]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import DataDogExporter from "versionContent/_partials/_datadog-data-exporter.mdx";
import ManageDataExporter from "versionContent/_partials/_manage-a-data-exporter.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Datadog with $CLOUD_LONG
@@ -36,6 +37,8 @@ This page explains how to:
- Install [Datadog Agent][datadog-agent-install].
+
+
## Monitor $SERVICE_LONG metrics with Datadog
Export telemetry data from your $SERVICE_LONGs with the time-series and analytics capability enabled to
@@ -132,6 +135,9 @@ metrics about your $SERVICE_LONGs.
Metrics for your $SERVICE_LONG are now visible in Datadog. Check the Datadog $PG integration documentation for a
comprehensive list of [metrics][datadog-postgres-metrics] collected.
+
+
+
[datadog]: https://www.datadoghq.com/
[datadog-agent-install]: https://docs.datadoghq.com/getting_started/agent/#installation
[datadog-postgres]: https://docs.datadoghq.com/integrations/postgres/
diff --git a/integrations/find-connection-details.md b/integrations/find-connection-details.md
index b92685f636..eccfbd5f4e 100644
--- a/integrations/find-connection-details.md
+++ b/integrations/find-connection-details.md
@@ -44,12 +44,12 @@ To retrieve the connection details for your $PROJECT_LONG and $SERVICE_LONG:
1. **Retrieve your project ID**:
In [$CONSOLE][console-services], click your project name in the upper left corner, then click `Copy` next to the project ID.
- 
+ 
1. **Retrieve your service ID**:
Click the dots next to the service, then click `Copy` next to the service ID.
- 
+ 
diff --git a/integrations/google-cloud.md b/integrations/google-cloud.md
index 83f7cf095b..a0659da661 100644
--- a/integrations/google-cloud.md
+++ b/integrations/google-cloud.md
@@ -8,6 +8,7 @@ keywords: [Google Cloud, integrations]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Google Cloud with $CLOUD_LONG
@@ -20,6 +21,7 @@ This page explains how to integrate your Google Cloud infrastructure with $CLOUD
- Set up [AWS Transit Gateway][gtw-setup].
+
## Connect your Google Cloud infrastructure to your $SERVICE_LONGs
@@ -37,6 +39,12 @@ To connect to $CLOUD_LONG:
You have successfully integrated your Google Cloud infrastructure with $CLOUD_LONG.
+
+
+
+
+
+
[google-cloud]: https://cloud.google.com/?hl=en
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[gtw-setup]: https://docs.aws.amazon.com/vpc/latest/tgw/tgw-getting-started.html
diff --git a/integrations/microsoft-azure.md b/integrations/microsoft-azure.md
index 0be270d87a..7787d04279 100644
--- a/integrations/microsoft-azure.md
+++ b/integrations/microsoft-azure.md
@@ -8,9 +8,11 @@ keywords: [Azure, integrations]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Microsoft Azure with $CLOUD_LONG
+
[Microsoft Azure][azure] is a cloud computing platform and services suite, offering infrastructure, AI, analytics, security, and developer tools to help businesses build, deploy, and manage applications.
This page explains how to integrate your Microsoft Azure infrastructure with $CLOUD_LONG using [AWS Transit Gateway][aws-transit-gateway].
@@ -20,6 +22,7 @@ This page explains how to integrate your Microsoft Azure infrastructure with $CL
- Set up [AWS Transit Gateway][gtw-setup].
+
## Connect your Microsoft Azure infrastructure to your $SERVICE_LONGs
@@ -37,6 +40,10 @@ To connect to $CLOUD_LONG:
You have successfully integrated your Microsoft Azure infrastructure with $CLOUD_LONG.
+
+
+
+
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[gtw-setup]: https://docs.aws.amazon.com/vpc/latest/tgw/tgw-getting-started.html
[azure]: https://azure.microsoft.com/en-gb/
diff --git a/integrations/prometheus.md b/integrations/prometheus.md
index ae4a61531d..11d85e1080 100644
--- a/integrations/prometheus.md
+++ b/integrations/prometheus.md
@@ -7,7 +7,9 @@ keywords: [integrate]
---
import PrometheusIntegrate from "versionContent/_partials/_prometheus-integrate.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate Prometheus with $CLOUD_LONG
-
\ No newline at end of file
+
+
diff --git a/migrate/livesync-for-kafka.md b/migrate/livesync-for-kafka.md
index de2b713f53..af08ad025a 100644
--- a/migrate/livesync-for-kafka.md
+++ b/migrate/livesync-for-kafka.md
@@ -9,12 +9,13 @@ tags: [stream, connector]
import PrereqCloud from "versionContent/_partials/_prereqs-cloud-only.mdx";
import EarlyAccessNoRelease from "versionContent/_partials/_early_access.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Stream data from Kafka
You use the Kafka source connector in $CLOUD_LONG to stream events from Kafka into your $SERVICE_SHORT. $CLOUD_LONG connects to your Confluent Cloud Kafka cluster and Schema Registry using SASL/SCRAM authentication and service account–based API keys. Only the Avro format is currently supported [with some limitations][limitations].
-This page explains how to connect $CLOUD_LONG to your Confluence Cloud Kafka cluster.
+This page explains how to connect $CLOUD_LONG to your Confluent Cloud Kafka cluster.
: the Kafka source connector is not yet supported for production use.
@@ -25,6 +26,8 @@ This page explains how to connect $CLOUD_LONG to your Confluence Cloud Kafka clu
- [Sign up][confluence-signup] for Confluence Cloud.
- [Create][create-kafka-cluster] a Kafka cluster in Confluence Cloud.
