文件系统的演进过程 #7
Description
想要系统了解文件系统,还是得先从硬盘这个硬件说起
硬盘
机械硬盘
机械硬盘由盘片、主轴、磁头臂组成。无论是否有IO操作,盘片都需要由主轴带动盘片高速旋转,目的是靠磁盘旋转时带动的气流,让磁头在进行IO时能够悬浮在盘片上方。悬浮的目的是为了避免磁头和盘片接触导致磁头与磁盘损坏。它的存储原理就是,数据存储在具有磁性特质的盘片上。
那为什么都说机械硬盘慢,因为机械硬盘在做IO操作时,磁头臂移动到盘片的磁道上,通过磁头读取磁道上的数据。而移动磁头是一个机械动作,需要花费数毫秒时间,因此机械硬盘慢一些。
其实在说机械磁盘慢的时候,必须要考虑IO是顺序还是随机读写,随机读写也就是硬盘数据在硬盘上不连续,那么磁头就需要来回移动,就会花费更长的时间。而顺序读写,说明文件数据连续,比如日志文件,那么磁头就可以减少移动,读写时间就会很短
固态硬盘
固态硬盘由主控芯片、闪存、外置缓存颗粒、PCB板、外壳组成
- 主控芯片:相当于固态硬盘的CPU,控制内部运算
- 闪存:存储内容
- 外置缓存:有些有、有些没有。有的集成在主控中
- SLC缓存:提供固态硬盘爆发速度的技术
- PCB板:类似于主板,用于集成主控、闪存、外置缓存。
- 外壳:铁壳或塑料壳
固态硬盘的物理原理
SLC 闪存有 0 和 1 两种状态,可以表示 1 bit 数据;MLC 闪存有 11、10、01 和 00 等 4 种状态,可以表示 2 bit 数据;TLC 闪存有 111、110、101、100、011、010、001 和 000 等 8 种状态,可以表示 3 bit 数据
闪存颗粒原理很复杂,简单点说就是闪存颗粒如果要数据读写,需要将电子穿过一个类似电容的场,不然电子乱跑,加电压以后电子顺着场做运动穿过电容中间的二氧化硅,然后读写数据。就像一道水闸,加电压水闸降低,水就流过去了
但固态硬盘也是有寿命限制的,闪存单元每次编程或擦除的电子穿越过程都会导致硅氧化物的损耗。这东西本来就只有区区 10 nm 的厚度,每进行一次电子穿越就会变薄一些。也正因为如此,硅氧化物越来越薄,耐用性自然就更差了。SLC 的电压状态最少,可以容忍电压的更大变化,MLC 的 4 种状态也基本可以接受,TLC 的 8 种就太多了,电压可变余地很小。在不清楚确切的所需电压之时,就不得不将同样的电压分成 8 份(SLC 和 MLC 分别只要 2 份和 4 份)。在使用过程中,编程和擦写一个 TLC 闪存单元所需要的时间也越来越长,最终达到严重影响性能、无法接受的地步,闪存区块也就废了。
所以固态硬盘快是因为相比机械硬盘,固态硬盘没有机械操作,全是电子操作,所以就快。
文件系统
