diff --git a/README.md b/README.md
index 74d73c3..788d359 100644
--- a/README.md
+++ b/README.md
@@ -1,197 +1,129 @@
-# seatunnel [](https://travis-ci.org/InterestingLab/seatunnel)
+# seatunnel
-[](https://gitter.im/interestinglab_seatunnel/Lobby?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
-
-seatunnel 是一个`非常易用`,`高性能`、支持`实时流式`和`离线批处理`的`海量数据`处理产品,架构于`Apache Spark` 和 `Apache Flink`之上。
+[](https://github.com/InterestingLab/seatunnel/actions/workflows/backend.yml)
---
+[](README.md)
-### 如果您没时间看下面内容,请直接进入正题:
-
-请点击进入快速入门:https://interestinglab.github.io/seatunnel-docs/#/zh-cn/v1/quick-start
-
-seatunnel 提供可直接执行的软件包,没有必要自行编译源代码,下载地址:https://github.com/InterestingLab/seatunnel/releases
-
-文档地址:https://interestinglab.github.io/seatunnel-docs/
-
-各种线上应用案例,请见: https://interestinglab.github.io/seatunnel-docs/#/zh-cn/v1/case_study/
-
-**如果你遇到任何问题,请联系项目负责人 Gary(微信: `garyelephant`) , RickyHuo(微信: `chodomatte1994`),加微信备注"seatunnel",我们把你拉到`seatunnel & Spark & Flink 交流群`里,并为你提供全程免费服务,你也可以与其他伙伴交流大数据技术。扫码加我,拉你入群:**
-
- -
-想了解seatunnel的设计与实现原理,请查看视频:[https://time.geekbang.org/dailylesson/detail/100028486](https://time.geekbang.org/dailylesson/detail/100028486)
-
+SeaTunnel was formerly named Waterdrop , and renamed SeaTunnel since October 12, 2021.
---
-## 为什么我们需要 seatunnel
-
-Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,同时我们也发现了我们的机会 —— 通过我们的努力让Spark的使用更简单,更高效,并将业界和我们使用Spark的优质经验固化到seatunnel这个产品中,明显减少学习成本,加快分布式数据处理能力在生产环境落地。
-
-除了大大简化分布式数据处理难度外,seatunnel尽所能为您解决可能遇到的问题:
-
-* 数据丢失与重复
-* 任务堆积与延迟
-* 吞吐量低
-* 应用到生产环境周期长
-* 缺少应用运行状态监控
-
-"seatunnel" 的中文是“水滴”,来自中国当代科幻小说作家刘慈欣的《三体》系列,它是三体人制造的宇宙探测器,会反射几乎全部的电磁波,表面绝对光滑,温度处于绝对零度,全部由被强互作用力紧密锁死的质子与中子构成,无坚不摧。在末日之战中,仅一个水滴就摧毁了人类太空武装力量近2千艘战舰。
-
-## seatunnel 使用场景
-
-* 海量数据ETL
-* 海量数据聚合
-* 多源数据处理
-
-## seatunnel 的特性
-
-* 简单易用,灵活配置,无需开发
-* 实时流式处理
-* 离线多源数据分析
-* 高性能
-* 海量数据处理能力
-* 模块化和插件化,易于扩展
-* 支持利用SQL做数据处理和聚合
-* 支持Spark Structured Streaming
-* 支持Spark 2.x
-
-## seatunnel 的工作流程
-
-
-
-
-
-想了解seatunnel的设计与实现原理,请查看视频:[https://time.geekbang.org/dailylesson/detail/100028486](https://time.geekbang.org/dailylesson/detail/100028486)
-
+SeaTunnel was formerly named Waterdrop , and renamed SeaTunnel since October 12, 2021.