+
+
## Access your Kafka cluster in Confluent Cloud
Take the following steps to prepare your Kafka cluster for connection to $CLOUD_LONG:
diff --git a/migrate/livesync-for-postgresql.md b/migrate/livesync-for-postgresql.md
index 2a4d4c9331..844ecdf767 100644
--- a/migrate/livesync-for-postgresql.md
+++ b/migrate/livesync-for-postgresql.md
@@ -20,7 +20,7 @@ $SERVICE_SHORT, in real time. You run the connector continuously, turning $PG in
$SERVICE_SHORT as a logical replica. This enables you to leverage $CLOUD_LONG’s real-time analytics capabilities on
your replica data.
-
+
The $PG_CONNECTOR in $CLOUD_LONG leverages the well-established $PG logical replication protocol. By relying on this protocol,
$CLOUD_LONG ensures compatibility, familiarity, and a broader knowledge base—making it easier for you to adopt the connector
diff --git a/migrate/livesync-for-s3.md b/migrate/livesync-for-s3.md
index 42406175ce..b5c9e91ae1 100644
--- a/migrate/livesync-for-s3.md
+++ b/migrate/livesync-for-s3.md
@@ -9,12 +9,13 @@ tags: [recovery, logical backup, replication]
import PrereqCloud from "versionContent/_partials/_prereqs-cloud-only.mdx";
import EarlyAccessNoRelease from "versionContent/_partials/_early_access.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Sync data from S3
You use the $S3_CONNECTOR in $CLOUD_LONG to synchronize CSV and Parquet files from an S3 bucket to your $SERVICE_LONG in real time. The connector runs continuously, enabling you to leverage $CLOUD_LONG as your analytics database with data constantly synced from S3. This lets you take full advantage of $CLOUD_LONG's real-time analytics capabilities without having to develop or manage custom ETL solutions between S3 and $CLOUD_LONG.
-
+
You can use the $S3_CONNECTOR to synchronize your existing and new data. Here's what the connector can do:
@@ -63,6 +64,8 @@ The $S3_CONNECTOR continuously imports data from an Amazon S3 bucket into your d
- [Public anonymous user][credentials-public].
+
+
## Limitations
- **File naming**:
@@ -100,7 +103,7 @@ To sync data from your S3 bucket to your $SERVICE_LONG using $CONSOLE:
1. **Connect the source S3 bucket to the target $SERVICE_SHORT**
- 
+ 
1. Click `Connectors` > `Amazon S3`.
1. Click the pencil icon, then set the name for the new connector.
@@ -137,18 +140,18 @@ To sync data from your S3 bucket to your $SERVICE_LONG using $CONSOLE:
1. To view the amount of data replicated, click `Connectors`. The diagram in `Connector data flow` gives you an overview of the connectors you have created, their status, and how much data has been replicated.
- 
+ 
1. To view file import statistics and logs, click `Connectors` > `Source connectors`, then select the name of your connector in the table.
- 
+ 
1. **Manage the connector**
1. To pause the connector, click `Connectors` > `Source connectors`. Open the three-dot menu next to your connector in the table, then click `Pause`.
- 
+ 
1. To edit the connector, click `Connectors` > `Source connectors`. Open the three-dot menu next to your connector in the table, then click `Edit` and scroll down to `Modify your Connector`. You must pause the connector before editing it.
@@ -162,6 +165,8 @@ To sync data from your S3 bucket to your $SERVICE_LONG using $CONSOLE:
And that is it, you are using the $S3_CONNECTOR to synchronize all the data, or specific files, from an S3 bucket to your
$SERVICE_LONG in real time.
+
+
[about-hypertables]: /use-timescale/:currentVersion:/hypertables/
[lives-sync-specify-tables]: /migrate/:currentVersion:/livesync-for-postgresql/#specify-the-tables-to-synchronize
[compression]: /use-timescale/:currentVersion:/compression/about-compression
diff --git a/migrate/upload-file-using-console.md b/migrate/upload-file-using-console.md
index accd788d8e..8fb713b2ba 100644
--- a/migrate/upload-file-using-console.md
+++ b/migrate/upload-file-using-console.md
@@ -8,6 +8,7 @@ keywords: [import]
import ImportPrerequisitesCloudNoConnection from "versionContent/_partials/_prereqs-cloud-no-connection.mdx";
import EarlyAccessGeneral from "versionContent/_partials/_early_access.mdx";
import NotAvailableFreePlan from "versionContent/_partials/_not-available-in-free-plan.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Upload a file into your $SERVICE_SHORT using $CONSOLE_LONG
@@ -25,6 +26,8 @@ $CONSOLE_LONG enables you to drag and drop files to upload from your local machi
+
+
@@ -127,6 +130,8 @@ $CONSOLE_LONG enables you to upload CSV and Parquet files, including archives co
- [IAM Role][credentials-iam].
- [Public anonymous user][credentials-public].
+
+
@@ -205,7 +210,6 @@ To import a Parquet file from an S3 bucket:
-
And that is it, you have imported your data to your $SERVICE_LONG.
[credentials-iam]: https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_for-user.html#roles-creatingrole-user-console
diff --git a/use-timescale/backup-restore.md b/use-timescale/backup-restore.md
index 693c389155..954f49024a 100644
--- a/use-timescale/backup-restore.md
+++ b/use-timescale/backup-restore.md
@@ -7,8 +7,13 @@ tags: [recovery, failures]
---
import CLIFORKS from "versionContent/_partials/_devops-cli-service-forks.mdx";
+import PitrIntro from "versionContent/_partials/_pitr-intro.mdx";
-# Back up and recover $SERVICE_SHORTs
+# Back up and recover your $SERVICE_SHORTs
+
+
+
+
$CLOUD_LONG provides comprehensive backup and recovery solutions to protect your data, including automatic daily backups,
cross-region protection, and point-in-time recovery.