文件系统是操作系统的重要组成部分,是操作系统中用于和硬盘进行交互,使得软件得以对硬盘数据进行读写访问的程序。文件系统将硬盘以块(data block)为单位进行划分,每个文件占据若干个块(data block),通过文件控制块(File Control Block, FCB)记录文件占据的硬盘data block。在Linux系统中FCB是inode,想要访问文件,就必须获得文件的inode,然后在inode中查找文件的block索引,定位文件data block,然后才能完成读写。所以,数据存储在硬盘上,文件系统用data block来组织,大小为4KB,用地址来标记,用索引来寻址。inode就是用来记录索引的容器。
inode - 索引节点
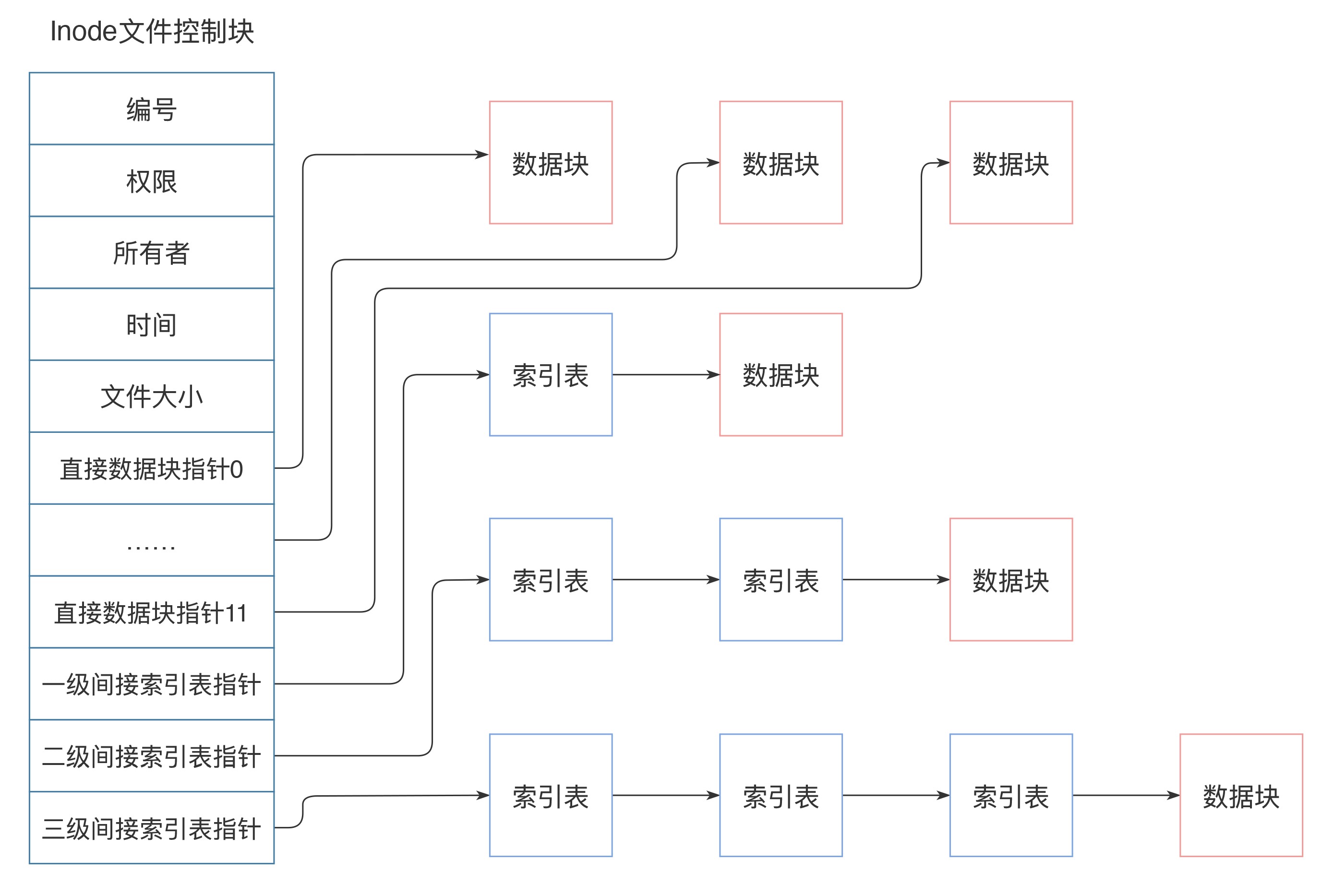
inode分为两部分,用户数据(user data)和元数据(meta data)
meta data:包含inode编号、权限、所有者、文件大小、时间。注意:不包含文件名
user data:在inode中通过索引来组织数据,一共包含15个索引。结构包含:data block地址和索引表,每个索引表可以记录256个索引
- 直接数据块指针:前12个索引(下标为0-11),直接记录数据块地址
- 一级间接索引表指针:第13个索引(下标为12),记录另一个索引表地址,指向另一个索引表。
- 二级间接索引表指针:第14个索引(下标为13),记录二级索引地址
- 三级间接索引表指针:第15个索引(下标为14),记录三级索引地址
inode大小固定,因此1个inode可以寻址的最大文件大小 = 可寻址data block数 * data block大小 = (12 + 256 + 256^2 + 256^3) * 4KB ≈ 64GB
独立硬盘冗余阵列(Redundant Array of Independent Disks, RAID)
RAID是通过硬件RAID卡或软件RAID对多个硬盘进行管理,并统一对外提供服务的技术。
为什么要引入RAID这个技术,主要是因为以下原因:
- 既然文件系统是将数据写入硬盘中的不同data block,那么可以将多个硬盘看作一个整体,这样就可以解决以下问题
- 提高读写速度,解决IO瓶颈:进行数据读写时,对多个硬盘进行并行读写
- 解决存储瓶颈:使用多个硬盘可以存储更多数据
- 提高可用性:对相同数据在不同硬盘写入多份作为备份,其中一个硬盘损坏仍然能保证数据可用
RADI的现有方案
RAID0
将数据分成N片,向N个硬盘并行写入,优点是容量扩大N倍,读写速度扩大N倍。缺点是单个磁盘损坏就会导致文件不可用
RAID1
用两块硬盘互为备份,并行写入。优点是提高可用性,单个硬盘损坏,文件仍可用。缺点是硬盘利用率为50%,资源浪费
RAID10