---
-## 为什么我们需要 seatunnel
-
-Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,同时我们也发现了我们的机会 —— 通过我们的努力让Spark的使用更简单,更高效,并将业界和我们使用Spark的优质经验固化到seatunnel这个产品中,明显减少学习成本,加快分布式数据处理能力在生产环境落地。
-
-除了大大简化分布式数据处理难度外,seatunnel尽所能为您解决可能遇到的问题:
-
-* 数据丢失与重复
-* 任务堆积与延迟
-* 吞吐量低
-* 应用到生产环境周期长
-* 缺少应用运行状态监控
-
-"seatunnel" 的中文是“水滴”,来自中国当代科幻小说作家刘慈欣的《三体》系列,它是三体人制造的宇宙探测器,会反射几乎全部的电磁波,表面绝对光滑,温度处于绝对零度,全部由被强互作用力紧密锁死的质子与中子构成,无坚不摧。在末日之战中,仅一个水滴就摧毁了人类太空武装力量近2千艘战舰。
-
-## seatunnel 使用场景
-
-* 海量数据ETL
-* 海量数据聚合
-* 多源数据处理
-
-## seatunnel 的特性
-
-* 简单易用,灵活配置,无需开发
-* 实时流式处理
-* 离线多源数据分析
-* 高性能
-* 海量数据处理能力
-* 模块化和插件化,易于扩展
-* 支持利用SQL做数据处理和聚合
-* 支持Spark Structured Streaming
-* 支持Spark 2.x
-
-## seatunnel 的工作流程
-
-
-
-
-  -
-
-
-
-```
- Input[数据源输入] -> Filter[数据处理] -> Output[结果输出]
-```
-
-多个Filter构建了数据处理的Pipeline,满足各种各样的数据处理需求,如果您熟悉SQL,也可以直接通过SQL构建数据处理的Pipeline,简单高效。目前seatunnel支持的[Filter列表](https://interestinglab.github.io/seatunnel-docs/#/zh-cn/v1/configuration/filter-plugin), 仍然在不断扩充中。您也可以开发自己的数据处理插件,整个系统是易于扩展的。
-
-## seatunnel 支持的插件
-
-* Input plugin
-
-Fake, File, Hdfs, Kafka, S3, Socket, 自行开发的Input plugin
-
-* Filter plugin
-
-Add, Checksum, Convert, Date, Drop, Grok, Json, Kv, Lowercase, Remove, Rename, Repartition, Replace, Sample, Split, Sql, Table, Truncate, Uppercase, Uuid, 自行开发的Filter plugin
-
-* Output plugin
-
-Elasticsearch, File, Hdfs, Jdbc, Kafka, Mysql, S3, Stdout, 自行开发的Output plugin
-
-## 环境依赖
-
-1. java运行环境,java >= 8
-
-2. 如果您要在集群环境中运行seatunnel,那么需要以下Spark集群环境的任意一种:
-
-* Spark on Yarn
-* Spark Standalone
-* Spark on Mesos
-
-如果您的数据量较小或者只是做功能验证,也可以仅使用`local`模式启动,无需集群环境,seatunnel支持单机运行。
+SeaTunnel is a very easy-to-use ultra-high-performance distributed data integration platform that supports real-time synchronization of massive data. It can synchronize tens of billions of data stably and efficiently every day, and has been used in the production of nearly 100 companies.