@@ -22,9 +27,9 @@ $CLOUD_LONG automatically creates one full backup every week, and incremental ba
your $SERVICE_SHORT. Additionally, all [Write-Ahead Log (WAL)][wal] files are retained back to the oldest full backup.
This means that you always have a full backup available for the current and previous week:
-
+
-On [$SCALE and $PERFORMANCE][pricing-and-account-management] $PRICING_PLANs, you can check the list of backups for the previous 14 days in $CONSOLE_LONG. To do so, select your $SERVICE_SHORT, then click `Operations` > `Backup and restore` > `Backup history`.
+On [$SCALE and $PERFORMANCE][pricing-and-account-management] $PRICING_PLANs, you can check the list of backups for the previous 14 days in $CONSOLE_LONG. To do so, select your $SERVICE_SHORT, then click `Operations` > `Backup and restore` > `Backup history`.
In the event of a storage failure, a $SERVICE_SHORT automatically recovers from a backup
to the point of failure. If the whole availability zone goes down, your $SERVICE_LONGs are recovered in a different zone. In the event of a user error, you can [create a point-in-time recovery fork][create-fork].
@@ -43,7 +48,7 @@ You enable cross-region backup when you create a $SERVICE_SHORT, or configure it
1. In `Cross-region backup`, select the region in the dropdown and click `Enable backup`.
- 
+ 
You can now see the backup, its region, and creation date in a list.
@@ -57,7 +62,7 @@ You can have one cross-region backup per $SERVICE_SHORT. To change the region of
1. Click the trash icon next to the existing backup to disable it.
- 
+ 
1. Create a new backup in a different region.
@@ -65,26 +70,7 @@ You can have one cross-region backup per $SERVICE_SHORT. To change the region of
## Create a point-in-time recovery fork
-
-
-To recover your $SERVICE_SHORT from a destructive or unwanted action, create a point-in-time recovery fork. You can
-recover a $SERVICE_SHORT to any point within the period [defined by your pricing plan][pricing-and-account-management].
-The provision time for the recovery fork is typically less than twenty minutes, but can take longer depending on the
-amount of WAL to be replayed. The original $SERVICE_SHORT stays untouched to avoid losing data created since the time
-of recovery.
-
-All tiered data remains recoverable during the PITR period. When restoring to any point-in-time recovery fork, your
-$SERVICE_SHORT contains all data that existed at that moment - whether it was stored in high-performance or low-cost
-storage.
-
-When you restore a recovery fork:
-- Data restored from a PITR point is placed into high-performance storage
-- The tiered data, as of that point in time, remains in tiered storage
-
-
-
-To avoid paying for compute for the recovery fork and the original $SERVICE_SHORT, pause the original to only pay
-storage costs.
+
You initiate a point-in-time recovery from a same-region or cross-region backup in $CONSOLE_LONG:
@@ -127,11 +113,67 @@ You initiate a point-in-time recovery from a same-region or cross-region backup
+## Create a service fork
+
+
+
+
+
+
+
+$CLOUD_LONG provides comprehensive backup and recovery solutions to protect your data, including automatic daily backups and point-in-time recovery.
+
+## Automatic backups
+
+$CLOUD_LONG automatically handles backup for your $SERVICE_LONGs using the `pgBackRest` tool. You don't need to perform
+backups manually.
+
+$CLOUD_LONG automatically creates one full backup every week, and incremental backups every day in the same region as
+your $SERVICE_SHORT. Additionally, all [Write-Ahead Log (WAL)][wal] files are retained back to the oldest full backup.
+This means that you always have a full backup available for the current and previous week:
+
+
+
+On [$SCALE and $PERFORMANCE][pricing-and-account-management] $PRICING_PLANs, you can check the list of backups for the previous 14 days in $CONSOLE_LONG. To do so, select your $SERVICE_SHORT, then click `Operations` > `Backup and restore` > `Backup history`.
+
+In the event of a storage failure, a $SERVICE_SHORT automatically recovers from a backup
+to the point of failure. If the whole availability zone goes down, your $SERVICE_LONGs are recovered in a different zone. In the event of a user error, you can [create a point-in-time recovery fork][create-fork].
+
+## Create a point-in-time recovery fork
+
+
+
+You initiate a point-in-time recovery in $CONSOLE_LONG:
+
+
+
+1. In [$CONSOLE][console], from the `Services` list, ensure the $SERVICE_SHORT
+ you want to recover has a status of `Running` or `Paused`.
+1. Navigate to `Operations` > `Backup & restore` and click `Create recovery fork`.
+1. Select the recovery point, ensuring the correct time zone (UTC offset).
+1. Configure the fork.
+
+ 
+
+ You can configure the compute resources, add an HA replica, tag your fork, and
+ add a connection pooler. Best practice is to match
+ the same configuration you had at the point you want to recover to.
+1. Confirm by clicking `Create recovery fork`.
+
+ A fork of the $SERVICE_SHORT is created. The recovered $SERVICE_SHORT shows in `Services` with a label specifying which $SERVICE_SHORT it has been forked from.
+1. Update the connection strings in your app to use the fork.
+
+
## Create a service fork
+
+
+
+
+
[console]: https://console.cloud.timescale.com/dashboard/services
[ha-replicas]: /about/use-timescale/:currentVersion:/ha-replicas/
diff --git a/use-timescale/configuration/customize-configuration.md b/use-timescale/configuration/customize-configuration.md
index 5b87d05af3..b525426a85 100644
--- a/use-timescale/configuration/customize-configuration.md
+++ b/use-timescale/configuration/customize-configuration.md
@@ -32,7 +32,7 @@ To modify configuration parameters, first select the $SERVICE_SHORT that you wan
modify. This displays the $SERVICE_SHORT details, with these tabs across the top:
`Overview`, `Actions`, `Explorer`, `Monitoring`, `Connections`, `SQL Editor`, `Operations`, and `AI`. Select `Operations`, then `Database parameters`.