结合RAID0和RAID1,将现有N个硬盘两两分组,同一组的互为备份,并行写入。优点是容量扩大N/2倍,读写速度扩大N/2倍,可用性提高1倍。缺点是硬盘利用率为50%,资源浪费
RAID5
现有N个硬盘,将数据分为N - 1片,通过对N - 1个数据片做位运算,计算出一片校验数据,将N片数据并行写入N个硬盘。计算校验数据的算法设计上必须要做到:当其中一个数据片丢失时,可以通过校验数据和其他数据片计算出丢失的数据片,进行数据恢复。优点是容量扩大N-1倍,读写速度约扩大N-1倍,硬盘利用率为(N - 1) / N。缺点是需要先根据N - 1个数据片做校验数据片的计算,消耗一定CPU资源和时间
RAID6
思想上和RAID5相同,RAID6除了针对N-1个数据片计算校验数据之外,也对每个data block做计算,产出对应的校验data block,产出的校验data block和原始data block要求不能存储在同一个硬盘上。这有让人想起Kafka主从节点那种存储方式。优点是提供了更高的可用性和数据安全性。缺点是计算时间更长了,CPU资源占用更多了
以上方案中,RAID5是使用最多,但单台服务器可以插入的硬盘数量是有上限的,所以我们说的N个硬盘中的N,一般就是8。一台服务器只能插入8个硬盘,所以在RAID5下,提高的IO性能一般为7

分布式文件系统(Distributed File System)
想要继续突破IO瓶颈、容量瓶颈的思路就是借助分布式系统,将文件存储在不同服务器中。将inode这个FCB变为一个Service,由一个集群来通过服务。将inode中存储的data block地址从硬盘地址变为网络地址,data block的存储也由一个Service来负责,背后也是一个集群。
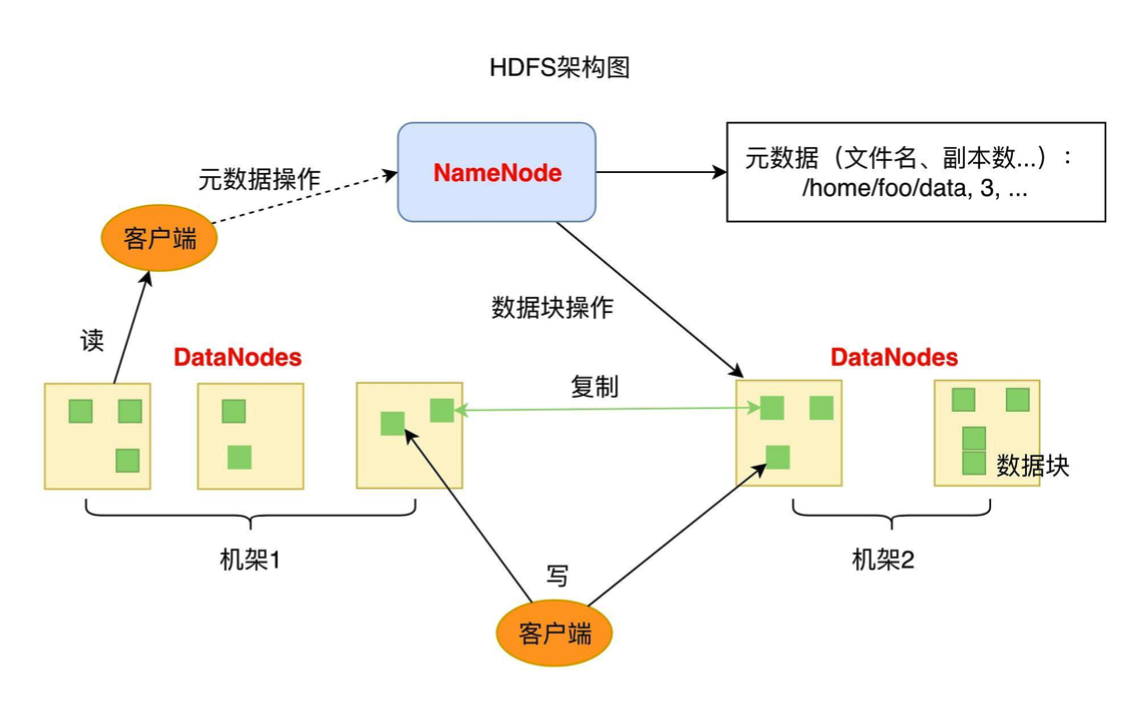
在Hadoop分布式文件系统中,这个服务化的inode称为NameNode,服务化的data block存储角色称为DataNode。对数据的读写需要借助Hadoop Client和HDFS(Hadoop Distributed File System)交互
- DataNode:负责文件数据的存储和读写,HDFS将文件划分为若干个数据块(Block),每个DataNode存储一部分Block。
- NameNode:负责分布式文件系统的元数据(Meta Data)管理,元数据包含文件路径名、访问权限控制、数据块ID、存储位置等。同时负责Block的冗余存储控制(复制为多份,默认为3份)
通过分布式文件系统可以解决:1)IO瓶颈,毕竟IO并发度就可以变为存储对应文件的DataNode个数;2)容量瓶颈,分布式系统本身已经突破了单机的限制,那么最大容量就由集群规模决定了。