-## 文档
-关于seatunnel的[详细文档](https://interestinglab.github.io/seatunnel-docs/)
+## Why do we need SeaTunnel
-## 社区分享
+SeaTunnel will do its best to solve the problems that may be encountered in the synchronization of massive data:
-* 2018-09-08 Elasticsearch 社区分享 [seatunnel:构建在Spark之上的简单高效数据处理系统](https://elasticsearch.cn/slides/127#page=1)
+- Data loss and duplication
+- Task accumulation and delay
+- Low throughput
+- Long cycle to be applied in the production environment
+- Lack of application running status monitoring
-* 2017-09-22 InterestingLab 内部分享 [seatunnel介绍PPT](http://slides.com/garyelephant/seatunnel/fullscreen?token=GKrQoxJi)
+## SeaTunnel use scenarios
-## 应用案例
+- Mass data synchronization
+- Mass data integration
+- ETL with massive data
+- Mass data aggregation
+- Multi-source data processing
-* [微博](https://weibo.com), 增值业务部数据平台
+## Features of SeaTunnel
- +- Easy to use, flexible configuration, low code development
+- Real-time streaming
+- Offline multi-source data analysis
+- High-performance, massive data processing capabilities
+- Modular and plug-in mechanism, easy to extend
+- Support data processing and aggregation by SQL
+- Support Spark structured streaming
+- Support Spark 2.x
-微博某业务有数百个实时流式计算任务使用内部定制版seatunnel,以及其子项目[Guardian](https://github.com/InterestingLab/guardian)做seatunnel On Yarn的任务监控。
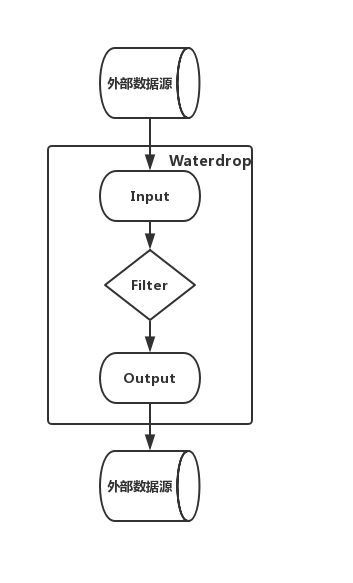
+## Workflow of SeaTunnel
-* [新浪](http://www.sina.com.cn/), 大数据运维分析平台
+ 
-
+- Easy to use, flexible configuration, low code development
+- Real-time streaming
+- Offline multi-source data analysis
+- High-performance, massive data processing capabilities
+- Modular and plug-in mechanism, easy to extend
+- Support data processing and aggregation by SQL
+- Support Spark structured streaming
+- Support Spark 2.x
-微博某业务有数百个实时流式计算任务使用内部定制版seatunnel,以及其子项目[Guardian](https://github.com/InterestingLab/guardian)做seatunnel On Yarn的任务监控。
+## Workflow of SeaTunnel
-* [新浪](http://www.sina.com.cn/), 大数据运维分析平台
+ 
- +Input[Data Source Input] -> Filter[Data Processing] -> Output[Result Output]
-新浪运维数据分析平台使用seatunnel为新浪新闻,CDN等服务做运维大数据的实时和离线分析,并写入Clickhouse。
+The data processing pipeline is constituted by multiple filters to meet a variety of data processing needs. If you are accustomed to SQL, you can also directly construct a data processing pipeline by SQL, which is simple and efficient. Currently, the filter list supported by SeaTunnel is still being expanded. Furthermore, you can develop your own data processing plug-in, because the whole system is easy to expand.
-* [字节跳动](https://bytedance.com/zh),广告数据平台
+## Plugins supported by SeaTunnel
-
+Input[Data Source Input] -> Filter[Data Processing] -> Output[Result Output]
-新浪运维数据分析平台使用seatunnel为新浪新闻,CDN等服务做运维大数据的实时和离线分析,并写入Clickhouse。
+The data processing pipeline is constituted by multiple filters to meet a variety of data processing needs. If you are accustomed to SQL, you can also directly construct a data processing pipeline by SQL, which is simple and efficient. Currently, the filter list supported by SeaTunnel is still being expanded. Furthermore, you can develop your own data processing plug-in, because the whole system is easy to expand.