-
+
### Modify basic parameters
diff --git a/use-timescale/data-tiering/about-data-tiering.md b/use-timescale/data-tiering/about-data-tiering.md
index 9a2f71300b..a6fc0791de 100644
--- a/use-timescale/data-tiering/about-data-tiering.md
+++ b/use-timescale/data-tiering/about-data-tiering.md
@@ -10,6 +10,7 @@ cloud_ui:
---
import TieredStorageBilling from "versionContent/_partials/_tiered-storage-billing.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# About storage tiers
@@ -34,6 +35,8 @@ $CLOUD_LONG high-performance storage comes in the following types:
Once you [enable tiered storage][manage-tiering], you can start moving rarely used data to the object tier. The object tier is based on AWS S3 and stores your data in the [Apache Parquet][parquet] format. Within a Parquet file, a set of rows is grouped together to form a row group. Within a row group, values for a single column across multiple rows are stored together. The original size of the data in your $SERVICE_SHORT, compressed or uncompressed, does not correspond directly to its size in S3. A compressed hypertable may even take more space in S3 than it does in $CLOUD_LONG.
+
+
Apache Parquet allows for more efficient scans across longer time periods, and $CLOUD_LONG uses other metadata and query optimizations to reduce the amount of data that needs to be fetched to satisfy a query, such as:
- **Chunk skipping**: exclude the chunks that fall outside the query time window.
@@ -122,6 +125,7 @@ The low-cost storage tier comes with the following limitations:
partitioned on more than one dimension. Make sure your hypertables are
partitioned on time only, before you enable tiered storage.
+
[blog-data-tiering]: https://www.timescale.com/blog/expanding-the-boundaries-of-postgresql-announcing-a-bottomless-consumption-based-object-storage-layer-built-on-amazon-s3/
[querying-tiered-data]: /use-timescale/:currentVersion:/data-tiering/querying-tiered-data/
[parquet]: https://parquet.apache.org/
diff --git a/use-timescale/data-tiering/enabling-data-tiering.md b/use-timescale/data-tiering/enabling-data-tiering.md
index 310a702a70..ceb62e3b87 100644
--- a/use-timescale/data-tiering/enabling-data-tiering.md
+++ b/use-timescale/data-tiering/enabling-data-tiering.md
@@ -11,6 +11,7 @@ cloud_ui:
---
import TieredStorageBilling from "versionContent/_partials/_tiered-storage-billing.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Manage storage and tiering
@@ -44,7 +45,7 @@ This storage type gives you up to 16 TB of storage and is available under [all $
- Under the [$PERFORMANCE $PRICING_PLAN][pricing-plans], IOPS is set to 3,000 - 5,000 autoscale and cannot be changed.
- Under the [$SCALE and $ENTERPRISE $PRICING_PLANs][pricing-plans], IOPS is set to 5,000 - 8,000 autoscale and can be upgraded to 16,000 IOPS.
- 
+ 
1. **Click `Apply`**
@@ -54,14 +55,18 @@ This storage type gives you up to 16 TB of storage and is available under [all $
-This storage type gives you up to 64 TB and 32,000 IOPS, and is available under the [$ENTERPRISE $PRICING_PLAN][pricing-plans]. To get enhanced storage:
+This storage type gives you up to 64 TB and 32,000 IOPS, and is available under the [$ENTERPRISE $PRICING_PLAN][pricing-plans].
+
+
+
+To get enhanced storage:
1. **In [$CONSOLE][console], select your $SERVICE_SHORT, then click `Operations` > `Compute and storage`**
1. **Select `Enhanced` in the `Storage type` dropdown**
- 
+ 
@@ -73,7 +78,7 @@ This storage type gives you up to 64 TB and 32,000 IOPS, and is available under
Select between 8,000, 16,000, 24,000, and 32,0000 IOPS. The value that you can apply depends on the number of CPUs in your $SERVICE_SHORT. $CONSOLE notifies you if your selected IOPS requires increasing the number of CPUs. To increase IOPS to 64,000, click `Contact us` and we will be in touch to confirm the details.
- 
+ 
1. **Click `Apply`**
@@ -87,6 +92,8 @@ You change from enhanced storage to standard in the same way. If you are using o
You enable the low-cost object storage tier in $CONSOLE and then tier the data with policies or manually.
+
+
### Enable tiered storage
You enable tiered storage from the `Overview` tab in $CONSOLE.
@@ -97,7 +104,7 @@ You enable tiered storage from the `Overview` tab in $CONSOLE.
1. **In `Explorer`, click `Storage configuration` > `Tiering storage`, then click `Enable tiered storage`**
- 
+ 
Once enabled, you can proceed to [tier data manually][manual-tier] or [set up tiering policies][tiering-policies]. When tiered storage is enabled, you see the amount of data in the tiered object storage.
@@ -280,6 +287,7 @@ If you no longer want to use tiered storage for a particular hypertable, drop th
+
[data-retention]: /use-timescale/:currentVersion:/data-retention/
[console]: https://console.cloud.timescale.com/dashboard/services
[hypertable]: /use-timescale/:currentVersion:/hypertables/
diff --git a/use-timescale/data-tiering/index.md b/use-timescale/data-tiering/index.md
index fac5c509c9..046e307f69 100644
--- a/use-timescale/data-tiering/index.md
+++ b/use-timescale/data-tiering/index.md
@@ -1,6 +1,6 @@
---
-title: Storage in Tiger
-excerpt: Save on storage costs by tiering older data to a low-cost bottomless object storage tier. Tiger Cloud tiered storage makes sure you cut costs while having data available for analytical queries
+title: Storage on Tiger Cloud
+excerpt: Save on storage costs by tiering older data to a low-cost bottomless object storage tier. Tiger tiered storage makes sure you cut costs while having data available for analytical queries
products: [cloud]
keywords: [tiered storage]
tags: [storage, data management]
@@ -8,6 +8,10 @@ tags: [storage, data management]
# Storage
+
+
+
+
Tiered storage is a [hierarchical storage management architecture][hierarchical-storage] for
[real-time analytics][create-service] $SERVICE_SHORTs you create in [$CLOUD_LONG](https://console.cloud.timescale.com/).