-* [字节跳动](https://bytedance.com/zh),广告数据平台
+## Plugins supported by SeaTunnel
- +- Input plugin
+Fake, File, Hdfs, Kafka, S3, Socket, self-developed Input plugin
-字节跳动使用seatunnel实现了多源数据的关联分析(如Hive和ES的数据源关联查询分析),大大简化了不同数据源之间的分析对比工作,并且节省了大量的Spark程序的学习和开发时间。
+- Filter plugin
+Add, Checksum, Convert, Date, Drop, Grok, Json, Kv, Lowercase, Remove, Rename, Repartition, Replace, Sample, Split, Sql, Table, Truncate, Uppercase, Uuid, Self-developed Filter plugin
-* [搜狗](http://agent.e.sogou.com/),搜狗奇点系统
+- Output plugin
+Elasticsearch, File, Hdfs, Jdbc, Kafka, Mysql, S3, Stdout, self-developed Output plugin
-
+- Input plugin
+Fake, File, Hdfs, Kafka, S3, Socket, self-developed Input plugin
-字节跳动使用seatunnel实现了多源数据的关联分析(如Hive和ES的数据源关联查询分析),大大简化了不同数据源之间的分析对比工作,并且节省了大量的Spark程序的学习和开发时间。
+- Filter plugin
+Add, Checksum, Convert, Date, Drop, Grok, Json, Kv, Lowercase, Remove, Rename, Repartition, Replace, Sample, Split, Sql, Table, Truncate, Uppercase, Uuid, Self-developed Filter plugin
-* [搜狗](http://agent.e.sogou.com/),搜狗奇点系统
+- Output plugin
+Elasticsearch, File, Hdfs, Jdbc, Kafka, Mysql, S3, Stdout, self-developed Output plugin
- +## Environmental dependency
-搜狗奇点系统使用 seatunnel 作为 etl 工具, 帮助建立实时数仓体系
+1. java runtime environment, java >= 8
-* [趣头条](https://www.qutoutiao.net/),趣头条数据中心
+2. If you want to run SeaTunnel in a cluster environment, any of the following Spark cluster environments is usable:
-
+## Environmental dependency
-搜狗奇点系统使用 seatunnel 作为 etl 工具, 帮助建立实时数仓体系
+1. java runtime environment, java >= 8
-* [趣头条](https://www.qutoutiao.net/),趣头条数据中心
+2. If you want to run SeaTunnel in a cluster environment, any of the following Spark cluster environments is usable:
- +- Spark on Yarn
+- Spark Standalone
-趣头条数据中心,使用seatunnel支撑mysql to hive的离线etl任务、实时hive to clickhouse的backfill技术支撑,很好的cover离线、实时大部分任务场景。
+If the data volume is small, or the goal is merely for functional verification, you can also start in local mode without a cluster environment, because SeaTunnel supports standalone operation. Note: SeaTunnel 2.0 supports running on Spark and Flink.
-* [一下科技](https://www.yixia.com/), 一直播数据平台
+## Downloads
-
+- Spark on Yarn
+- Spark Standalone
-趣头条数据中心,使用seatunnel支撑mysql to hive的离线etl任务、实时hive to clickhouse的backfill技术支撑,很好的cover离线、实时大部分任务场景。
+If the data volume is small, or the goal is merely for functional verification, you can also start in local mode without a cluster environment, because SeaTunnel supports standalone operation. Note: SeaTunnel 2.0 supports running on Spark and Flink.
-* [一下科技](https://www.yixia.com/), 一直播数据平台
+## Downloads
- +Download address for run-directly software package :https://github.com/InterestingLab/SeaTunnel/releases
-* 永辉超市子公司-永辉云创,会员电商数据分析平台
+## Quick start
-
+Download address for run-directly software package :https://github.com/InterestingLab/SeaTunnel/releases
-* 永辉超市子公司-永辉云创,会员电商数据分析平台
+## Quick start
- +Quick start: https://interestinglab.github.io/seatunnel-docs/#/zh-cn/v1/quick-start
-seatunnel 为永辉云创旗下新零售品牌永辉生活提供电商用户行为数据实时流式与离线SQL计算。
+Detailed documentation on SeaTunnel:https://interestinglab.github.io/seatunnel-docs/#/
-* 水滴筹, 数据平台
+## Application practice cases
-
+Quick start: https://interestinglab.github.io/seatunnel-docs/#/zh-cn/v1/quick-start
-seatunnel 为永辉云创旗下新零售品牌永辉生活提供电商用户行为数据实时流式与离线SQL计算。
+Detailed documentation on SeaTunnel:https://interestinglab.github.io/seatunnel-docs/#/
-* 水滴筹, 数据平台
+## Application practice cases
- +- Weibo, Value-added Business Department Data Platform
-水滴筹在Yarn上使用seatunnel做实时流式以及定时的离线批处理,每天处理3~4T的数据量,最终将数据写入Clickhouse。
+Weibo business uses an internal customized version of SeaTunnel and its sub-project Guardian for SeaTunnel On Yarn task monitoring for hundreds of real-time streaming computing tasks.
-* 浙江乐控信息科技有限公司
+- Sina, Big Data Operation Analysis Platform
-
+- Weibo, Value-added Business Department Data Platform
-水滴筹在Yarn上使用seatunnel做实时流式以及定时的离线批处理,每天处理3~4T的数据量,最终将数据写入Clickhouse。
+Weibo business uses an internal customized version of SeaTunnel and its sub-project Guardian for SeaTunnel On Yarn task monitoring for hundreds of real-time streaming computing tasks.
-* 浙江乐控信息科技有限公司
+- Sina, Big Data Operation Analysis Platform
- +Sina Data Operation Analysis Platform uses SeaTunnel to perform real-time and offline analysis of data operation and maintenance for Sina News, CDN and other services, and write it into Clickhouse.
-Watedrop 为浙江乐控信息科技有限公司旗下乐控智能提供物联网交互数据实时流sql分析(Structured Streaming 引擎)和离线数据分析。每天处理的数据量8千万到一亿条数据 最终数据落地到kafka和mysql数据库。
+- Sogou, Sogou Qiqian System
-* [上海分蛋信息科技](https://91fd.com),大数据数据分析平台
+Sogou Qiqian System takes SeaTunnel as an ETL tool to help establish a real-time data warehouse system.
-
+Sina Data Operation Analysis Platform uses SeaTunnel to perform real-time and offline analysis of data operation and maintenance for Sina News, CDN and other services, and write it into Clickhouse.
-Watedrop 为浙江乐控信息科技有限公司旗下乐控智能提供物联网交互数据实时流sql分析(Structured Streaming 引擎)和离线数据分析。每天处理的数据量8千万到一亿条数据 最终数据落地到kafka和mysql数据库。
+- Sogou, Sogou Qiqian System
-* [上海分蛋信息科技](https://91fd.com),大数据数据分析平台
+Sogou Qiqian System takes SeaTunnel as an ETL tool to help establish a real-time data warehouse system.
- +- Qutoutiao, Qutoutiao Data Center
-分蛋科技使用seatunnel做数据仓库实时同步,近百个Pipeline同步处理;数据流实时统计,数据平台指标离线计算。
+Qutoutiao Data Center uses SeaTunnel to support mysql to hive offline ETL tasks, real-time hive to clickhouse backfill technical support, and well covers most offline and real-time tasks needs.
-* 其他公司 ... 期待您的加入,请联系微信: garyelephant
+- Yixia Technology, Yizhibo Data Platform
-## 项目Star增长趋势
+- Yonghui Superstores Founders' Alliance-Yonghui Yunchuang Technology, Member E-commerce Data Analysis Platform
-```
-seatunnel已进入高速成长期,如果你支持此项目,请点Star.
-```
+SeaTunnel provides real-time streaming and offline SQL computing of e-commerce user behavior data for Yonghui Life, a new retail brand of Yonghui Yunchuang Technology.
-[](https://starchart.cc/InterestingLab/seatunnel)
+- Shuidichou, Data Platform
+Shuidichou adopts SeaTunnel to do real-time streaming and regular offline batch processing on Yarn, processing 3~4T data volume average daily, and later writing the data to Clickhouse.