@@ -42,6 +46,19 @@ In this section, you:
* [Learn about replicas and forks with tiered data][replicas-and-forks]: understand how tiered storage works
with forks and replicas of your $SERVICE_SHORT.
+
+
+
+
+$CLOUD_LONG stores your data in high-performance storage optimized for frequent querying. Based on [AWS EBS gp3][aws-gp3], the high-performance storage provides you with up to 16 TB and 16,000 IOPS. Its [$HYPERCORE row-columnar storage engine][hypercore], designed specifically for real-time analytics, enables you to compress your data by up to 98%, while improving performance.
+
+Coupled with other optimizations, $CLOUD_LONG high-performance storage makes sure your data is always accessible and your queries run at lightning speed.
+
+
+
+
+
+
[about-data-tiering]: /use-timescale/:currentVersion:/data-tiering/about-data-tiering/
[enabling-data-tiering]: /use-timescale/:currentVersion:/data-tiering/enabling-data-tiering/
[replicas-and-forks]: /use-timescale/:currentVersion:/data-tiering/tiered-data-replicas-forks/
@@ -49,4 +66,6 @@ In this section, you:
[querying-tiered-data]: /use-timescale/:currentVersion:/data-tiering/querying-tiered-data/
[add-retention-policies]: /api/:currentVersion:/continuous-aggregates/add_policies/
[create-service]: /getting-started/:currentVersion:/services/
-[hierarchical-storage]: https://en.wikipedia.org/wiki/Hierarchical_storage_management
\ No newline at end of file
+[hierarchical-storage]: https://en.wikipedia.org/wiki/Hierarchical_storage_management
+[hypercore]: /use-timescale/:currentVersion:/hypercore
+[aws-gp3]: https://docs.aws.amazon.com/ebs/latest/userguide/general-purpose.html
\ No newline at end of file
diff --git a/use-timescale/data-tiering/querying-tiered-data.md b/use-timescale/data-tiering/querying-tiered-data.md
index 9b19ed5686..a33a961a6d 100644
--- a/use-timescale/data-tiering/querying-tiered-data.md
+++ b/use-timescale/data-tiering/querying-tiered-data.md
@@ -7,6 +7,8 @@ keywords: [ tiered storage, tiering ]
tags: [ storage, data management ]
---
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
+
# Querying tiered data
Once rarely used data is tiered and migrated to the object storage tier, it can still be queried
@@ -24,6 +26,8 @@ Your hypertable is spread across the tiers, so queries and `JOIN`s work and fetc
By default, tiered data is not accessed by queries. Querying tiered data may slow down query performance
as the data is not stored locally on the high-performance storage tier. See [Performance considerations](#performance-considerations).
+
+
## Enable querying tiered data for a single query
@@ -186,3 +190,5 @@ Queries over tiered data are expected to be slower than over local data. However
* Text and non-native types (JSON, JSONB, GIS) filtering is slower when querying tiered data.
+
+
diff --git a/use-timescale/data-tiering/tiered-data-replicas-forks.md b/use-timescale/data-tiering/tiered-data-replicas-forks.md
index 645ea13a6d..d1b23af3b7 100644
--- a/use-timescale/data-tiering/tiered-data-replicas-forks.md
+++ b/use-timescale/data-tiering/tiered-data-replicas-forks.md
@@ -7,7 +7,9 @@ keywords: [tiered storage]
tags: [storage, data management]
---
-# How tiered data works on replicas and forks
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
+
+# How tiered data works on replicas and forks
There is one more thing that makes Tiered Storage even more amazing: when you keep data in the low-cost object storage tier,
you pay for this data only once, regardless of whether you have a [high-availability replica][ha-replica]
@@ -19,6 +21,8 @@ When creating one (or more) forks, you won't be billed for data shared with the
If you decide to tier more data that's not in the primary, you will pay to store it in the low-cost tier,
but you will still see substantial savings by moving that data from the high-performance tier of the fork to the cheaper object storage tier.
+
+
## How this works behind the scenes
Once you tier data to the low-cost object storage tier, we keep a reference to that data on your Database's catalog.
@@ -68,6 +72,7 @@ In the case of such a restore, new references are added to the deleted tiered ch
Once 14 days pass after soft deleting the data,that is the number of references to the tiered data drop to 0, we hard delete the tiered data.
+
[ha-replica]: /use-timescale/:currentVersion:/ha-replicas/high-availability/
[read-replica]: /use-timescale/:currentVersion:/ha-replicas/read-scaling/#read-replicas
[operations-forking]: /use-timescale/:currentVersion:/services/service-management/#fork-a-service
diff --git a/use-timescale/ha-replicas/read-scaling.md b/use-timescale/ha-replicas/read-scaling.md
index b9b9f6acf2..e9447a9569 100644
--- a/use-timescale/ha-replicas/read-scaling.md
+++ b/use-timescale/ha-replicas/read-scaling.md
@@ -78,7 +78,7 @@ To change the compute and storage configuration of your $READ_REPLICA set:
1. **In [$CONSOLE][timescale-console-services], expand and click the $READ_REPLICA set under your primary $SERVICE_SHORT**
- 
+ 
1. **Click `Operations` > `Compute and storage`**
@@ -102,7 +102,7 @@ is measured in bytes, against the current state of the primary instance. To chec
You see a list of configured $READ_REPLICA sets for this $SERVICE_SHORT, including their status and lag:
- 
+ 
1. **Configure the allowable lag**
diff --git a/use-timescale/metrics-logging/aws-cloudwatch.md b/use-timescale/metrics-logging/aws-cloudwatch.md
index 21167975c7..a5ee21f90a 100644
--- a/use-timescale/metrics-logging/aws-cloudwatch.md
+++ b/use-timescale/metrics-logging/aws-cloudwatch.md
@@ -10,6 +10,7 @@ tags: [telemetry, monitor]
import ManageDataExporter from "versionContent/_partials/_manage-a-data-exporter.mdx";
import PrereqsCloud from "versionContent/_partials/_prereqs-cloud-no-connection.mdx";
import CloudWatchExporter from "versionContent/_partials/_cloudwatch-data-exporter.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Export telemetry data to AWS Cloudwatch
@@ -22,6 +23,8 @@ This page shows you how to create an Amazon CloudWatch exporter in $CONSOLE, and
+
+
## Create a data exporter
$CLOUD_LONG data exporters send telemetry data from a $SERVICE_LONG to a third-party monitoring
@@ -35,6 +38,8 @@ This section shows you how to attach, monitor, edit, and delete a data exporter.
+
+
[cloudwatch]: https://aws.amazon.com/cloudwatch/
[cloudwatch-docs]: https://docs.aws.amazon.com/cloudwatch/index.html
[console-integrations]: https://console.cloud.timescale.com/dashboard/integrations
diff --git a/use-timescale/metrics-logging/datadog.md b/use-timescale/metrics-logging/datadog.md
index 48ce55f8a9..a1dcbb4cc3 100644
--- a/use-timescale/metrics-logging/datadog.md
+++ b/use-timescale/metrics-logging/datadog.md
@@ -10,6 +10,7 @@ tags: [telemetry, monitor]
import DataDogExporter from "versionContent/_partials/_datadog-data-exporter.mdx";
import PrereqsCloud from "versionContent/_partials/_prereqs-cloud-no-connection.mdx";
import ManageDataExporter from "versionContent/_partials/_manage-a-data-exporter.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Export telemetry data to Datadog
@@ -21,6 +22,8 @@ This page shows you how to create a Datadog exporter in $CONSOLE, and manage the
+
+
## Create a data exporter
$CLOUD_LONG data exporters send telemetry data from a $SERVICE_LONG to third-party monitoring
@@ -34,6 +37,8 @@ This section shows you how to attach, monitor, edit, and delete a data exporter.
+
+
[datadog]: https://www.datadoghq.com
[datadog-api-key]: https://docs.datadoghq.com/account_management/api-app-keys/#add-an-api-key-or-client-token
[datadog-docs]: https://docs.datadoghq.com/
diff --git a/use-timescale/metrics-logging/index.md b/use-timescale/metrics-logging/index.md
index 47000ace7d..4d6e9147be 100644
--- a/use-timescale/metrics-logging/index.md
+++ b/use-timescale/metrics-logging/index.md
@@ -19,6 +19,7 @@ Find metrics and logs for your $SERVICE_SHORTs in $CONSOLE, or integrate with th
* Export metrics to [Amazon Cloudwatch][cloudwatch].
* Export metrics to [Prometheus][prometheus].
+
[prometheus]: /use-timescale/:currentVersion:/metrics-logging/metrics-to-prometheus/
[datadog]: /use-timescale/:currentVersion:/metrics-logging/datadog/
[cloudwatch]: /use-timescale/:currentVersion:/metrics-logging/aws-cloudwatch/
diff --git a/use-timescale/metrics-logging/metrics-to-prometheus.md b/use-timescale/metrics-logging/metrics-to-prometheus.md
index df2e3c2a6d..6bfbb8aa52 100644
--- a/use-timescale/metrics-logging/metrics-to-prometheus.md
+++ b/use-timescale/metrics-logging/metrics-to-prometheus.md
@@ -15,4 +15,4 @@ import PrometheusIntegrate from "versionContent/_partials/_prometheus-integrate.
# Export metrics to Prometheus
-
\ No newline at end of file
+
diff --git a/use-timescale/metrics-logging/monitoring.md b/use-timescale/metrics-logging/monitoring.md
index 26aa5205da..277784dde0 100644
--- a/use-timescale/metrics-logging/monitoring.md
+++ b/use-timescale/metrics-logging/monitoring.md
@@ -29,7 +29,7 @@ This pages explains what specific data you get at each point.
$CLOUD_LONG shows you CPU, memory, and storage metrics for up to 30 previous days and with down to 10-second granularity.
To access metrics, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Metrics`:
-
+
The following metrics are represented by graphs:
@@ -95,7 +95,7 @@ $CLOUD_LONG shows you detailed logs for your $SERVICE_SHORT, which you can filte
To access logs, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Logs`:
-
+
## Insights
@@ -103,7 +103,7 @@ Insights help you get a comprehensive understanding of how your queries perform
To view insights, select your $SERVICE_SHORT, then click `Monitoring` > `Insights`. Search or filter queries by type, maximum execution time, and time frame.
-
+
Insights include `Metrics`, `Current lock contention`, and `Queries`.
@@ -138,7 +138,7 @@ query. Check out the last update value at the top of the query table to identify
Click a query in the list to see the drill-down view. This view not only helps you identify spikes and unexpected behaviors, but also offers information to optimize your query.