-## 贡献观点和代码
+For more use cases, please refer to: https://interestinglab.github.io/seatunnel-docs/#/zh-cn/case_study/
-提交问题和建议:https://github.com/InterestingLab/seatunnel/issues
+## Contribute ideas and code
-贡献代码:https://github.com/InterestingLab/seatunnel/pulls
+Submit issues and advice: https://github.com/InterestingLab/SeaTunnel/issues
-## 开发者
+Contribute code: https://github.com/InterestingLab/SeaTunnel/pulls
-感谢[所有开发者](https://github.com/InterestingLab/seatunnel/graphs/contributors)
+## Developer
-## 联系项目负责人
+Thanks to all developers https://github.com/InterestingLab/SeaTunnel/graphs/contributors
-Garyelephant : garygaowork@gmail.com, 微信: garyelephant
-RickyHuo : huochen1994@163.com, 微信: chodomatte1994
+## Contact Us
+* Mail list: **dev@seatunnel.apache.org**. Mail to `dev-subscribe@seatunnel.apache.org`, follow the reply to subscribe the mail list.
+* Send `Request to join SeaTunnel slack` mail to the mail list(`dev@seatunnel.apache.org`), we will invite you in.
+* [bilibili](https://space.bilibili.com/1542095008)
+- Qutoutiao, Qutoutiao Data Center
-分蛋科技使用seatunnel做数据仓库实时同步,近百个Pipeline同步处理;数据流实时统计,数据平台指标离线计算。
+Qutoutiao Data Center uses SeaTunnel to support mysql to hive offline ETL tasks, real-time hive to clickhouse backfill technical support, and well covers most offline and real-time tasks needs.
-* 其他公司 ... 期待您的加入,请联系微信: garyelephant
+- Yixia Technology, Yizhibo Data Platform
-## 项目Star增长趋势
+- Yonghui Superstores Founders' Alliance-Yonghui Yunchuang Technology, Member E-commerce Data Analysis Platform
-```
-seatunnel已进入高速成长期,如果你支持此项目,请点Star.
-```
+SeaTunnel provides real-time streaming and offline SQL computing of e-commerce user behavior data for Yonghui Life, a new retail brand of Yonghui Yunchuang Technology.
-[](https://starchart.cc/InterestingLab/seatunnel)
+- Shuidichou, Data Platform
+Shuidichou adopts SeaTunnel to do real-time streaming and regular offline batch processing on Yarn, processing 3~4T data volume average daily, and later writing the data to Clickhouse.
-## 贡献观点和代码
+For more use cases, please refer to: https://interestinglab.github.io/seatunnel-docs/#/zh-cn/case_study/
-提交问题和建议:https://github.com/InterestingLab/seatunnel/issues
+## Contribute ideas and code
-贡献代码:https://github.com/InterestingLab/seatunnel/pulls
+Submit issues and advice: https://github.com/InterestingLab/SeaTunnel/issues
-## 开发者
+Contribute code: https://github.com/InterestingLab/SeaTunnel/pulls
-感谢[所有开发者](https://github.com/InterestingLab/seatunnel/graphs/contributors)
+## Developer
-## 联系项目负责人
+Thanks to all developers https://github.com/InterestingLab/SeaTunnel/graphs/contributors
-Garyelephant : garygaowork@gmail.com, 微信: garyelephant
-RickyHuo : huochen1994@163.com, 微信: chodomatte1994
+## Contact Us
+* Mail list: **dev@seatunnel.apache.org**. Mail to `dev-subscribe@seatunnel.apache.org`, follow the reply to subscribe the mail list.
+* Send `Request to join SeaTunnel slack` mail to the mail list(`dev@seatunnel.apache.org`), we will invite you in.
+* [bilibili](https://space.bilibili.com/1542095008)