-
+
This view includes the following graphs:
@@ -157,11 +157,11 @@ $CLOUD_LONG summarizes all [$JOBs][jobs] set up for your $SERVICE_SHORT along wi
1. To view $JOBs, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Jobs`:
- 
+ 
1. Click a $JOB ID in the list to view its config and run history:
- 
+ 
1. Click the pencil icon to edit the $JOB config:
@@ -175,7 +175,7 @@ $CLOUD_LONG lists current and past connections to your $SERVICE_SHORT. This incl
To view connections, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Connections`. Expand the query underneath each connection to see the full SQL.
-
+
Click the trash icon next to a connection in the list to terminate it. A lock icon means that a connection cannot be terminated; hover over the icon to see the reason.
@@ -185,7 +185,7 @@ $CLOUD_LONG offers specific tips on configuring your $SERVICE_SHORT. This includ
To view recommendations, select your $SERVICE_SHORT in $CONSOLE, then click `Monitoring` > `Recommendations`:
-
+
## Query-level statistics with `pg_stat_statements`
diff --git a/use-timescale/security/ip-allow-list.md b/use-timescale/security/ip-allow-list.md
index 6a579bdf9b..c7510405fa 100644
--- a/use-timescale/security/ip-allow-list.md
+++ b/use-timescale/security/ip-allow-list.md
@@ -38,7 +38,7 @@ You attach a $SERVICE_SHORT to either one $VPC, or one IP allow list. You cannot
1. **Select a $SERVICE_LONG, then click `Operations` > `Security` > `IP Allow List`**
- 
+ 
1. **Select the list in the drop-down and click `Apply`**
diff --git a/use-timescale/security/transit-gateway.md b/use-timescale/security/transit-gateway.md
index 735488b652..8721a3aece 100644
--- a/use-timescale/security/transit-gateway.md
+++ b/use-timescale/security/transit-gateway.md
@@ -11,11 +11,14 @@ cloud_ui:
---
import TransitGateway from "versionContent/_partials/_transit-gateway.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Securely connect to $CLOUD_LONG using AWS Transit Gateway
[AWS Transit Gateway][aws-transit-gateway] enables you to securely connect to your $CLOUD_LONG from AWS, Google Cloud, Microsoft Azure, or any other cloud or on-premise environment.
+
+
You use AWS Transit Gateway as a traffic controller for your network. Instead of setting up multiple direct connections to different clouds, on-premise data centers, and other AWS services, you connect everything to AWS Transit Gateway. This simplifies your network and makes it easier to manage and scale.
You can then create a peering connection between your $SERVICE_LONGs and AWS Transit Gateway in $CLOUD_LONG. This means that, no matter how big or complex your infrastructure is, you can connect securely to your $SERVICE_LONGs.
@@ -87,7 +90,7 @@ AWS Transit Gateway enables you to connect from almost any environment, this pag
-You can now securely access your $SERVICE_SHORTs in $CLOUD_LONG.
+You can now securely access your $SERVICE_SHORTs in $CLOUD_LONG.
[aws-transit-gateway]: https://aws.amazon.com/transit-gateway/
[pricing-plans]: /about/:currentVersion:/pricing-and-account-management/
diff --git a/use-timescale/security/vpc.md b/use-timescale/security/vpc.md
index edccadb84b..f195b8d3fe 100644
--- a/use-timescale/security/vpc.md
+++ b/use-timescale/security/vpc.md
@@ -11,6 +11,7 @@ cloud_ui:
---
import VpcLimitations from "versionContent/_partials/_vpc-limitations.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Secure your $CLOUD_LONG services with $VPC Peering and AWS PrivateLink
@@ -18,6 +19,8 @@ You use Virtual Private Cloud ($VPC) peering to ensure that your $SERVICE_LONGs
only accessible through your secured AWS infrastructure. This reduces the potential
attack vector surface and improves security.
+
+
The data isolation architecture that ensures a highly secure connection between your apps and
$CLOUD_LONG is:
@@ -216,6 +219,7 @@ Migration takes a few minutes to complete and requires a change to DNS settings
$SERVICE_SHORT. The $SERVICE_SHORT is not accessible during this time. If you receive a DNS error, allow
some time for DNS propagation.
+
[aws-dashboard]: https://console.aws.amazon.com/vpc/home#PeeringConnections:
[aws-security-groups]: https://console.aws.amazon.com/vpcconsole/home#securityGroups:
[console-login]: https://console.cloud.timescale.com/
diff --git a/use-timescale/services/change-resources.md b/use-timescale/services/change-resources.md
index bacac5a2ba..e9763c98e9 100644
--- a/use-timescale/services/change-resources.md
+++ b/use-timescale/services/change-resources.md
@@ -25,7 +25,7 @@ You can change the CPU and memory allocation for your $SERVICE_SHORT at any time
minimal downtime, usually less than a minute. The new resources become available as soon as
the $SERVICE_SHORT restarts. You can change the CPU and memory allocation up or down, as frequently as required.
-
+
Note that:
@@ -73,7 +73,7 @@ memory than is available.
When this happens, an `OOM killer` process shuts down $PG processes using
`SIGKILL` commands until the memory usage falls below the upper limit. Because
-this kills the entire server process, it usually requires a restart.
+this kills the entire server process, it usually requires a restart.
To prevent $SERVICE_SHORT disruption caused by OOM errors, $CLOUD_LONG attempts to
shut down only the query that caused the problem. This means that the
@@ -85,11 +85,11 @@ operate normally.
```yml
2021-09-09 18:15:08 UTC [560567]:TimescaleDB: LOG: server process (PID 2351983) was terminated by signal 9: Killed
```
-
- Wait for the $SERVICE_SHORT to come back online before reconnecting.
-* $CLOUD_LONG shuts the client connection only
-
+ Wait for the $SERVICE_SHORT to come back online before reconnecting.
+
+* $CLOUD_LONG shuts the client connection only
+
If $CLOUD_LONG successfully guards the $SERVICE_SHORT against the OOM killer, it shuts
down only the client connection that was using too much memory. This prevents
the entire $SERVICE_SHORT from shutting down, so you can reconnect immediately. The error log looks like this:
diff --git a/use-timescale/services/service-explorer.md b/use-timescale/services/service-explorer.md
index f9527a2e6c..f0cbfd2f17 100644
--- a/use-timescale/services/service-explorer.md
+++ b/use-timescale/services/service-explorer.md
@@ -30,7 +30,7 @@ summary of your $SERVICE_SHORT, including all your hypertables and
relational tables. It summarizes your overall compression ratios, and other
policy and continuous aggregate data. And, if you aren't already using key features like continuous aggregates, columnstore compression, or other automation policies and actions, it provides pointers to tutorials and documentation to help you get started.
-
+
## Tables
@@ -43,7 +43,7 @@ ranges, and columnstore compression status.
From this section, you can also set an automated policy to compress chunks into the columnstore. For more information,
see the [hypercore documentation][hypercore].
-
+
For more information about hypertables, see the
@@ -55,7 +55,7 @@ In the `Continuous aggregate` section, you can see all your continuous
aggregates, including top-level information such as their size, whether they are
configured for real-time aggregation, and their refresh periods.
-
+
For more information about continuous aggregates, see the
[continuous aggregates section][caggs].
diff --git a/use-timescale/services/service-overview.md b/use-timescale/services/service-overview.md
index 8f312fca1b..371ed4332b 100644
--- a/use-timescale/services/service-overview.md
+++ b/use-timescale/services/service-overview.md
@@ -9,37 +9,52 @@ cloud_ui:
- [services, :serviceId, overview]
---
import ServiceOverview from "versionContent/_partials/_service-overview.mdx";
+import ServiceOverviewAzure from "versionContent/_partials/_service-overview-azure.mdx";
+import ServiceUsers from "versionContent/_partials/_service-users.mdx";
# About $SERVICE_LONGs
+
+
+
+
When you log into [$CONSOLE][cloud-login], you see the
$PROJECT_SHORT overview. Click a $SERVICE_SHORT to view run-time data and connection information.
Click `Operations` to configure your $SERVICE_SHORT.
-
+
Each $SERVICE_SHORT hosts a single database managed for you by $CLOUD_LONG.
If you need more than one database, [create a new $SERVICE_SHORT][create-service].
## $SERVICE_SHORT_CAP users
-By default, when you create a new $SERVICE_SHORT, a new `tsdbadmin` user is created.
-This is the user that you use to connect to your new $SERVICE_SHORT.
+
+
+
+
+
+
+
-
+When you log into [$CONSOLE][cloud-login], you see the
+$PROJECT_SHORT overview. Click a $SERVICE_SHORT to view run-time data and connection information.
+Click `Operations` to configure your $SERVICE_SHORT.
+
+
-The `tsdbadmin` user is the owner of the database, but is not a superuser. You
-cannot access the `postgres` user. There is no superuser access to $CLOUD_LONG databases.
+Each $SERVICE_SHORT hosts a single database managed for you by $CLOUD_LONG.
+If you need more than one database, [create a new $SERVICE_SHORT][create-service].
+
+## $SERVICE_SHORT_CAP users
-
+
-In your $SERVICE_SHORT, the `tsdbadmin` user can create another user
-with any other role. For a complete list of roles available, see the
-[$PG role attributes documentation][pg-roles-doc].
+
-You cannot create multiple databases in a single $SERVICE_SHORT. If you need data isolation, use schemas or create additional $SERVICE_SHORTs.
+
[cloud-login]: https://console.cloud.timescale.com/
[pg-roles-doc]: https://www.postgresql.org/docs/current/role-attributes.html
diff --git a/use-timescale/tigerlake.md b/use-timescale/tigerlake.md
index 236ba73e12..235c8a9dad 100644
--- a/use-timescale/tigerlake.md
+++ b/use-timescale/tigerlake.md
@@ -8,6 +8,7 @@ keywords: [data lake, lakehouse, s3, iceberg]
import IntegrationPrereqsCloud from "versionContent/_partials/_integration-prereqs-cloud-only.mdx";
import EarlyAccessGeneral from "versionContent/_partials/_early_access.mdx";
+import NotSupportedAzure from "versionContent/_partials/_not-supported-for-azure.mdx";
# Integrate data lakes with $CLOUD_LONG
@@ -29,6 +30,8 @@ Tiger Lake is currently in private beta. Please contact us to request access.
+
+
## Integrate a data lake with your $SERVICE_LONG
To connect a $SERVICE_LONG to your data lake:
@@ -361,6 +364,9 @@ data lake:
* Writing to the same S3 table bucket from multiple services is not supported, bucket-to-service mapping is one-to-one.
* Iceberg snapshots are pruned automatically if the amount exceeds 2500.
+
+
+
[cmc]: https://console.aws.amazon.com/cloudformation/
[aws-athena]: https://aws.amazon.com/athena/
[apache-spark]: https://spark.apache.org/
diff --git a/use-timescale/upgrades.md b/use-timescale/upgrades.md
index 8bafee0e8c..f12e396d0a 100644
--- a/use-timescale/upgrades.md
+++ b/use-timescale/upgrades.md
@@ -211,7 +211,7 @@ To change your maintenance window:
In [$CONSOLE][cloud-login], select the $SERVICE_SHORT you want to manage.
1. **Set your maintenance window**
1. Click `Operations` > `Environment`, then click `Change maintenance window`.
- 
+ 
1. Select the maintence window start time, then click `Apply`.
Maintenance windows can run for up to four hours.